一文了解kafka消息队列,实现kafka的生产者(Producer)和消费者(Consumer)的代码,消息的持久化和消息的同步发送和异步发送
文章目录
- 1. kafka的介绍
- 1.2 Kafka适合的应用场景
- 1.2 Kafka的四个核心API
- 2. 代码实现kafka的生产者和消费者
- 2.1 引入加入jar包
- 2.2 生产者代码
- 2.3 消费者代码
- 2.4 介绍kafka生产者和消费者模式
- 3. 消息持久化
- 4. 消息的同步和异步发送
- 5. 参考文档
1. kafka的介绍
最近在学习kafka相关的知识,特将学习成功记录成文章,以供大家共同学习。
Apache Kafka是 一个分布式流处理平台, 这到底意味着什么呢?
-
它可以让你发布和订阅流式的记录。这一方面与消息队列或者企业消息系统类似。
-
它可以储存流式的记录,并且有较好的容错性。
-
它可以在流式记录产生时就进行处理。
1.2 Kafka适合的应用场景
我们首先要了解kafka的一些概念:
-
Kafka作为一个集群,运行在一台或者多台服务器上. -
Kafka通过topic对存储的流数据进行分类。 -
每条记录中包含一个
key,一个value和一个timestamp(时间戳)。
它可以用于两大类别的应用:
-
构造实时流数据管道,它可以在系统或应用之间可靠地获取数据。 (相当
message queue) -
构建实时流式应用程序,对这些流数据进行转换或者影响。 (就是流处理,通过
kafka stream topic和topic之间内部进行变化)
1.2 Kafka的四个核心API
-
The Producer API允许一个应用程序发布一串流式的数据到一个或者多个Kafka topic。 -
The Consumer API允许一个应用程序订阅一个或多个topic,并且对发布给他们的流式数据进行处理。 -
The Streams API允许一个应用程序作为一个流处理器,消费一个或者多个topic产生的输入流,然后生产一个输出流到一个或多个topic中去,在输入输出流中进行有效的转换。 -
The Connector API允许构建并运行可重用的生产者或者消费者,将Kafka topics连接到已存在的应用程序或者数据系统。比如,连接到一个关系型数据库,捕捉表(table)的所有变更内容。
在Kafka中,客户端和服务器使用一个简单、高性能、支持多语言的TCP协议。此协议版本化并且向下兼容老版本, 为Kafka提供了Java客户端,也支持许多其他语言的客户端。
2. 代码实现kafka的生产者和消费者
2.1 引入加入jar包
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka_2.12</artifactId><version>1.0.0</version><scope>provided</scope>
</dependency><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>1.0.0</version>
</dependency><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-streams</artifactId><version>1.0.0</version>
</dependency>
2.2 生产者代码
/*** @author super先生* @date 2023/02/09 11:26*/
public class KafkaProducerDemo extends Thread {/*** 消息发送者*/private final KafkaProducer<Integer, String> producer;/*** topic*/private final String topic;public KafkaProducerDemo(String topic) {//构建相关属性//@see ProducerConfigProperties properties = new Properties();//Kafka 地址properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.220.135:9092,192.168.220.136:9092");//kafka 客户端 