Python爬虫(二十)_动态爬取影评信息
本案例介绍从JavaScript中采集加载的数据。更多内容请参考:Python学习指南
#-*- coding:utf-8 -*-
import requests
import re
import time
import json#数据下载器
class HtmlDownloader(object):def download(self, url, params=None):if url is None:return Noneuser_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:48.0) Gecko/20100101 Firefox/48.0'headers = {'User-Agent':user_agent}if params is None:r = requests.get(url, headers = headers)else:r = requests.get(url, headers = headers, params = params)if r.status_code == 200:r.encoding = 'utf-8'return r.textreturn None#数据存储器
class HtmlParser(object):#从选购电影页面中解析出所有电影信息,组成一个listdef parser_url(self, page_url, response):pattern = re.compile(r'(http://movie.mtime.com/(\d+)/)')urls = pattern.findall(response)if urls != None:#将urls去重return list(set(urls))else:return None#解析正在上映的电影def __parser_release(self, page_url, value):'''解析已经上映的电影:param page_url:电影链接:param value: json数据:return'''try:isRelease = 1movieRating = value.get('value').get('movieRating')boxOffice = value.get('value').get('boxOffice')movieTitle = value.get('value').get('movieTitle')RPictureFinal = movieRating.get('RPictureFinal')RStoryFinal = movieRating.get('RStoryFinal')RDirectorFinal = movieRating.get('RDirectorFinal')ROtherFinal = movieRating.get('ROtherFinal')RatingFinal = movieRating.get('RatingFinal')MovieId = movieRating.get("MovieId")UserCount = movieRating.get("Usercount")AttitudeCount = movieRating.get("AttitudeCount")TotalBoxOffice = boxOffice.get("TotalBoxOffice")TotalBoxOfficeUnit = boxOffice.get("TotalBoxOfficeUnit")TodayBoxOffice = boxOffice.get("TodayBoxOffice")TodayBoxOfficeUnit = boxOffice.get("TodayBoxOfficeUnit")ShowDays = boxOffice.get('ShowDays')try:Rank = boxOffice.get('Rank')except Exception,e:Rank = 0#返回所提取的内容return (MovieId, movieTitle, RatingFinal, ROtherFinal, RPictureFinal, RDirectorFinal, RStoryFinal, UserCount, AttitudeCount, TotalBoxOffice+TotalBoxOfficeUnit, TodayBoxOffice+TodayBoxOfficeUnit, Rank, ShowDays, isRelease)except Exception, e:print e, page_url, valuereturn None#解析未上映的电影def __parser_no_release(self, page_url, value, isRelease=0):'''解析未上映的电影信息:param page_url:param value: return'''try:movieRating = value.get('value').get('movieRating')movieTitle = value.get('value').get('movieTitle')RPictureFinal = movieRating.get('RPictureFinal')RStoryFinal = movieRating.get('RStoryFinal')RDirectorFinal = movieRating.get('RDirectorFinal')ROtherFinal = movieRating.get('ROtherFinal')RatingFinal = movieRating.get('RatingFinal')MovieId = movieRating.get("MovieId")UserCount = movieRating.get("Usercount")AttitudeCount = movieRating.get("AttitudeCount")try:Rank = value.get('value').get('hotValue').get('Ranking')except Exception,e:Rank = 0#返回所提取的内容return (MovieId, movieTitle, RatingFinal, ROtherFinal, RPictureFinal, RDirectorFinal, RStoryFinal, UserCount, AttitudeCount, u'无', u'无', Rank, 0, isRelease)except Exception, e:print e, page_url, valuereturn None#解析电影中的json信息def parser_json(self, page_url, response):"""解析响应:param response:return"""#将"="和";"之间的内容提取出来pattern = re.compile(r'=(.*?);')result = pattern.findall(response)[0]if result != None:#json模块加载字符串value = json.loads(result)# print(result)try:isRelease = value.get('value').get('isRelease')except Exception, e:print ereturn Noneif isRelease:'''isRelease:0 很长时间都不会上映的电影;1 已经上映的电影; 2 即将上映的电影'''if value.get('value').get('hotValue') == None:#解析正在上映的电影# print(self.__parser_release(page_url, value))return self.__parser_release(page_url, value)else:#解析即将上映的电影# print(self.__parser_no_release(page_url, value, isRelease = 2))return self.__parser_no_release(page_url, value, isRelease = 2)else:#解析还有很长时间才能上映的电影return self.__parser_no_release(page_url, value)#数据存储器
#数据存储器将返回的数据插入mysql数据库中,主要包括建表,插入和关闭数据库等操作,表中设置了15个字段,用来存储电影信息,代码如下:
#这里以后补充class SpiderMain(object):def __init__(self):self.downloader = HtmlDownloader()self.parser = HtmlParser()def crawl(self, root_url):content = self.downloader.download(root_url)urls = self.parser.parser_url(root_url, content)#构造一个活的评分和票房链接for url in urls:try:t = time.strftime("%Y%m%d%H%M%S3282", time.localtime())param = {'Ajax_CallBack':'true','Ajax_CallBackType': 'Mtime.Library.Services','Ajax_CallBackMethod': 'GetMovieOverviewRating','Ajax_CallBackArgument0' : '%s'%(url[1]),'Ajax_RequestUrl' : '%s'%(url[0]),'Ajax_CrossDomain' : '1','t' : '%s'%t}rank_url = 'http://service.library.mtime.com/Movie.api?'rank_content = self.downloader.download(rank_url, param)data = self.parser.parser_json(rank_url, rank_content)self.output.output_end()except Exception, e:print("Crawl failed")if __name__ == '__main__':spier = SpiderMain()spier.crawl('http://theater.mtime.com/China_Jiangsu_Province_Nanjing/')
最后
分享一份Python的学习资料,但由于篇幅有限,完整文档可以扫码免费领取!!!

