【100天精通Python】Day57:Python 数据分析_Pandas数据描述性统计,分组聚合,数据透视表和相关性分析
目录
1 描述性统计(Descriptive Statistics)
2 数据分组和聚合
3 数据透视表
4 相关性分析
1 描述性统计(Descriptive Statistics)
描述性统计是一种用于汇总和理解数据集的方法,它提供了关于数据分布、集中趋势和离散度的信息。Pandas 提供了 describe() 方法,它可以生成各种描述性统计信息,包括均值、标准差、最小值、最大值、四分位数等。以下是详细的描述性统计示例:
首先,假设你有一个包含一些学生考试成绩的 DataFrame:
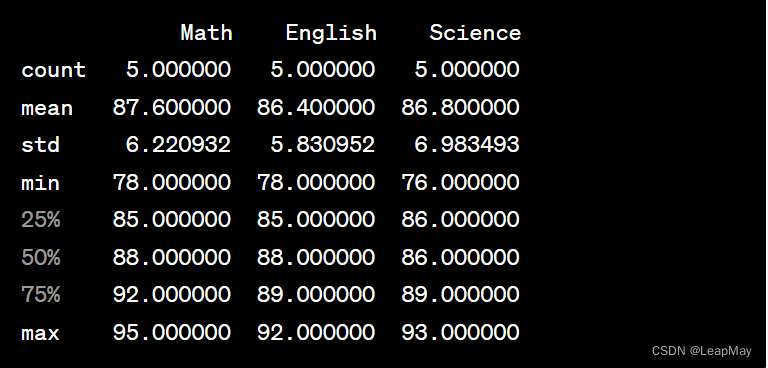
import pandas as pddata = {'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eva'],'Math': [85, 92, 78, 88, 95],'English': [78, 85, 89, 92, 88],'Science': [90, 86, 76, 93, 89]}df = pd.DataFrame(data)# 使用 describe() 方法生成描述性统计信息
description = df.describe()# 输出结果
print(description)输出结果将会是:
2 数据分组和聚合
数据分组和聚合是数据分析中常用的操作,用于根据某些特征将数据分组,并对每个分组应用聚合函数,以便获得有关每个组的统计信息。在 Pandas 中,你可以使用 groupby() 方法来实现数据分组,然后使用各种聚合函数对分组后的数据进行计算。以下是详细的示例和解释:
假设你有一个包含不同城市销售数据的 DataFrame:
import pandas as pddata = {'City': ['New York', 'Los Angeles', 'Chicago', 'New York', 'Chicago', 'Los Angeles'],'Sales': [1000, 750, 800, 1200, 900, 850]}df = pd.DataFrame(data)# 使用 groupby() 方法按城市分组
grouped = df.groupby('City')# 对每个组应用聚合函数(例如,计算平均销售额)
result = grouped['Sales'].mean()# 输出结果
print(result)使用 groupby() 方法将数据按城市分组,并对每个城市的销售数据进行聚合:
输出结果:

在这个示例中,我们首先使用
groupby()方法按城市分组,然后对每个城市的销售数据应用了mean()聚合函数。结果中包含了每个城市的平均销售额。
你还可以应用其他聚合函数,如 sum()、max()、min() 等,以获取更多信息。例如,你可以计算每个城市的总销售额:
total_sales = grouped['Sales'].sum()
除了单个聚合函数外,你还可以同时应用多个聚合函数,并将结果合并到一个 DataFrame 中。这可以通过 agg() 方法来实现:
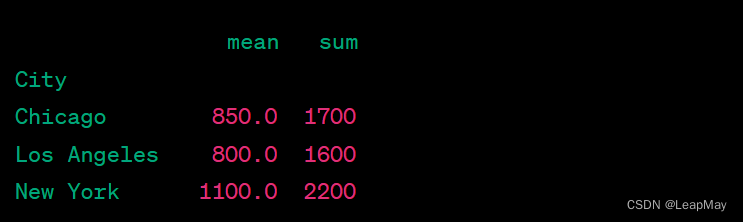
import pandas as pddata = {'City': ['New York', 'Los Angeles', 'Chicago', 'New York', 'Chicago', 'Los Angeles'],'Sales': [1000, 750, 800, 1200, 900, 850]}df = pd.DataFrame(data)# 使用 groupby() 方法按城市分组
grouped = df.groupby('City')# 同时计算平均销售额和总销售额,并将结果合并到一个 DataFrame 中
result = grouped['Sales'].agg(['mean', 'sum'])# 输出结果
print(result)
输出结果:
3 数据透视表
数据透视表是一种用于对数据进行多维度汇总和分析的工具。在 Pandas 中,你可以使用 pivot_table() 函数来创建数据透视表。下面是一个详细的数据透视表示例:
假设你有一个包含销售数据的 DataFrame:
import pandas as pddata = {'Date': ['2023-09-01', '2023-09-01', '2023-09-02', '2023-09-02', '2023-09-03'],'Product': ['A', 'B', 'A', 'B', 'A'],'Sales': [1000, 750, 1200, 800, 900]}df = pd.DataFrame(data)
现在,假设你想要创建一个数据透视表,以便查看每个产品每天的总销售额。你可以使用 pivot_table() 来实现这个目标:
# 创建数据透视表,以Date为行索引,Product为列,计算总销售额
pivot = df.pivot_table(index='Date', columns='Product', values='Sales', aggfunc='sum')# 输出结果
print(pivot)
输出结果:

在这个示例中,我们使用了
pivot_table()函数,将 "Date" 列作为行索引,"Product" 列作为列,并计算了每个组合的销售额之和。结果是一个数据透视表,它以日期为行,以产品为列,每个单元格中包含了对应日期和产品的销售额。如果某个日期没有某个产品的销售数据,相应的单元格将显示为 NaN(Not a Number)。你还可以在
aggfunc参数中指定其他聚合函数,例如 'mean'、'max'、'min' 等,以根据你的需求生成不同类型的数据透视表。
4 相关性分析
相关性分析是用来确定两个或多个变量之间关系的统计方法,通常用于了解它们之间的相关程度和方向。在 Pandas 中,你可以使用 corr() 方法来计算相关性系数(如 Pearson 相关系数)来衡量两个数值列之间的相关性。以下是相关性分析的详细示例和解释:
假设你有一个包含两个数值列的 DataFrame,表示学生的数学和英语成绩:
import pandas as pddata = {'Math': [85, 92, 78, 88, 95],'English': [78, 85, 89, 92, 88]}df = pd.DataFrame(data)
接下来,你可以使用 corr() 方法来计算这两个列之间的相关性:
# 使用 corr() 方法计算数学和英语成绩之间的相关性
correlation = df['Math'].corr(df['English'])# 输出结果
print("Correlation between Math and English scores:", correlation)
输出结果:

在这个示例中,我们使用了
corr()方法计算了数学和英语成绩之间的相关性系数。相关性系数的值范围从 -1 到 1,其中:
- 1 表示完全正相关:当一个变量增加时,另一个变量也增加,变化方向相同。
- 0 表示无相关性:两个变量之间没有线性关系。
- -1 表示完全负相关:当一个变量增加时,另一个变量减少,变化方向相反。