PaddleOCR学习笔记2-初步识别服务
今天初步实现了网页,上传图片,识别显示结果到页面的服务。后续再完善。
采用flask + paddleocr+ bootstrap快速搭建OCR识别服务。
代码结构如下:

模板页面代码文件如下:
upload.html :
<!DOCTYPE html>
<html>
<meta charset="utf-8">
<head><title>PandaCodeOCR</title><!--静态加载 样式--><link rel="stylesheet" href={{ url_for('static',filename='bootstrap3/css/bootstrap.min.css') }}></link><style>body {font-family: Arial, sans-serif;margin: 0;padding: 0;}.header {background-color: #f0f0f0;text-align: center;padding: 20px;}.title {font-size: 32px;margin-bottom: 10px;}.menu {list-style-type: none;margin: 0;padding: 0;overflow: hidden;background-color: #FFDEAD;border: 2px solid #DCDCDC;}.menu li {float: left;font-size: 24px;}.menu li a {display: block;color: #333;text-align: center;padding: 14px 16px;text-decoration: none;}.menu li a:hover {background-color: #ddd;}.content {padding: 20px;border: 2px solid blue;}</style>
</head>
<body><div class="header"><div class="title">PandaCodeOCR</div></div><ul class="menu"><li><a href="http://localhost:5000/uploader">通用文本识别</a></li></ul><div class="content"><!--上传图片文件--><div id="upload_file"><form action="http://localhost:5000/uploader" method="POST" enctype="multipart/form-data"><div class="form-group"><input type="file" class="form-control" id="upload_file" name="upload_file" placeholder="upload_file"></div><div class="form-group"><button type="submit" class="form-control btn-primary">上传图片文件</button></div></form></div></div>
</body>
</html>result.html :
<!DOCTYPE html>
<html>
<meta charset="utf-8">
<head><title>结果</title><!--静态加载 样式--><link rel="stylesheet" href={{ url_for('static',filename='bootstrap3/css/bootstrap.min.css') }}></link><style>body {font-family: Arial, sans-serif;margin: 0;padding: 0;}.header {background-color: #f0f0f0;text-align: center;padding: 20px;}.title {font-size: 32px;margin-bottom: 10px;}.menu {list-style-type: none;margin: 0;padding: 0;overflow: hidden;background-color: #FFDEAD;border: 2px solid #DCDCDC;}.menu li {float: left;font-size: 24px;}.menu li a {display: block;color: #333;text-align: center;padding: 14px 16px;text-decoration: none;}.menu li a:hover {background-color: #ddd;}</style>
</head>
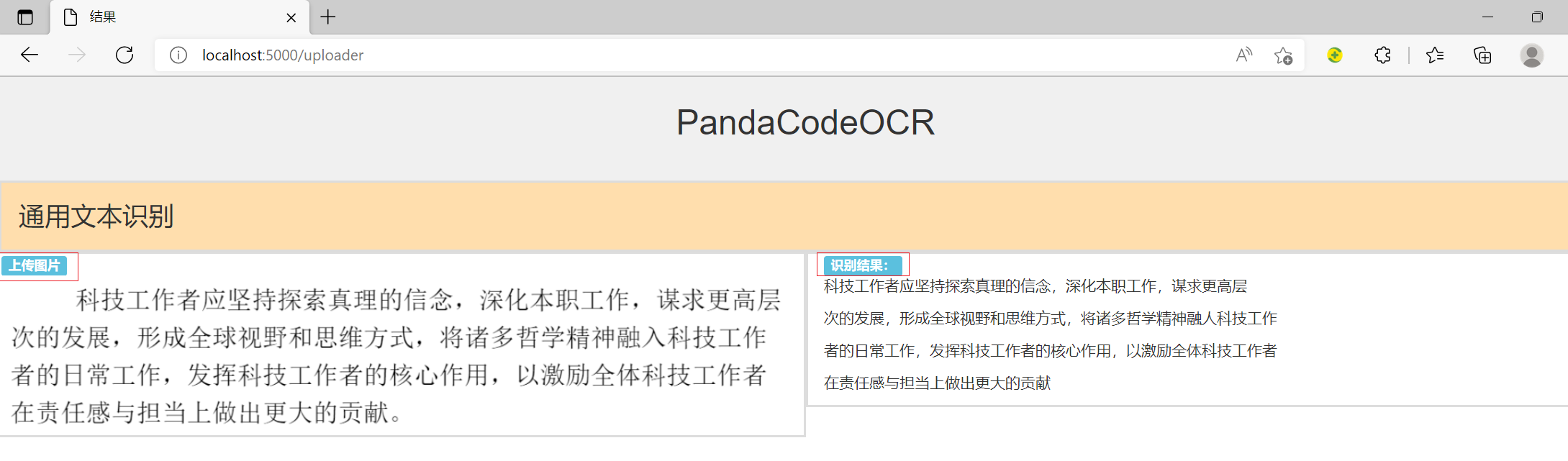
<body><div class="header"><div class="title">PandaCodeOCR</div></div><ul class="menu"><li><a href="http://localhost:5000/uploader">通用文本识别</a></li></ul><div class="row"><!--显示上传的图片--><div class="col-md-6" style="border: 2px solid #ddd;"><span class="label label-info">上传图片</span><!--静态加载 图片--><img src="{{ url_for('static', filename = result_dict['filename'])}}" alt="show_img" class="img-responsive"></div><div class="col-md-6" style="border: 2px solid #ddd;"><!--显示识别结果JSON报文列表--><span class="label label-info">识别结果:</span>{% for line_str in result_dict['result'] %}<p class="text-left">{{ line_str['text'] }}</p>{% endfor %}</div></div>