1)Python所有方向的学习路线(新版)
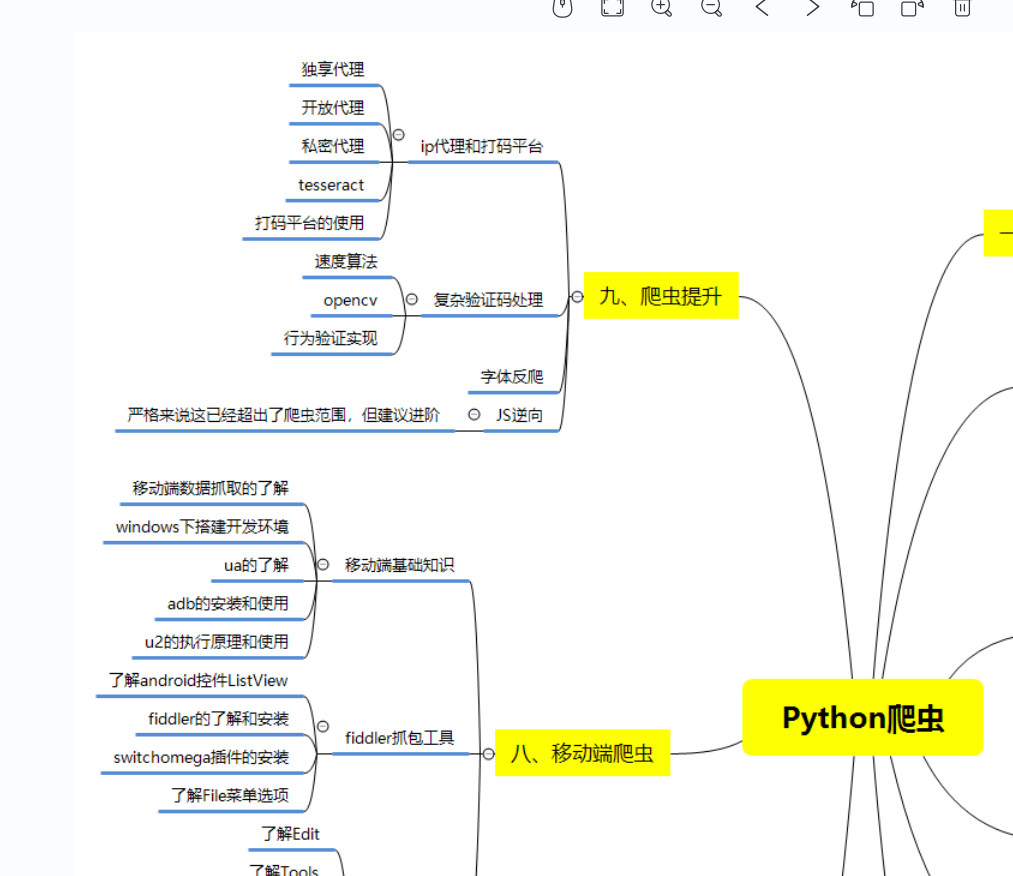
总结的Python爬虫和数据分析等各个方向应该学习的技术栈。

比如说爬虫这一块,很多人以为学了xpath和PyQuery等几个解析库之后就精通的python爬虫,其实路还有很长,比如说移动端爬虫和JS逆向等等。
(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然达不到大佬的程度,但是精通python是没有问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

。