一百七十二、Flume——Flume采集Kafka数据写入HDFS中(亲测有效、附截图)
一、目的
作为日志采集工具Flume,它在项目中最常见的就是采集Kafka中的数据然后写入HDFS或者HBase中,这里就是用flume采集Kafka的数据导入HDFS中
二、各工具版本
(一)Kafka
kafka_2.13-3.0.0.tgz
(二)Hadoop(HDFS)
hadoop-3.1.3.tar.gz
(三)Flume
apache-flume-1.9.0-bin.tar.gz
三、实施步骤
(一)到flume的conf的目录下
# cd /home/hurys/dc_env/flume190/conf

(二)创建配置文件evaluation.properties
# vi evaluation.properties
### Name agent, source, channels and sink alias
a1.sources = s1
a1.channels = c1
a1.sinks = k1
### define kafka source
a1.sources.s1.type = org.apache.flume.source.kafka.KafkaSource
# Maximum number of messages written to Channel in one batch
a1.sources.s1.batchSize = 5000
# Maximum time (in ms) before a batch will be written to Channel The batch will be written whenever the first of size and time will be reached.
a1.sources.s1.batchDurationMillis = 2000
# set kafka broker address
a1.sources.s1.kafka.bootstrap.servers = 192.168.0.27:9092
# set kafka consumer group Id and offset consume
# 官网推荐1.9.0版本只设置了topic,但测试后不能正常消费,需要添加消费组id(自己写一个),并定义偏移量消费方式
a1.sources.s1.kafka.consumer.group.id = evaluation_group
a1.sources.s1.kafka.consumer.auto.offset.reset = earliest
# set kafka topic
a1.sources.s1.kafka.topics = topic_b_evaluation
### defind hdfs sink
a1.sinks.k1.type = hdfs
# set store hdfs path
a1.sinks.k1.hdfs.path = hdfs://hurys22:8020/rtp/evaluation/evaluation_%Y-%m-%d
# set file size to trigger roll
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.threadsPoolSize = 30
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.writeFormat=Text
### define channel from kafka source to hdfs sink
# memoryChannel:快速,但是当设备断电,数据会丢失
# FileChannel:速度较慢,即使设备断电,数据也不会丢失
a1.channels.c1.type = file
# 这里不单独设置checkpointDir和dataDirs文件位置,参考官网不设置会有默认位置
# channel store size
a1.channels.c1.capacity = 100000
# transaction size
a1.channels.c1.transactionCapacity = 10000
### 绑定source、channel和sink
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
(三)配置文件创建好后启动flume服务
# cd /home/hurys/dc_env/flume190/
# ./bin/flume-ng agent -n a1 -f /home/hurys/dc_env/flume190/conf/evaluation.properties

