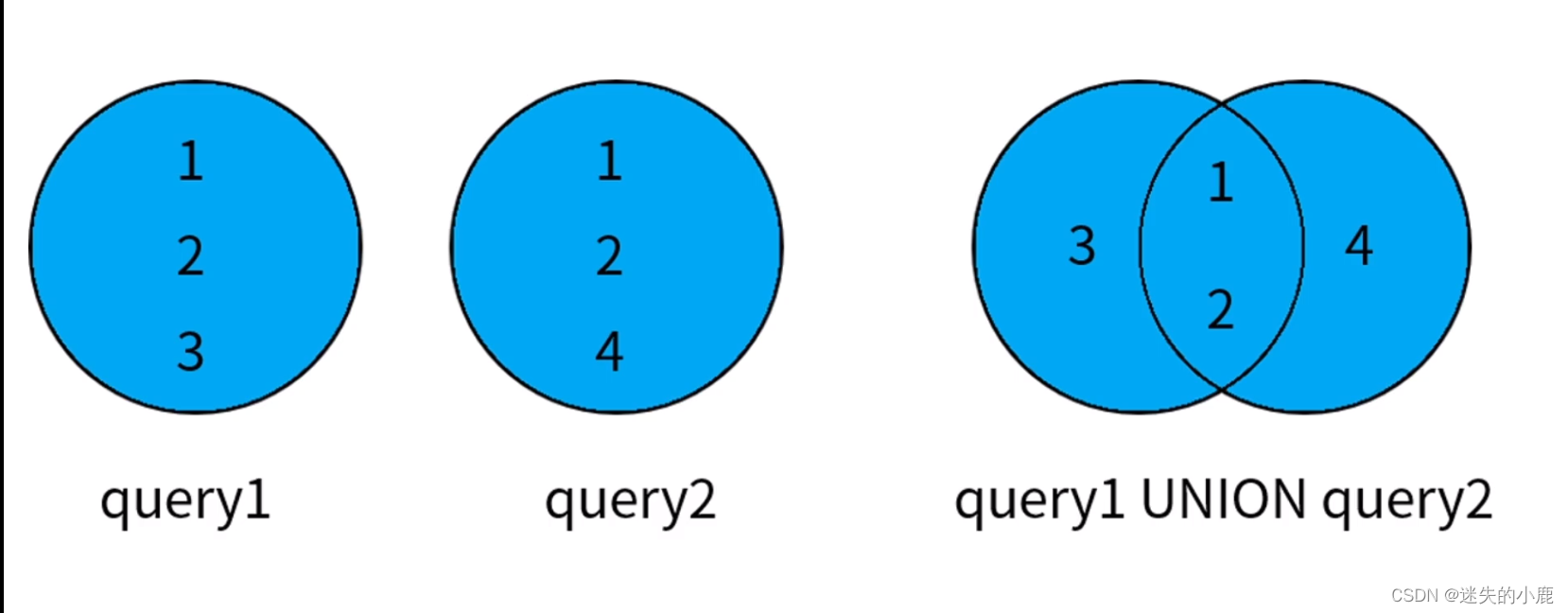
/** union* distinct 将合并后的结果集进行去重;(数据量大的时候影响性能)* all 保留结果集中的重复记录* 默认是distinct* */select e.emp_id
from excellent_emp e
where e."year"=2018uniondistinctselect
e.emp_id
from excellent_emp e
where e."year"=2019;
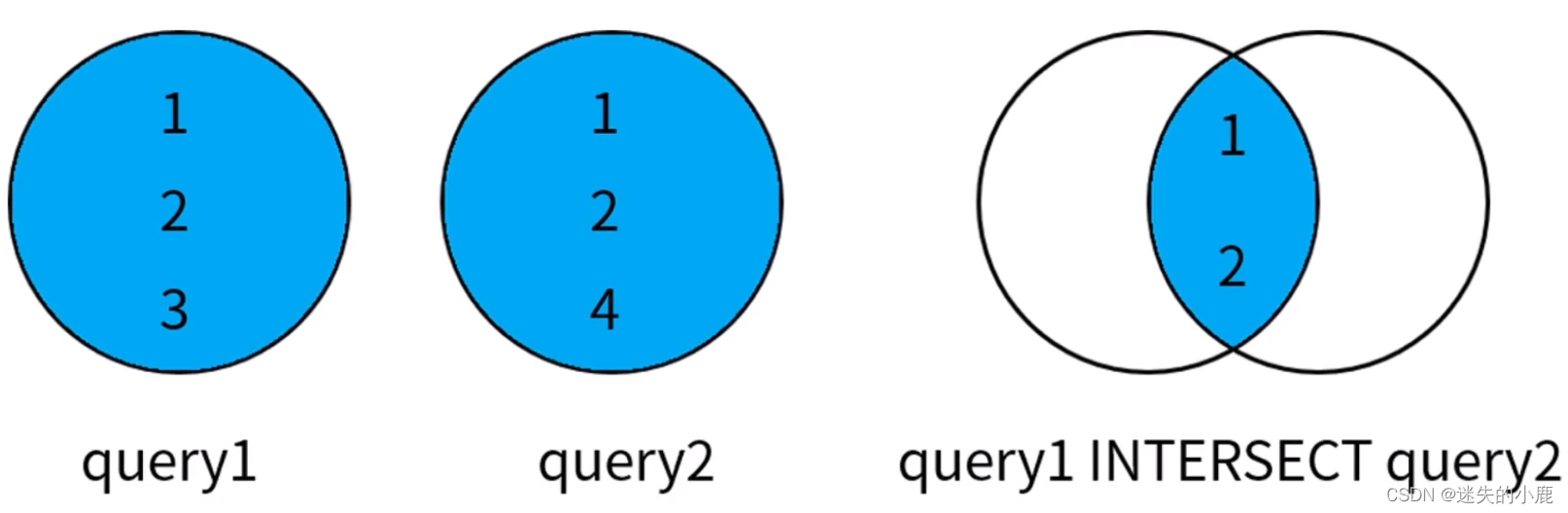
交集
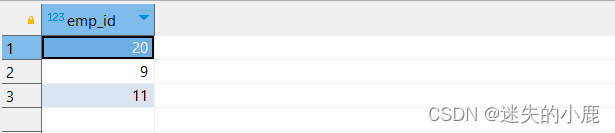
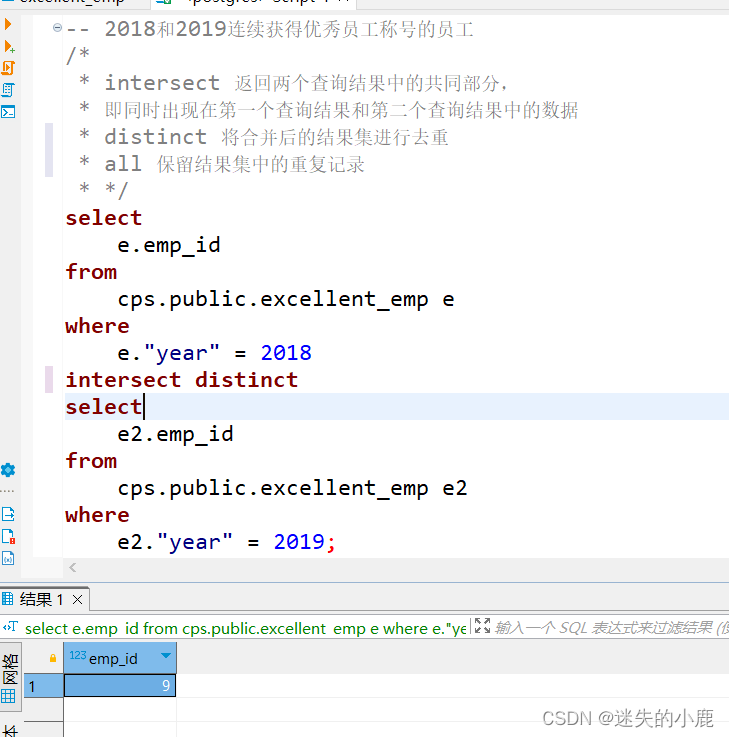
-- 2018和2019连续获得优秀员工称号的员工/** intersect 返回两个查询结果中的共同部分,* 即同时出现在第一个查询结果和第二个查询结果中的数据* distinct 将合并后的结果集进行去重* all 保留结果集中的重复记录* */selecte.emp_id
fromcps.public.excellent_emp e
wheree."year"=2018intersectdistinctselecte2.emp_id
fromcps.public.excellent_emp e2
wheree2."year"=2019;
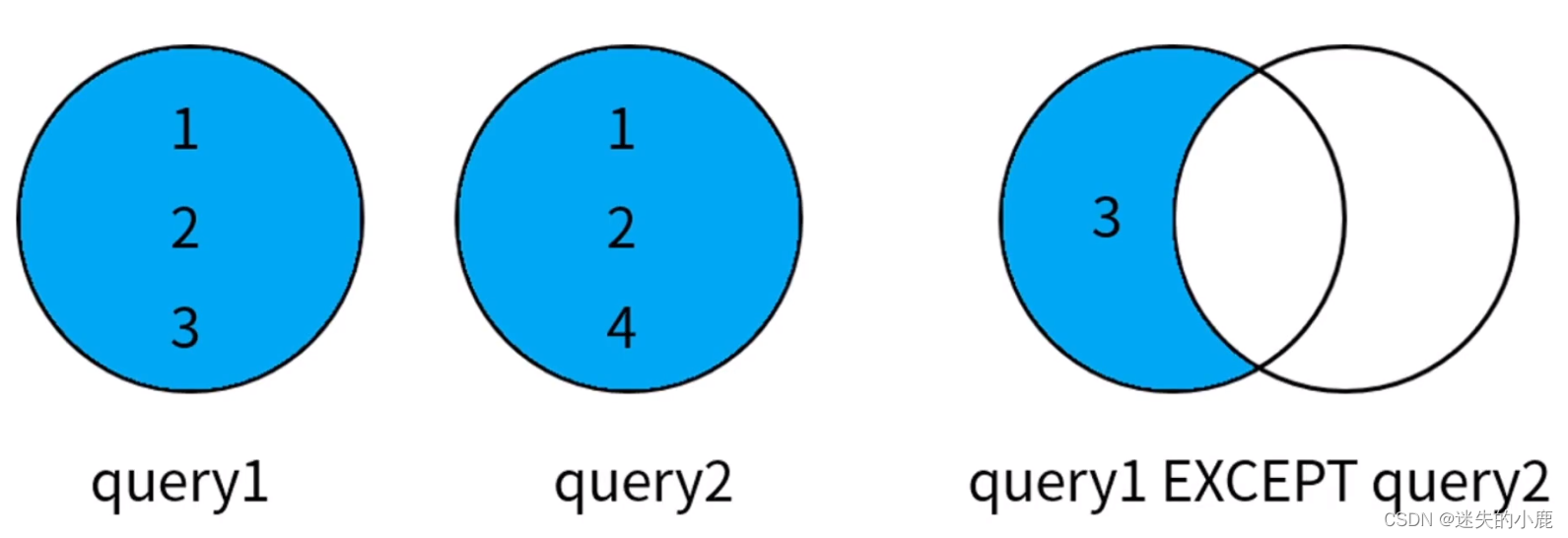
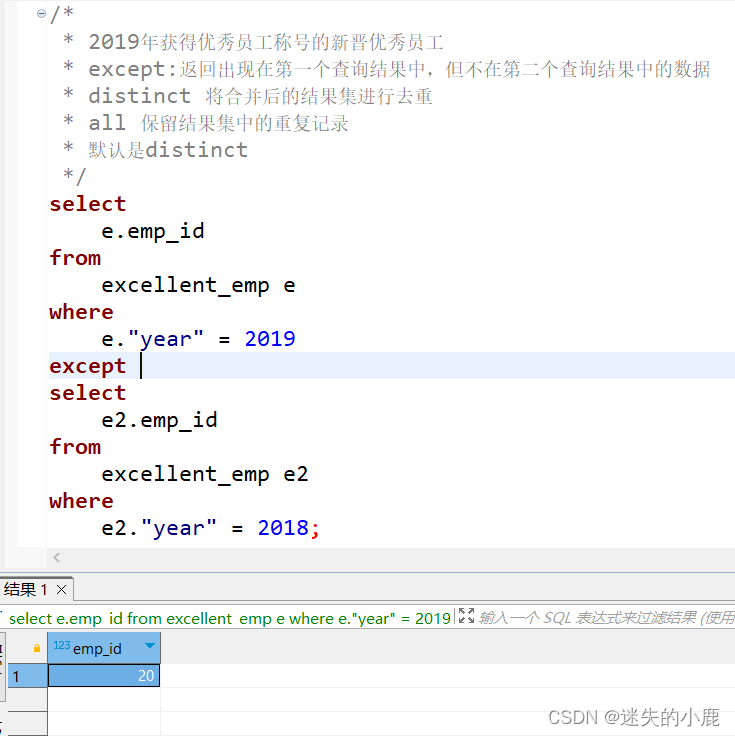
差集
/** 2019年获得优秀员工称号的新晋优秀员工* except:返回出现在第一个查询结果中,但不在第二个查询结果中的数据* distinct 将合并后的结果集进行去重* all 保留结果集中的重复记录* 默认是distinct*/selecte.emp_id
fromexcellent_emp e
wheree."year"=2019exceptselecte2.emp_id
fromexcellent_emp e2
wheree2."year"=2018;