如何描述元素与元素间的逻辑关系?
逻辑结构反映的是数据元素之间的关系,它们与数据元素在计算机中的存储位置无关,是数据结构在用户面前所呈现的形式。根据不同的逻辑结构来分,数据结构可分为集合、线性结构、树形结构和图形结构4种形式,接下来分别进行简要介绍。
1)集合
在集合中,数据元素都属于这个集合,但数据元素之间并没有什么关系。它类似于数学中的集合,如图所示。
集合
2)线性结构
线性结构中的元素具有一对一的关系,通过前一个结点可以找到后一个结点,图1-1的学生信息表就是一个线性结构,数据元素逐个排列。线性结构中前后两个结点互有联系。
线性结构分为顺序存储和链式存储两种。
顺序存储是由一段地址连续的空间来存储元素;链式存储是由分散的单元空间来存储元素,存储单元由指针相连接。简单的线性结构如图所示。

在线性结构中,除头尾结点外,可以通过前一个结点来寻找后一个结点,也可以通过后一个结点来寻找前一个结点。
3)树形结构
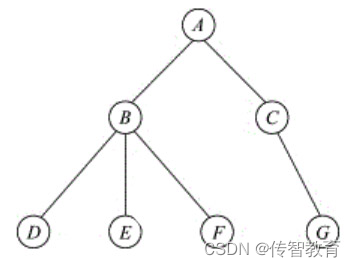
树形结构中,数据元素之间存在一对多的层次关系。图1-4为一棵普通的树。除根结点外,树形结构的每一个结点都必须有一个且只有一个前驱结点,但可以有任意个后继结点。这些数据元素有自顶向下的层次关系。
4)图形结构
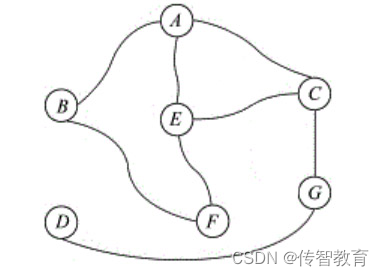
图形结构中的数据元素存在多对多的关系,每个结点的前驱和后继结点都可以是任意个,如图1-5所示。
按照逻辑结构,数据结构可以分为上述4种类型,在后续的深入学习中,本书会逐一详细讲解。
2.存储结构
数据结构除了按照逻辑结构来分,还可以按照存储结构来分。
存储结构反映的是数据元素在计算机中的存储形式,如何在计算机中正确地描述数据元素之间的逻辑关系,才是数据结构的关键与重点。常用的存储结构有顺序存储结构、链式存储结构、索引存储结构和散列表4种,接下来分别进行简要介绍。
1)顺序存储结构
顺序存储结构是把逻辑上相邻的结点存储在地址连续的存储单元里,数据元素之间的关系由存储单元是否相邻来体现。这种存储结构通常用高级语言上的数组来描述,数据的逻辑关系与物理关系是一致的。以数组inta[5]={100,20,3,56,266}为例,其中的元素a[0]~a[4]在逻辑上是连续的,在存储器中的物理地址也是连续的,如图1-6所示。

使用顺序存储结构存储数据时,系统为数据元素分配一段连续的地址空间。顺序存储结构可以提高空间利用率,而且对于随机访问元素,其效率非常高,因为逻辑上相邻的数据元素,其存储地址也是紧邻的,所以可以按元素序号来快速查找到某一个元素。
但也正因如此,如果要对顺序存储结构实现元素的插入和删除,效率则非常低。因为如果要插入一个元素,需要将这个位置之后的所有元素都向后移动一个位置;同样,如果要删除一个元素,需要将这个位置之后的所有元素都向前移动一个位置。
顺序存储结构在使用时有空间限制,当需要存取元素的个数多于预先分配的空间时,会出现“溢出”问题;当元素个数少于预先分配的空间时,又会造成空间浪费。
2)链式存储结构
链式存储结构在空间上是一些不连续的存储单元,这些存储单元的逻辑关系通过附加的指针字段来表示,例如C/C++语言中的指针类型,通过这些指针的指向来表明结点之间的联系。图1-3(b)为链式存储结构的示意图,但在此图中没有标明指针的指向。在链式存储结构中,可以有指向后继元素的指针字段,也可以有指向前驱元素的指针字段,如图1-7和图1-8所示。

