Java的序列化
写在前面
本文看下序列化和反序列化相关的内容。
源码 。
1:为什么,什么是序列化和反序列化
Java对象是在jvm的堆中的,而堆其实就是一块内存,如果jvm重启数据将会丢失,当我们希望jvm重启也不要丢失某些对象,或者是需要将某些对象传递到其他服务器(rpc有没有!!!)时就需要使用到序列化和反序列化,因为序列化就是将Java对象转换为文件,而反序列化就是加载文件并生成对象在堆中。
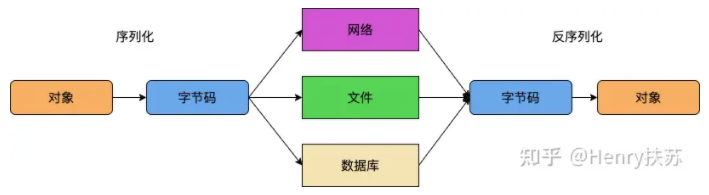
2:Java的序列化和反序列化
Java想要序列化和反序列化,必须实现java.io.Serializable接口,并给变量serialVersionUID赋值,该值用来标识Java类文件的版本。如下序列化和反序列化的例子:
@SneakyThrows
private static void javaDeserialize() {ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream("d:\\test\\xxx.obj"));Student student = (Student) objectInputStream.readObject();System.out.println("java反序列化student完成");System.out.println(student);
}@SneakyThrows
private static void javaSerialize() throws IOException {Student student = new Student();student.setName("张三");student.setAge(99);ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("d:\\test\\xxx.obj"));// 如果没有实现java.io.Serializable接口将会抛出异常java.io.NotSerializableExceptionobjectOutputStream.writeObject(student);objectOutputStream.close();System.out.println("java序列化student完成");
}
java序列化的问题:
1:无法跨平台如Java对象序列化的结果反序列化为python的对象,这样就限制了其不适合某些使用场景,如rpc的场景中就无法使用这种序列化方式,因为rpc需要支持异构的系统
2:序列化的文件大这样占用磁盘大,网络传输速度慢,占用带宽,反序列化的速度也慢,这样就限制了其不适合某些使用场景,如rpc,rpc需要尽量快的序列化和反序列化速度,以提高性能
3:序列化的速度慢还是因为其序列化结果的内容多
以上的问题我们可以使用专门的序列化框架来解决,如hessian。
3:hessian的序列化和反序列化
dubbo 默认使用的是该序列化方式,将来可能会优化成性能更优的序列化方式如kryo,fst等。
hessian支持语言无关的序列化和反序列化,并且速度更快,序列化的结果更小,如下:
private void hessianSerialize() {Student stu = new Student("hessian",1);byte[] obj = serialize(stu);System.out.println("hessian serialize result length = "+obj.length);byte[] obj2 = serialize2(stu);System.out.println("hessian2 serialize result length = "+obj2.length);byte[] other = jdkSerialize(stu);System.out.println("jdk serialize result length = "+other.length);Student student = deserialize2(obj2);System.out.println("deserialize result entity is "+student);
}
具体看文章头源码。
运行结果如下:
hessian serialize result length = 65
hessian2 serialize result length = 59
jdk serialize result length = 101
deserialize result entity is Student(name=hessian, age=1)
可以看到结果的大小jdk序列化<hessian序列化<hessian2序列化,所以如果工作中有这种需求,建议使用hessian2。
4:arvo的序列化和反序列化
使用步骤如下:
1:定义.avsc描述文件
2:通过avro-tool.jar,以.avsc描述文件作为输入生成pojo
3:通过avro.jar的API进行序列化(生成.avro文件)和反序列化
首先我们需要定义IDL,命名为User.avsc:
{"namespace": "dongshi.daddy.seriablize.avro","type": "record","name": "User","fields": [{"name": "name", "type": "string"},{"name": "id", "type": "int"},{"name": "salary", "type": "int"},{"name": "age", "type": "int"},{"name": "address", "type": "string"}]
}
接着通过avro-tools.jar生成pojo,如下:
$ java -jar avro-tools-1.8.2.jar compile schema User.avsc res
Input files to compile:User.avsc
log4j:WARN No appenders could be found for logger (AvroVelocityLogChute).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
然后我们将生成的User.java文件拷贝到classpath的dongshi.daddy.seriablize.avro目录,接着就可以执行序列化和反序列化了,首先执行序列化:
@Test
public void testAvroSerialize() throws Exception {
// 声明并初始化User对象// 方式一User user1 = new User();user1.setName("wqbin");user1.setId(1);user1.setSalary(1000);user1.setAge(20);user1.setAddress("beijing");// 方式二 使用构造函数
// Alternate constructorUser user2 = new User("wang", 2, 1000, 19, "guangzhou");// 方式三,使用Build方式
