手写一个摸鱼神器:使用python手写一个看小说的脚本,在ide中输出小说内容,同事直呼“还得是你”
一、准备python环境
windows从0搭建python3开发环境与开发工具
Python爬虫基础(一):urllib库的使用详解
Python爬虫基础(二):使用xpath与jsonpath解析爬取的数据
二、分析小说网的章节目录
最近迷上了《史上最全炼气期》,我们以这一部小说为例:
小说章节列表:http://www.yetianlian.cc/yt4017/
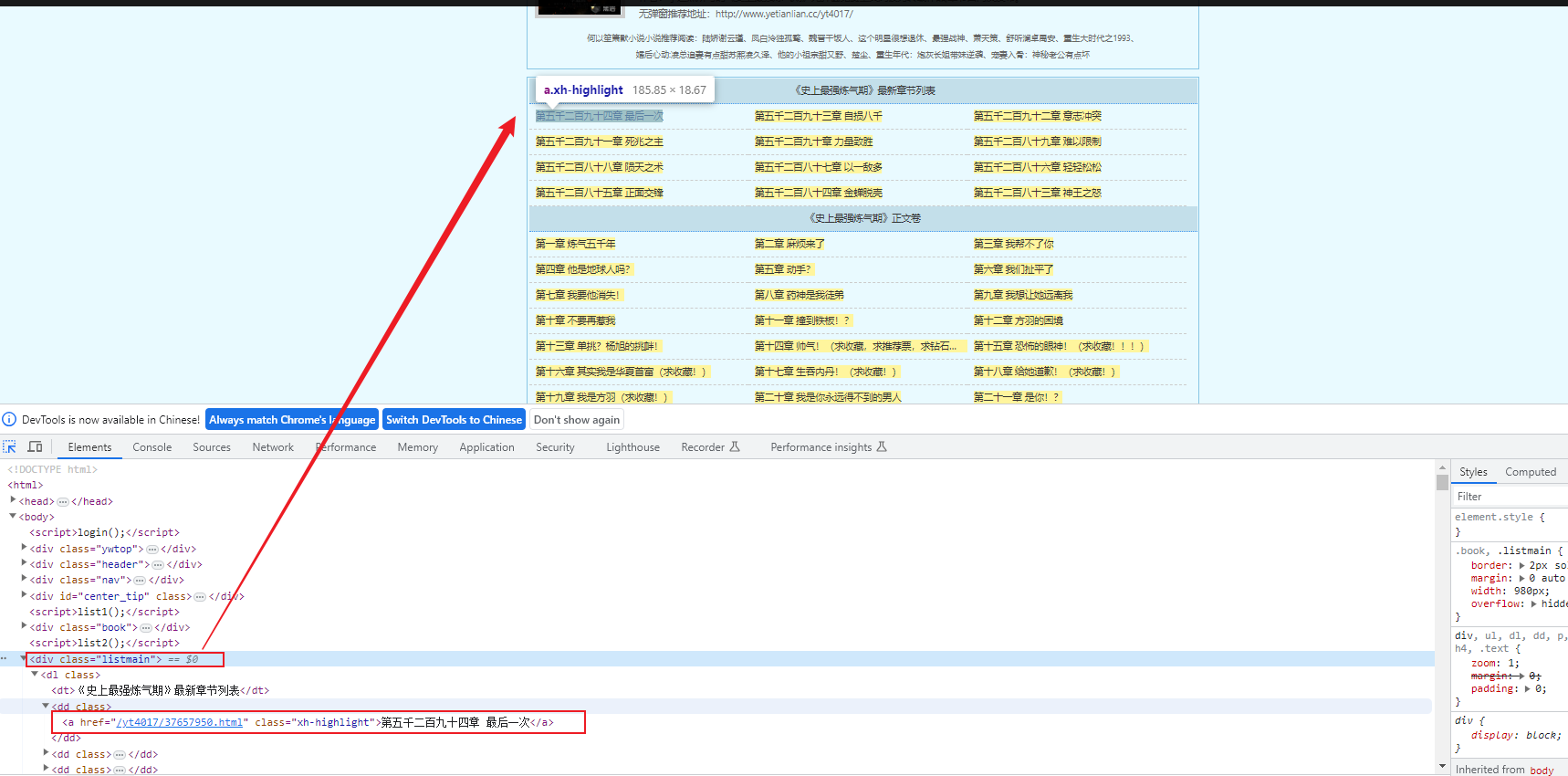
我们可以爬取关键信息:章节名和章节的url,遍历章节名,通过章节的url即可获取每一章的内容!
三、分析小说网的章节内容
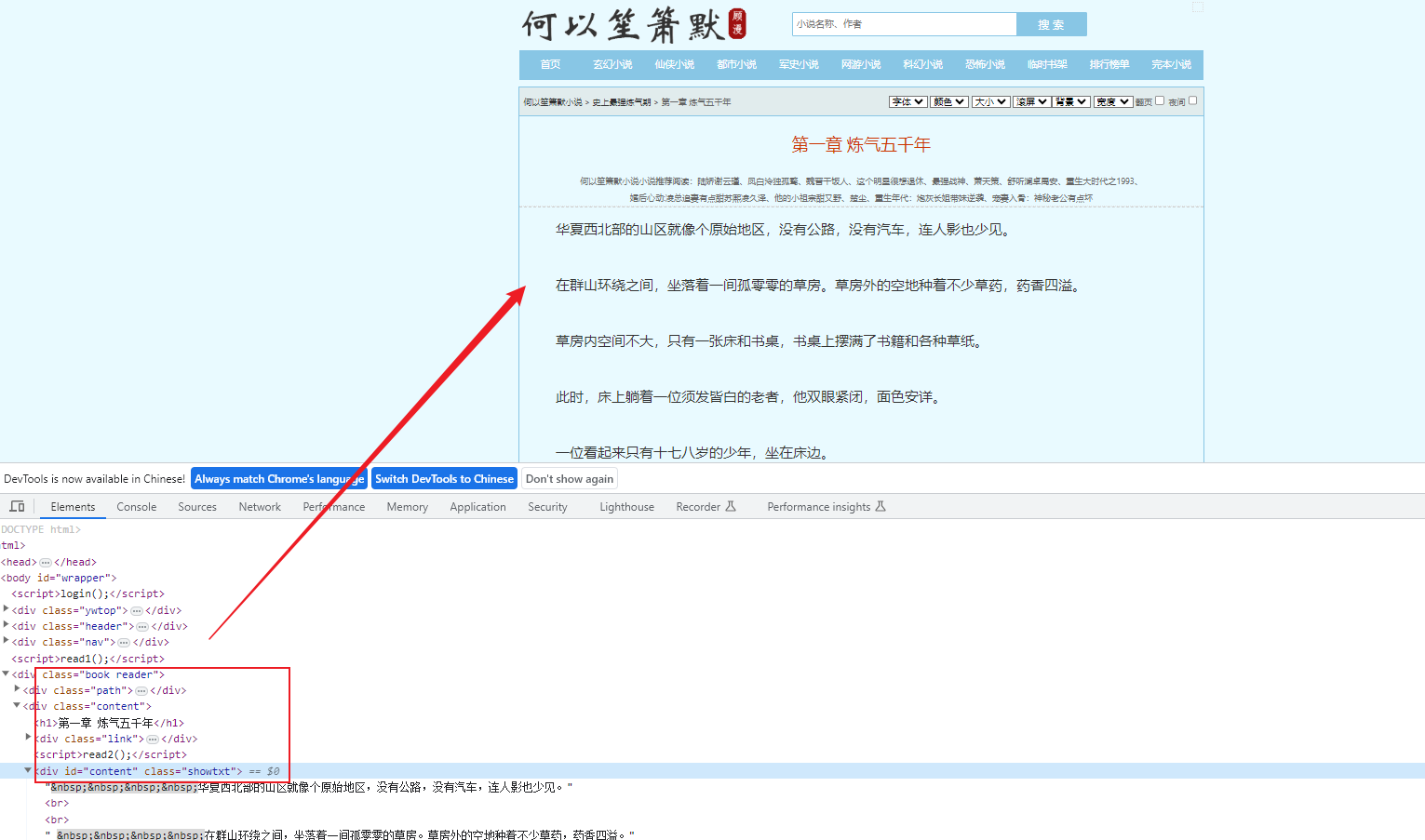
每一章的内容,也可以很轻松的得到。
接下来就是编码了。
四、编写python脚本
import urllib.request
from lxml import etreedef create_request(url):'''构造请求request'''headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',}request = urllib.request.Request(url = url, headers = headers)return requestdef get_content(request):'''得到响应内容'''response = urllib.request.urlopen(request)content = response.read().decode('utf-8')return contentif __name__ == '__main__':# 获取所有章节base_url = 'http://www.yetianlian.cc/yt4017/'request = create_request(base_url) content = get_content(request)base_tree = etree.HTML(content)# 章节名name_list = base_tree.xpath('//div[@class="listmain"]/dl/dd/a/text()')# 章节地址url_list = base_tree.xpath('//div[@class="listmain"]/dl/dd/a/@href')# 定位到从哪一章开始读key = input('请输入要阅读的章节:')begin = 0for i in range(0, len(name_list)-1):if(key in name_list[i]):begin = ifor i in range(begin, len(name_list)-1):input('章节名---------------------->' + name_list[i])# 获取具体哪一章的内容url = 'http://www.yetianlian.cc' + url_list[i]request = create_request(url) content = get_content(request)tree = etree.HTML(content)# 获取小说的内容result = tree.xpath('//div[@id="content"]/text()')# 遍历内容for res in result:input(res)print('-------------->end')
五、验证一下吧
我们随便使用一个ide,在下面打开命令行,执行命令,执行脚本:
python story.py
然后输入要阅读的章节,不断的按回车键,就可以一直刷出内容了!是不是摸鱼神器~
