集合框架和泛型二
一、Set接口
1. Set接口概述
java.util.Set 不包含重复元素的集合、不能保证存储的顺序、只允许有一个 null。
public interface Set<E>
extends Collection<E>
抽象方法,都是继承自 java.util.Collection 接口。
Set 集合的实现类有很多,在此我们重点了解 HashSet 、 TreeSet 、 LinkedHashSet。
不允许使用索引:Set集合中没有提供使用索引来访问元素的方法,因为元素没有固定的顺序。
非同步:不是线程安全的。
HashSet:基于哈希表实现,具有O(1)的平均时间复杂度的查找、插入和删除操作。
TreeSet:基于红黑树实现,具有排序功能,元素会按照自然排序或指定的比较器顺序进行排序。
LinkedHashSet:基于哈希表和链表实现,保留元素的插入顺序,具有O(1)的平均时间复杂度的查找、插入和删除操作。
2.HashSet
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, Serializable
实现了 Set 接口,底层实现是 HashMap 。不保证迭代顺序,允许 null 元素。
- 非线程安全的
- 如果 add 的值已存在( equals 方法返回 true ,基本数据类型自动装箱)返回 false
- 如果 HashSet 中存的是对象,需要重写此对象类中的 equals 和 hashCode() 方法
HashSet集合的特点:
(1)元素唯一性:不允许重复的元素。每个元素只能存在一次。
(2)无序性
(3)基于哈希表
(4)非同步
(5)只能存在一个null元素
| HashSet() | 构造一个新的空集合; 底层实现HashMap实例具有默认初始容量(16)和负载因子(0.75)。 |
|---|---|
| HashSet(Collection<?extends E> c) | 构造一个包含指定集合中的元素的新集合 |
| HashSet(int initialCapacity) | 构造一个新的空集合,默认初始容量(initialCapacity)和负载因子(0.75) |
| HashSet(int initialCapacity, float loadFactor) | 构造一个新的空集合; 底层HashMap实例具有指定的初始容量和指定的负载因子 |
3.TreeSet
public class TreeSet<E>
extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, Serializable
- 非线程安全
- 值必须可比较(元素实现 Comparable 接口、传递 比较器 Comparator 对象)
- 不能存 null
- 判断是否是重复元素,是按照自然比较/比较器进行比较
就是说a.compareTo(b) == 0,如果是 true ,那么 add(a) 之后的 add(b) 将会返回 false ,也就是添加失败。
| ceiling(E e) | E | 返回此集合中大于或等于给定元素的最小元素,如果没有这样的元素,则返回null。 |
|---|---|---|
| floor(E e) | E | 返回此集合中小于或等于给定元素的最大元素,如果没有这样的元素,则返回null。 |
| – | – | – |
| headSet(E toElement) | SortedSet<[E]> | 返回此集合中元素严格小于toElement的部分的视图。 |
| – | – | – |
| tailSet(E fromElement) | SortedSet<[E]> | 返回此集合中元素严格大于或等于fromElement的部分的视图。 |
| – | – | – |
| higher(e) | E | 返回此集合中严格大于给定元素的最小元素,如果没有这样的元素,则返回null |
| – | – | – |
| higher(e) | lower(e) | 返回此集合中严格小于给定元素的最大元素,如果没有这样的元素,则返回null。 |
TreeSet<String> set = new TreeSet(List.of("null", "a", "a", "b", "c", "e", "f",
"g"));
System.out.println(set); // [a, b, c, e, f, g, null]
// 返回此集合中大于或等于给定元素的最小元素,如果没有这样的元素,则返回null。
String ceiling = set.ceiling("d");
System.out.println(ceiling);// e
// 返回当前在此集合中的第一个(最低的)元素。
String first = set.first();
System.out.println(first); // a
// 返回此集合中小于或等于给定元素的最大元素,如果没有这样的元素,则返回null。
String floor = set.floor("d");
System.out.println(floor); // c
// 返回此集合中元素严格小于toElement的部分的视图。
SortedSet<String> headSet = set.headSet("c");
System.out.println(headSet); // a, b
// 返回此集合中严格大于给定元素的最小元素,如果没有这样的元素,则返回null。
String higher = set.higher("c");
System.out.println(higher); // e
// 返回此集合中元素严格大于或等于fromElement的部分的视图。
SortedSet<String> tailSet = set.tailSet("c");
System.out.println(tailSet); // c, e, f, g, null
// 迭代
for (Object obj : set){
System.out.println(obj);
}
4.LinkedHashSet
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable
- 哈希表和双向链表实现的 Set 接口
- 具有可预测的迭代次序(有序)
- 内部实现是 LinkedHashMap ,顺序是插入顺序
二、Iterator接口
1.Iterator接口概述
Iterator接口表示对集合进行迭代的迭代器。Iterator接口为集合而生,专门实现集合的遍历。主要有两个方法:
- hasNext():判断是否存在下一个可以访问的元素,有返回true。
- next():返回要访问的下一个元素。
由Collection接口派生的类或接口,都实现了iterator()方法,iterator()方法返回一个Iterator对象。
2.使用Iterator遍历集合
package collection;import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;/*** 创建一个Map,完成以下操作:* 将我国省份和其简称存到 Map 集合中* 将省份名称中包含"江"的省份从集合中删除* 遍历输出集合元素*/
public class Basic {public static void main(String[] args) {Map<String,String> map=new HashMap();map.put("北京", "京");map.put("上海", "沪");map.put("天津", "津");map.put("重庆", "渝");map.put("河北", "冀");map.put("山西", "晋");map.put("辽宁", "辽");map.put("吉林", "吉");map.put("黑龙江", "黑");map.put("江苏", "苏");map.put("浙江", "浙");map.put("安徽", "皖");map.put("福建", "闽");map.put("江西", "赣");map.put("山东", "鲁");map.put("河南", "豫");map.put("湖北", "鄂");map.put("湖南", "湘");map.put("广东", "粤");map.put("海南", "琼");map.put("四川", "川");map.put("贵州", "黔");map.put("云南", "滇");map.put("陕西", "陕");map.put("甘肃", "甘");map.put("青海", "青");map.put("台湾", "台");map.put("内蒙古", "蒙");map.put("广西", "桂");map.put("西藏", "藏");map.put("宁夏", "宁");map.put("新疆", "新");map.put("香港", "港");map.put("澳门", "澳");System.out.println(map.size());//将省份名称中包含"江"的省份从集合中删除Set<Map.Entry<String, String>> entries = map.entrySet();Iterator<Map.Entry<String, String>> iterator = entries.iterator();while (iterator.hasNext()){Map.Entry<String, String> next = iterator.next();if (next.getKey().contains("江")){iterator.remove();}}//遍历for (String key:map.keySet()) {System.out.println(key);}System.out.println(map.size());}
