使用Python操作CSV文件,方便又快捷

概念
CSV是逗号分隔值或者字符分割值,其文件以纯文本形式存储表格数据。
CSV文件可以用文本文件或者转换成EXCEL(直接用EXCEL也可以,但是可能会有一些问题)打开。因此更适合通过CSV文件进行程序之间转移表格数据。
应用场景
需要进行取数分析(将数据库数据拉取下来给产品)、保存爬虫数据时,借助CSV文件更便利一些,同时也可以用该文件记录脚本的操作日志。
具体操作
下面演示如何通过Python进行CSV文件的读写操作。
import csvwith open('test.csv', 'w') as f:writer = csv.writer(f)writer.writerow(['id', 'name', 'phone'])writer.writerow(['01', 'zhangsan', '13600000001'])writer.writerow(['02', 'lisi', '13600000002'])writer.writerow(['03', 'wangwu', '13600000003'])
用记事本打开可以看到如下内容,默认每行数据之间是通过逗号隔开的(可以再理解一下这个Comma-Separated Values)。
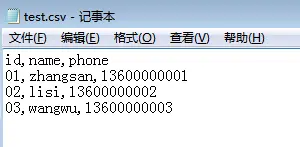
用EXCEL打开的话,数据长这样:
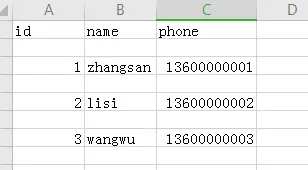
让我们把每行下面的空格去掉,加上newline参数:
import csvwith open('test.csv', 'w', newline='') as f:writer = csv.writer(f)writer.writerow(['id', 'name', 'phone'])writer.writerow(['01', 'zhangsan', '13600000001'])writer.writerow(['02', 'lisi', '13600000002'])writer.writerow(['03', 'wangwu', '13600000003'])
看,空格没有了!
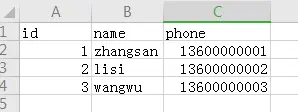
如果想用其它符号代替数据间的逗号,设置delimiter参数:
import csvwith open('test.csv', 'w') as f:writer = csv.writer(f, delimiter = '-')writer.writerow(['id', 'name', 'phone'])writer.writerow(['01', 'zhangsan', '13600000001'])writer.writerow(['02', 'lisi', '13600000002'])writer.writerow(['03', 'wangwu', '13600000003'])
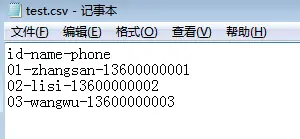
还有一种实现方式,先写入表头,再用writerows插入数据:
import csvwith open('test.csv', 'w') as f:writer = csv.writer(f)writer.writerow(['id', 'name', 'phone'])writer.writerows([['01', 'zhangsan', '13600000004'],['02', 'lisi', '13600000005'],['03', 'wangwu', '13600000006']])
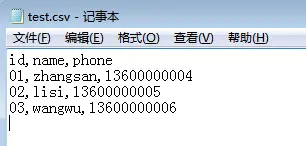
或者将表头抽离出来,通过字典的方式写入:
with open('test.csv', 'w') as f:header = ['id', 'name', 'phone']writer = csv.DictWriter(f, fieldnames=header)writer.writeheader()writer.writerow({'id': '01', 'name': 'zhangsan', 'phone': '13600000007'})writer.writerow({'id': '02', 'name': 'lisi', 'phone': '13600000008'})writer.writerow({'id': '03', 'name': 'wangwu', 'phone': '13600000009'})
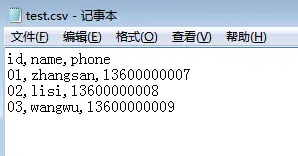
还可以用for循环将数据依次写入:
import csv
data = [("zhangsan",'13600000001'),("lisi",'13600000002'),("wangwu",'13600000003')
]
with open('test.csv','w') as f:writer = csv.writer(f)for i in data:writer.writerow(i)
如果需要写入中文数据,为了避免编码错误,文件操作时加上编码格式:
import csvwith open('test.csv', 'w', encoding='utf-8') as f:writer = csv.writer(f)writer.writerow(['id', 'name', 'phone'])writer.writerow(['01', '张三', '13600000001'])writer.writerow(['02', '李四', '13600000002'])writer.writerow(['03', '王五', '13600000003'])
文件读取操作:
import csv
with open('test.csv','r',encoding = 'utf-8') as f:reader = csv.reader(f)for row in reader:print(row)

最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:

这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!