(四)到HDFS文件里验证一下

HDFS中生成evaluation_2023-09-07 文件夹,里面有很多小文件
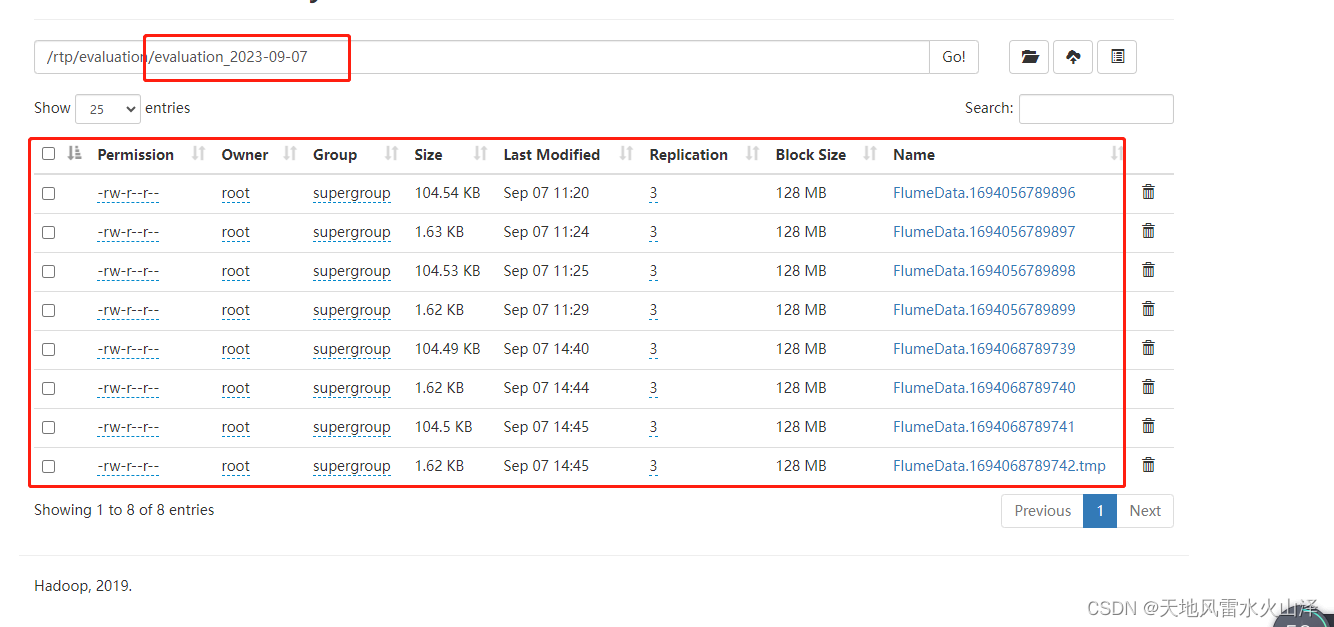
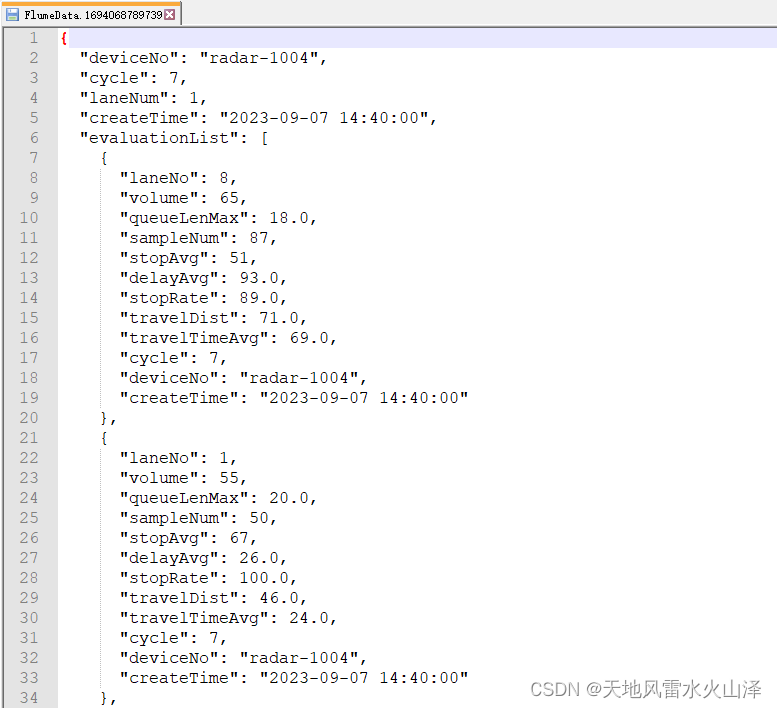
(五)注意:小文件里的数据是JSON格式,即使我设置文件后缀名为csv也没用(可能配置文件中的文件类型设置需要优化)
a1.sinks.k1.hdfs.writeFormat=Text
(六)jps查看Flume的服务
[root@hurys22 conf]# jps
16801 ResourceManager
4131 Application
18055 AlertServer
16204 DataNode
22828 Application
17999 LoggerServer
2543 launcher.jar
22224 Application
17393 QuorumPeerMain
16980 NodeManager
17942 WorkerServer
16503 SecondaryNameNode
11384 Application
32669 Application
17886 MasterServer
10590 Jps
16031 NameNode
18111 ApiApplicationServer

注意:Application就是Flume运行的任务
(七)关闭Flume服务
如果想要关闭Flume服务,直接杀死服务就好了
# kill -9 32669


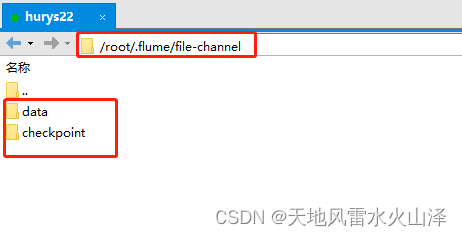
(八)checkpointDir和dataDirs默认的文件位置
默认的文件位置:/root/.flume/file-channel/
总之,Flume这个工具的用法还需进一步研究优化,当然kettle也可以,所以这个项目目前还是用kettle吧!