// Construct via builderUser user3 = User.newBuilder().setName("bin").setId(3).setAge(21).setSalary(2000).setAddress("shenzhen").build();String userDir = System.getProperty("user.dir");System.out.println("userDir is: " + userDir);String path = userDir + "/User.avro"; // avro文件存放目录DatumWriter<User> userDatumWriter = new SpecificDatumWriter<User>(User.class);DataFileWriter<User> dataFileWriter = new DataFileWriter<User>(userDatumWriter);dataFileWriter.create(user1.getSchema(), new File(path));
// 把生成的user对象写入到avro文件dataFileWriter.append(user1);dataFileWriter.append(user2);dataFileWriter.append(user3);dataFileWriter.close();
}
生成文件如下:
接着执行反序列化:
@Test
public void testAvroDeserialize() throws Exception {DatumReader<User> reader = new SpecificDatumReader<User>(User.class);DataFileReader<User> dataFileReader = new DataFileReader<User>(new File(System.getProperty("user.dir") + "/User.avro"), reader);User user = null;while (dataFileReader.hasNext()) {user = dataFileReader.next();System.out.println(user);}
}
输出如下内容则为成功:
{"name": "wqbin", "id": 1, "salary": 1000, "age": 20, "address": "beijing"}
{"name": "wang", "id": 2, "salary": 1000, "age": 19, "address": "guangzhou"}
{"name": "bin", "id": 3, "salary": 2000, "age": 21, "address": "shenzhen"}Process finished with exit code 0
5:kryo的序列化和反序列化
kryo是底层使用了ASM字节码技术,所以其只能使用在基于JVM的语言上,如Java,scala,kotlin等,接下来看下其如何使用。
- 首先引入pom:
<dependency><groupId>com.esotericsoftware</groupId><artifactId>kryo</artifactId><version>5.2.0</version>
</dependency>
- 序列化:
@Test
public void testKrypSerialize() throws Exception {Kryo kryo = new Kryo();kryo.register(SomeClass.class);SomeClass someClass = new SomeClass();someClass.value = "dongshidaddy";Output output = new Output(new FileOutputStream(userDir + "/someCls.bin"));kryo.writeObject(output, someClass);output.close();
}
运行后:
- 反序列化
@Test
public void testKrypDeserialize() throws Exception {Kryo kryo = new Kryo();kryo.register(SomeClass.class);Input input = new Input(new FileInputStream(userDir + "/someCls.bin"));SomeClass someClassFromBin = kryo.readObject(input, SomeClass.class);System.out.println(someClassFromBin.value);
}
运行后:
dongshidaddyProcess finished with exit code 0
6:fst的序列化和反序列化
java的序列化和反序列化方式,性能优秀(jdk原生序列化速度的10倍,序列化结果体积1/3左右),如果有序列化的需求可以考虑使用。看下如何使用。
- 引入pom
<dependency><groupId>de.ruedigermoeller</groupId><artifactId>fst</artifactId><version>2.04</version>
</dependency>
- 序列化和反序列化
// fst序列化和反序列化
@Test
public void testFstSerializeAndDescrialize() {dongshi.daddy.seriablize.fst.User bean = new dongshi.daddy.seriablize.fst.User();bean.setUsername("xxxxx");bean.setPassword("123456");bean.setAge(1000000);byte[] byteBean = configuration.asByteArray(bean);System.out.println("序列化的字节大小是:" + byteBean.length);// 反序列化dongshi.daddy.seriablize.fst.User resultBean = (dongshi.daddy.seriablize.fst.User) configuration.asObject(byteBean);System.out.println("fst反序列化的结果是:" + resultBean);
}
输出如下内容则为成功:
序列化的字节大小是:68
fst反序列化的结果是:User(username=xxxxx, age=1000000, password=123456)Process finished with exit code 0
写在后面
巨人的肩膀
再来认识一下 Java 序列化 。
Hessian序列化实例 。
Avro从入门到入土 。
深入浅出序列化(2)——Kryo序列化 。
Kryo 和 FST 序列化 。