这样在插入元素时不必移动任何一个元素,高效简洁。同理,当删除某一个元素时,只需将其前后两个元素连接起来即可,也无须移动其他元素。
但链式存储结构无法进行元素的随机访问。
对链式存储结构而言,空间利用率也较低,因为分配的内存单元有一部分被用来存储结点之间的逻辑关系。但链式存储在存储元素时没有空间限制,顺序存储与链式存储都是按需分配,只是链式存储可以在需要时方便地分配新空间,不会造成空间不足或者浪费。
3)索引存储结构
这种存储结构主要是为了方便查找数据,它通常是在存储结点信息的同时,还建立附加的索引表。索引表中的每一项称为索引项,它由两个字段组成:关键字与地址。其中关键字唯一标识一个结点,地址是指向结点的指针。这种结构类似于人们常用的字典,如图所示。
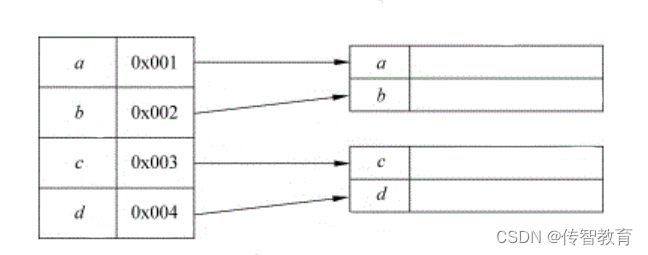
索引存储结构
这种索引表一个索引项对应一个结点,叫作稠密索引。如果索引表中一个索引项对应一组结点,叫作稀疏索引,稀疏索引表如图1-11所示。
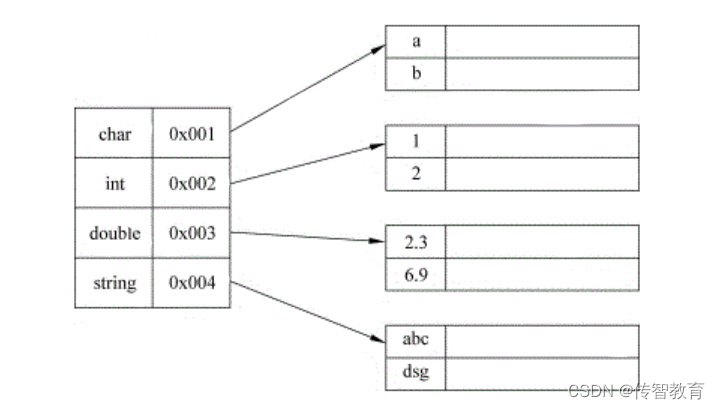
稀疏索引
索引表可以快速地对数据进行随机访问。又因为在进行数据的插入和删除时,只需要更改索引表中的地址值,不必移动结点,所以在数据更改方面也具有较高的效率。但是索引存储结构在建立结点时会额外分配空间来建立一个索引表,因此降低了空间利用率。
4)散列存储结构
散列(hash)存储又称为哈希存储,是一种力图将数据元素的存储位置与关键字之间建立确定对应关系的查找技术。它的基本思想是通过一定的函数关系(散列函数,也称为哈希函数)计算出一个值,将这个值作为元素的存储地址。
散列存储的访问速度是非常迅速的,只要给出相应结点的关键字,它会立即计算出该结点的存储地址。因此它是一种非常重要的存储方法。数据存储的几种方式各有其优点,也各有其用途,不能说哪一种存储结构就比另一种好。在使用时,它们既可以单独使用,也可以组合起来使用,具体要根据操作和实际情况来决定采取哪一种方式,或者哪几种方式结合使用。