Demoproperties.put(ProducerConfig.CLIENT_ID_CONFIG, "KafkaProducerDemo");//The number of acknowledgments the producer requires the leader to have received before considering a request complete. This controls the durability of records that are sent./**发送端消息确认模式:* 0:消息发送给broker后,不需要确认(性能较高,但是会出现数据丢失,而且风险最大,因为当 server 宕机时,数据将会丢失)* 1:只需要获得集群中的 leader节点的确认即可返回* -1/all:需要 ISR 中的所有的 Replica进行确认(集群中的所有节点确认),最安全的,也有可能出现数据丢失(因为 ISR 可能会缩小到仅包含一个 Replica)*/properties.put(ProducerConfig.ACKS_CONFIG, "-1");/**【调优】* batch.size 参数(默认 16kb)* public static final String BATCH_SIZE_CONFIG = "batch.size";** producer对于同一个 分区 来说,会按照 batch.size 的大小进行统一收集进行批量发送,相当于消息并不会立即发送,而是会收集整理大小至 16kb.若将该值设为0,则不会进行批处理*//**【调优】* linger.ms 参数* public static final String LINGER_MS_CONFIG = "linger.ms";* 一个毫秒值。Kafka 默认会把两次请求的时间间隔之内的消息进行搜集。相当于会有一个 delay 操作。比如定义的是1000(1s),消息一秒钟发送5条,那么这 5条消息不会立马发送,而是会有一个 delay操作进行聚合,* delay以后再次批量发送到 broker。默认是 0,就是不延迟(同 TCP Nagle算法),那么 batch.size 也就不生效了*///linger.ms 参数和batch.size 参数只要满足其中一个都会发送/**【调优】* max.request.size 参数(默认是1M) 设置请求最大字节数* public static final String MAX_REQUEST_SIZE_CONFIG = "max.request.size";* 如果设置的过大,发送的性能会受到影响,同时写入接收的性能也会受到影响。*///设置 key的序列化,key 是 Integer类型,使用 IntegerSerializer//org.apache.kafka.common.serializationproperties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.IntegerSerializer");//设置 value 的序列化properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");//构建 kafka Producer,这里 key 是 Integer 类型,Value 是 String 类型producer = new KafkaProducer<Integer, String>(properties);this.topic = topic;}public static void main(String[] args) {new KafkaProducerDemo("test").start();}@Overridepublic void run() {int num = 0;while (num < 100) {String message = "message--->" + num;System.out.println("start to send message 【 " + message + " 】");producer.send(new ProducerRecord<Integer, String>(topic, message));num++;try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}}
}
2.3 消费者代码
/*** @author super先生* @date 2023/02/09 15:26*/