</body>
</html>
<!--静态加载 script-->
<script src={{ url_for('static',filename='jquery1.3.3/jquery.min.js')}}></script>主要视图代码文件如下:
views.py :
import json
import os
import timefrom . import blue_task
from flask import Flask, render_template, requestfrom paddleocr import PaddleOCR
from PIL import Image,ImageDraw
import numpy as np'''
自定义模型测试ocr方法
'''def test_model_ocr(img):# 返回字典结果对象result_dict = {'result': []}# paddleocr 目前支持的多语言语种可以通过修改lang参数进行切换# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`# 使用CPU预加载,不用GPU# 模型路径下必须包含model和params文件,目前开源的v3版本模型 已经是识别率很高的了# 还要更好的就要自己训练模型了。ocr = PaddleOCR(det_model_dir='./inference/ch_PP-OCRv3_det_infer/',rec_model_dir='./inference/ch_PP-OCRv3_rec_infer/',cls_model_dir='./inference/ch_ppocr_mobile_v2.0_cls_infer/',use_angle_cls=True, lang="ch", use_gpu=False)# 识别图片文件result0 = ocr.ocr(img, cls=True)result = result0[0]for index in range(len(result)):line = result[index]tmp_dict = {}points = line[0]text = line[1][0]score = line[1][1]tmp_dict['points'] = pointstmp_dict['text'] = texttmp_dict['score'] = scoreresult_dict['result'].append(tmp_dict)return result_dict# 转换图片
def convert_image(image, threshold=None):# 阈值 控制二值化程度,不能超过256,[200, 256]# 适当调大阈值,可以提高文本识别率,经过测试有效。if threshold is None:threshold = 200print('threshold : ', threshold)# 首先进行图片灰度处理image = image.convert("L")pixels = image.load()# 在进行二值化for x in range(image.width):for y in range(image.height):if pixels[x, y] > threshold:pixels[x, y] = 255else:pixels[x, y] = 0return image@blue_task.route('/upload')
def upload_file():return render_template('upload.html')@blue_task.route('/uploader', methods=['GET', 'POST'])
def uploader():if request.method == 'POST':#每个上传的文件首先会保存在服务器上的临时位置,然后将其实际保存到它的最终位置。filedata = request.files['upload_file']upload_filename = filedata.filenameprint(upload_filename)#保存文件到指定路径#目标文件的名称可以是硬编码的,也可以从 request.files[file] 对象的 filename 属性中获取。#但是,建议使用 secure_filename() 函数获取它的安全版本img_path = os.path.join('upload/', upload_filename)filedata.save(img_path)print('file uploaded successfully')start = time.time()print('=======开始OCR识别======')# 打开图片img1 = Image.open(img_path)# 转换图片, 识别图片文本# print('转换图片,阈值=220时,再转换为ndarray数组, 识别图片文本')# 转换图片img2 = convert_image(img1, 220)# Image图像转换为ndarray数组img_2 = np.array(img2)# 识别图片result_dict = test_model_ocr(img_2)# 识别时间end = time.time()recognize_time = int((end - start) * 1000)result_dict["filename"] = img_pathresult_dict["recognize_time"] = str(recognize_time)result_dict["error_code"] = "000000"result_dict["error_msg"] = "识别成功"# return json.dumps(result_dict, ensure_ascii=False), {'Content-Type': 'application/json'}# render_template方法:渲染模板# 参数1: 模板名称 参数n: 传到模板里的数据return render_template('result.html', result_dict=result_dict)else:return render_template('upload.html')启动flask应用,测试结果如下: