生成多样、真实的评论(2019 IEEE International Conference on Big Data )
论文题目(Title):Learning to Generate Diverse and Authentic Reviews via an Encoder-Decoder Model with Transformer and GRU
研究问题(Question):评论生成,由上下文+评论->生成评论
研究动机(Motivation):现有的一些研究仅使用用户评论文本生成虚假评论,而另一些研究则利用了语境信息,如评论评分、餐厅名称、城市、州和食品标签。它缺乏将两者结合起来的研究工作。上下文信息有助于产生相关的评论,而评论文本有助于产生不同的评论。因此,将语境信息与已有的评论结合起来,有利于获得既相关又多样的评论。
主要贡献(Contribution):个人觉得创新性不高,主要分为两点:
1. 设计了一个编码器-解码器评论生成模型,该模型结合了Transformer模型和GRU编码器,对来自用户评论和业务上下文的特征进行编码。
2. 提出了一个名为DMet的度量指标来衡量机器生成文本的多样性和新颖性。
研究思路(Idea):选取一条文本描述和其对应的5条评论
第一部分是6层Transformer编码器,其输入是预处理后的上下文和目标分数。Transformer编码器将为上下文的每个标记生成输入嵌入和位置编码,然后通过自注意和多头注意创建上下文的新表示。
第二部分是GRU编码器,由最多5个子编码器组成,按1-5的顺序编号,作为索引号。每个子编码器处理带有输入审查列表Ri中匹配索引号的审查。如果索引数超过了输入评审列表中的评审数,相应的子编码器将无法用于该输入。
研究方法(Method):
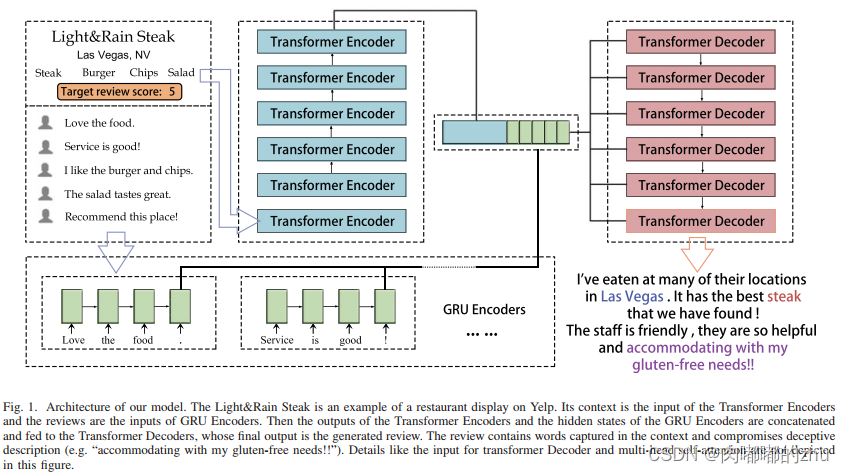
它的上下文是Transformer编码器的输入,而评论是GRU编码器的输入。然后,变压器编码器的输出和GRU编码器的隐藏状态被连接并馈送到变压器解码器,其最终输出是生成的评审。
研究过程(Process):
1.数据集(Dataset):使用Yelp dataset Challenge2提供的数据集
(https://www.yelp.com/dataset/challenge)
Yelp数据集是一个著名的数据集,用于评论生成任务。该数据集包含yelp.com上的企业、评论、用户、图像等信息。数据集中包括18.8万家企业和600万条评论。
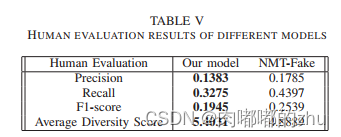
2.评估指标(Evaluation)
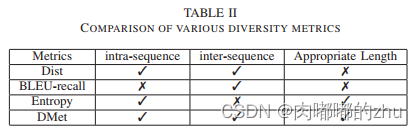
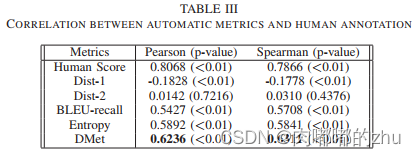
3.实验结果(Result)
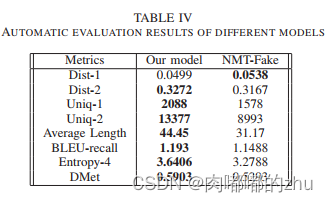
总结(Conclusion):在虚假评论检测中,除了检查评论文本外,任何异常的账户行为都不能遗漏