public class KafkaConsumerDemo extends Thread {private final KafkaConsumer<Integer, String> kafkaConsumer;public KafkaConsumerDemo(String topic) {//构建相关属性//@see ConsumerConfigProperties properties = new Properties();properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.220.135:9092,192.168.220.136:9092");//消费组/*** consumer group是kafka提供的可扩展且具有容错性的消费者机制。既然是一个组,那么组内必然可以有多个消费者或消费者实例((consumer instance),它们共享一个公共的ID,即group ID。组内的所有消费者协调在一起来消费订阅主题(subscribed topics)的所有分区(partition)。当然,每个分区只能由同一个消费组内的一个consumer来消费.后面会进一步介绍。*/properties.put(ConsumerConfig.GROUP_ID_CONFIG, "KafkaConsumerDemo");/** auto.offset.reset 参数 从什么时候开始消费* public static final String AUTO_OFFSET_RESET_CONFIG = "auto.offset.reset";** 这个参数是针对新的groupid中的消费者而言的,当有新groupid的消费者来消费指定的topic时,对于该参数的配置,会有不同的语义* auto.offset.reset=latest情况下,新的消费者将会从其他消费者最后消费的offset处开始消费topic下的消息* auto.offset.reset= earliest情况下,新的消费者会从该topic最早的消息开始消费auto.offset.reset=none情况下,新的消费组加入以后,由于之前不存在 offset,则会直接抛出异常。说白了,新的消费组不要设置这个值*///enable.auto.commit//消费者消费消息以后自动提交,只有当消息提交以后,该消息才不会被再次接收到(如果没有 commit,消息可以重复消费,也没有 offset),还可以配合auto.commit.interval.ms控制自动提交的频率。//当然,我们也可以通过consumer.commitSync()的方式实现手动提交properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");/**max.poll.records*此参数设置限制每次调用poll返回的消息数,这样可以更容易的预测每次poll间隔要处理的最大值。通过调整此值,可以减少poll间隔*///间隔时间properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");//反序列化 keyproperties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.IntegerDeserializer");//反序列化 valueproperties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");//构建 KafkaConsumerkafkaConsumer = new KafkaConsumer<>(properties);//设置 topickafkaConsumer.subscribe(Collections.singletonList(topic));}/*** 接收消息*/@Overridepublic void run() {while (true) {//拉取消息ConsumerRecords<Integer, String> consumerRecord = kafkaConsumer.poll(100000000);for (ConsumerRecord<Integer, String> record : consumerRecord) {System.out.println("message receive 【" + record.value() + "】");}}}public static void main(String[] args) {new KafkaConsumerDemo("test").start();}