}三、Map接口
Map 接口不是 Collection 的子接口,使用键、值映射表来存储。
public interface Map<K,V>
- Map 不能有重复的键(覆盖),每个键可以映射到最多一个值
- 允许将映射内容视为一组键、值集合或键值映射集合
- key 不要求有序,不可以重复。 value 也不要求有序,但可以重复
- 当使用对象作为 key 时,要重写 equals 和 hashCode 方法
`JDK9` 提供了创建不可修改 Map 对象的方法:
1. Map.of
2. Map.ofEntries
3. Map.copyOf
Map 的实现类较多,在此我们关注 HashMap 、 TreeMap 、 HashTable 、 LinkedHashMap
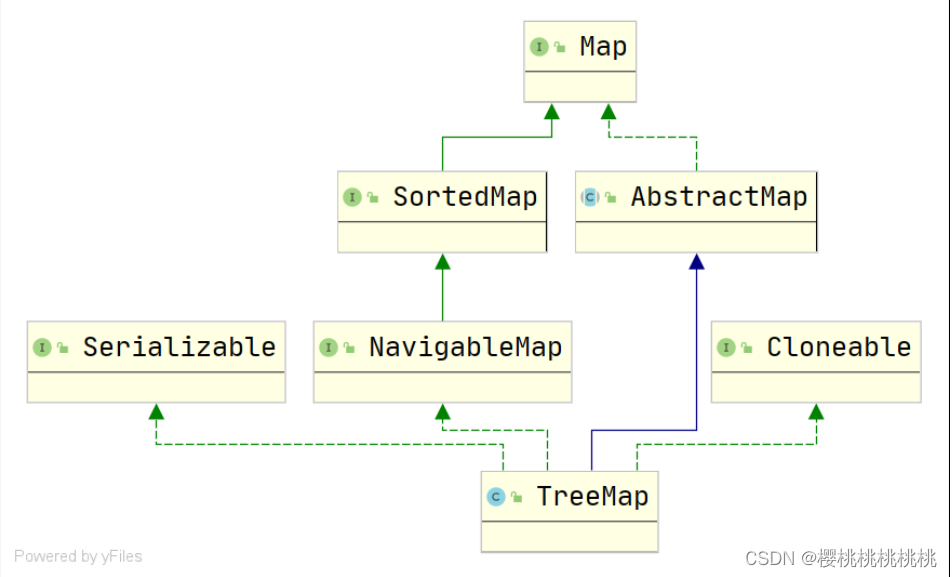
1.TreeMap
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, Serializable
- 继承
AbstractMap,一个红黑树基于NavigableMap实现 - 非线程安全的
key不能存null,但是value可以存nullkey必须是可比较的 (实现Comparable接口,传递一个Comparator比较器)
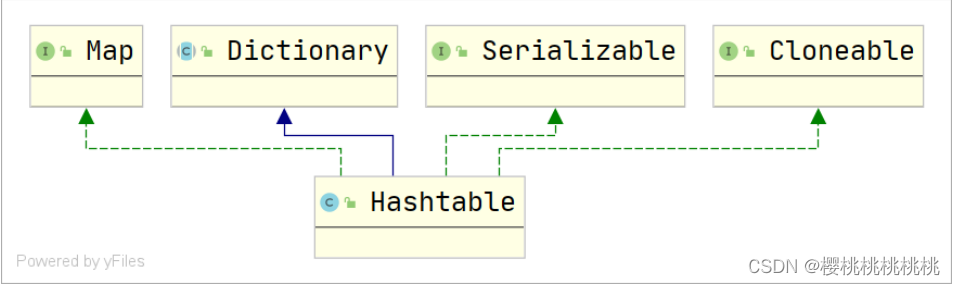
2.HashTable
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, Serializable
- 该类实现了一个哈希表,它将键映射到值
- 不允许 null 作为键和值
- 默认初始容量( initialCapacity )为 11 ,默认负载因子( loadFactor )为 0.75f
- 同步的(线程安全的)
- 不保证顺序
- 扩容方式是旧容量的2倍 +1
- 为什么hashtable的扩容方式选择为2n+1
- 为了均匀分布,降低冲突率 - 数组 + 链表方式存储实现Hash表存储
- 添加值时
- 如果 hash 一样 equals 为 false 则将当前值添加到链表头
- 如果 hash 一样 equals 为 true 则使用当前值替换原来的值 ( key 相同
public synchronized V put(K key, V value) {
// 值不能为 null
if (value == null) {
throw new NullPointerException();
}
// 确认 key 不在 hashtable 中存在
Entry<?,?> tab[] = table;
// 计算 key 的 hash
int hash = key.hashCode();
// 找 key 应在存放在 数组中的位置
int index = (hash & 0x7FFFFFFF) % tab.length;
// index 位置的元素的 key 和 当前的 key 不一样
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
// 判断 key 是否相同
if ((entry.hash == hash) && entry.key.equals(key)) {
// 当 key 一样时,替换值
V old = entry.value;
entry.value = value;
return old;
}
}
// 当 key 在 hashtable 中不存在时,添加
addEntry(hash, key, value, index);
return null;
}
private void addEntry(int hash, K key, V value, int index) {
Entry<?,?> tab[] = table;
// 判断是否需要 "扩容"
if (count >= threshold) {
// 对数组进行扩容 (2n + 1),将原有元素重新计算 hash
rehash();
tab = table;
// 将当前的 key 也重新计算 hash
hash = key.hashCode();
index = (hash & 0x7FFFFFFF) % tab.length;
}
// 原来数组中的 entry 对象
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>) tab[index];
// 创建一个 新的 entry 对象, 放到 数组中
tab[index] = new Entry<>(hash, key, value, e);
// 元素个数 +1
count++;
// 修改次数 +1
modCount++;
}