}
2.4 介绍kafka生产者和消费者模式
如下图所示,分别有三个消费者,属于两个不同的group,那么对于firstTopic这个topic 来说,这两个组的消费者都能同时消费这个topic中的消息,对于此事的架构来说,这个firstTopic就类似于 ActiveMQ中的topic概念。
(组内是竞争的,不同组之间是不竞争的)
Producer产生一个hello消息,group=1 和 group=2都能消费,但是每个组里面只有一个Consumer可以消费。
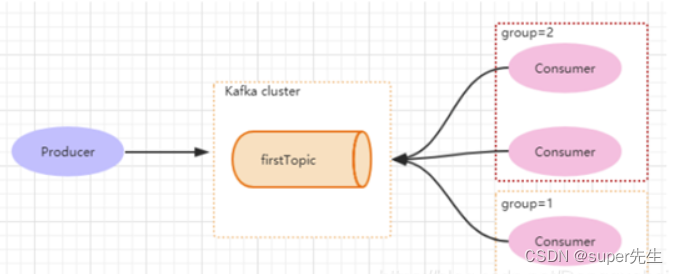
但如果3个消费者都属于同一个group,那么此时firstTopic就是一个Queue的概念。Producer产生一个hello消息,group=1组里面只有一个Consumer可以消费,如下图所示:
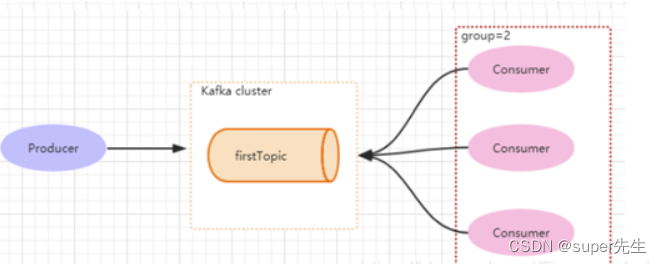
Kafka通过Group就能够实现p2p和发布订阅。一个Group只能消费一次消息。
3. 消息持久化
Kafka的消息都会持久化到磁盘上。
一个Group只能消费一次消息。然后再换一个GroupId,消费者又能够再次消费消息 (只要消息在磁盘上,Kafka默认保存2天)。
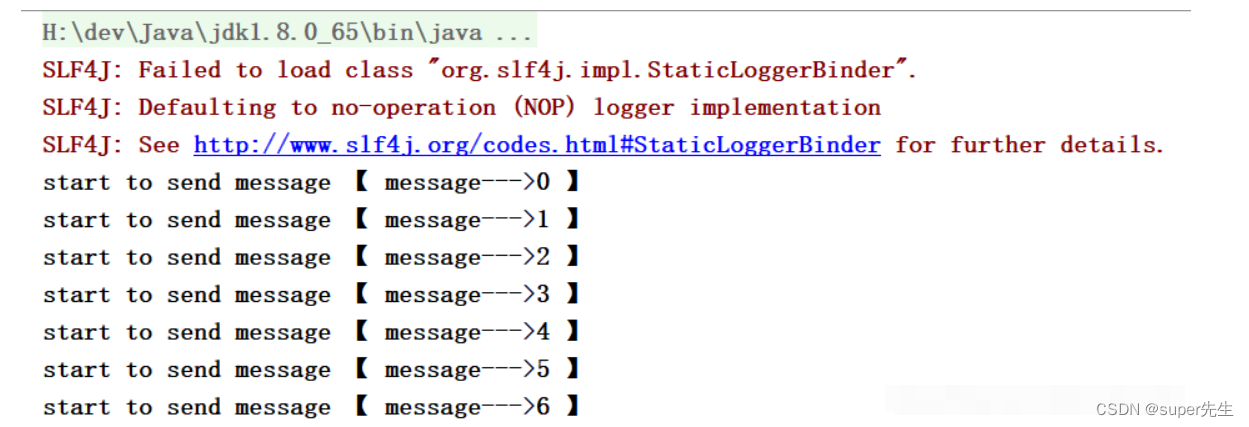
- 启动
Producer:
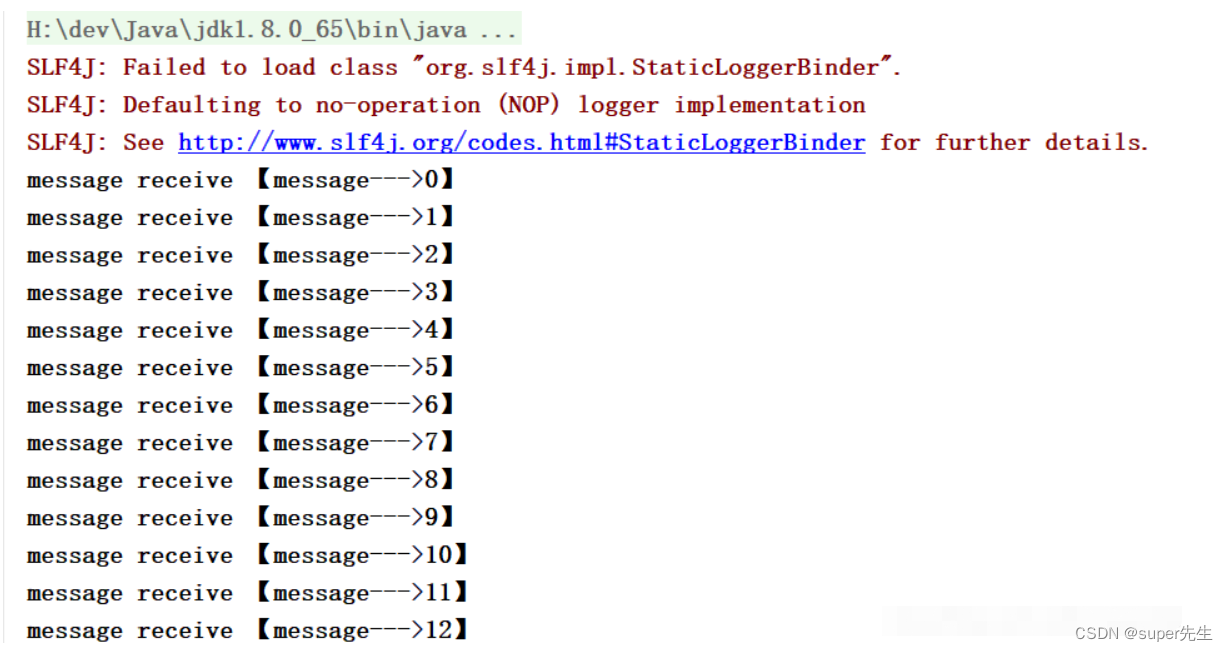
- 启动
Consumer:
4. 消息的同步和异步发送
修改Producer增加异步发送参数,如下代码所示:
/*** @author super先生* @date 2023/02/09 15:00*/
public class KafkaProducerDemo extends Thread {/*** 消息发送者*/private final KafkaProducer<Integer, String> producer;/*** topic*/private final String topic;private final Boolean isAsync;public KafkaProducerDemo(String topic, Boolean isAsync) {this.isAsync = isAsync;//构建相关属性//@see ProducerConfigProperties properties = new Properties();//Kafka 地址properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.220.135:9092,192.168.220.136:9092");//kafka 客户端 Demoproperties.put(ProducerConfig.CLIENT_ID_CONFIG, "KafkaProducerDemo");//The number of acknowledgments the producer requires the leader to have received before considering a request complete. This controls the durability of records that are sent./**发送端消息确认模式:* 0:消息发送给broker后,不需要确认(性能较高,但是会出现数据丢失,而且风险最大,因为当 server 宕机时,数据将会丢失)* 1:只需要获得集群中的 leader节点的确认即可返回* -1/all:需要 ISR 中的所有的 Replica进行确认(集群中的所有节点确认),最安全的,也有可能出现数据丢失(因为 ISR 可能会缩小到仅包含一个 Replica)*/properties.put(ProducerConfig.ACKS_CONFIG, "-1");/**【调优】* batch.size 参数(默认 16kb)* public static final String BATCH_SIZE_CONFIG = "batch.size";** producer对于同一个 分区 来说,会按照 batch.size 的大小进行统一收集进行批量发送,相当于消息并不会立即发送,而是会收集整理大小至 16kb.若将该值设为0,则不会进行批处理*//**【调优】* linger.ms 参数* public static final String LINGER_MS_CONFIG = "linger.ms";* 一个毫秒值。Kafka 默认会把两次请求的时间间隔之内的消息进行搜集。相当于会有一个 delay 操作。比如定义的是1000(1s),消息一秒钟发送5条,那么这 5条消息不会立马发送,而是会有一个 delay操作进行聚合,* delay以后再次批量发送到 broker。默认是 0,就是不延迟(同 TCP Nagle算法),那么 batch.size 也就不生效了*///linger.ms 参数和batch.size 参数只要满足其中一个都会发送/**【调优】* max.request.size 参数(默认是1M) 设置请求最大字节数* public static final String MAX_REQUEST_SIZE_CONFIG = "max.request.size";* 如果设置的过大,发送的性能会受到影响,同时写入接收的性能也会受到影响。*///设置 key的序列化,key 是 Integer类型,使用 IntegerSerializer//org.apache.kafka.common.serializationproperties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.IntegerSerializer");//设置 value 的序列化properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");//构建 kafka Producer,这里 key 是 Integer 类型,Value 是 String 类型producer = new KafkaProducer<Integer, String>(properties);this.topic = topic;}public static void main(String[] args) {new KafkaProducerDemo("test",true).start();}@Overridepublic void run() {int num = 0;while (num < 100) {String message = "message--->" + num;System.out.println("start to send message 【 " + message + " 】");if (isAsync) { //如果是异步发送producer.send(new ProducerRecord<Integer, String>(topic, message), new Callback() {@Overridepublic void onCompletion(RecordMetadata metadata, Exception exception) {if (metadata!=null){System.out.println("async-offset:"+metadata.offset()+"-> partition"+metadata.partition());}}});} else { //同步发送try {RecordMetadata metadata = producer.send(new ProducerRecord<Integer, String>(topic, message)).get();System.out.println("sync-offset:"+metadata.offset()+"-> partition"+metadata.partition());} catch (InterruptedException | ExecutionException e) {e.printStackTrace();}}num++;try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}}
}
在Kafka 1.0 以后,客户端默认发送都是异步发送,简单说就是都是会发到一个队列中,然后在一个线程中不断的从队列中发送数据。
异步发送发送成功后会有一个回调,执行相应的操作。
同步发送也只是基于Future#get而已,相当于是同步获取结果,这个就很好理解了。
5. 参考文档
- https://blog.csdn.net/Dongguabai/article/details/86520617