Typora导出的PDF目录标题自动加编号
Typora导出的PDF目录标题自动加编号
在Typora主题文件夹增加如下文件后,标题便自动加上了编号:
https://gitcode.net/as604049322/blog_data/-/blob/master/base.user.css
例如:
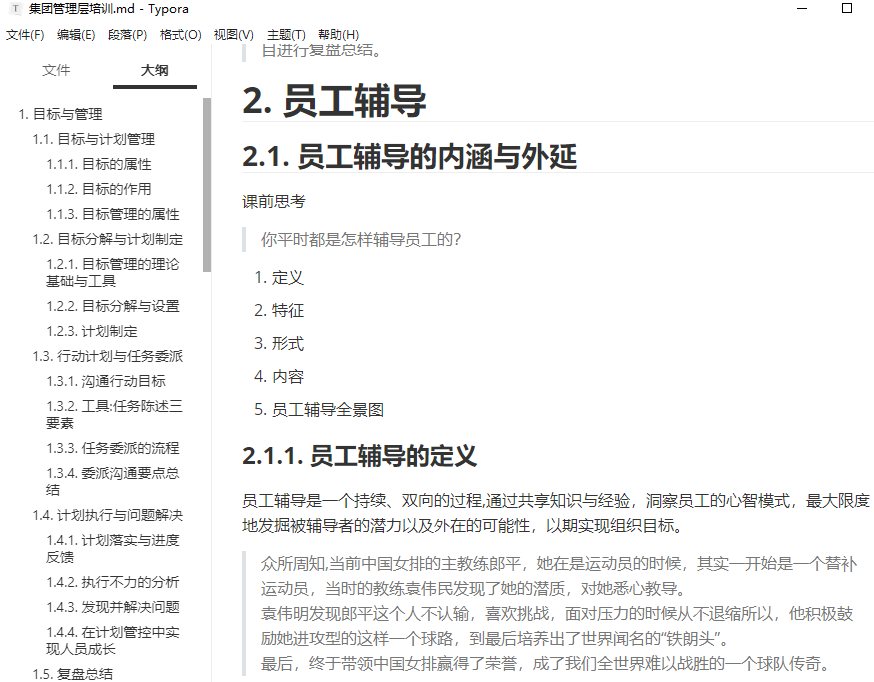
但是导出的PDF中,目录却没有编号:

这是我使用Python处理该文件,使其具有编号,完整代码如下:
# 博客地址:https://blog.csdn.net/as604049322
__author__ = '小小明-代码实体'
__date__ = '2023/8/31'from PyPDF2 import PdfReader, PdfWriterdef get_pdf_Bookmark(filename):"作者CSDN:https://blog.csdn.net/as604049322"if isinstance(filename, str):pdf_reader = PdfReader(filename)else:pdf_reader = filenamepagecount = len(pdf_reader.pages)# 用保存每个标题id所对应的页码idnum2pagenum = {}for i in range(pagecount):page = pdf_reader.pages[i]idnum2pagenum[page.indirect_ref.idnum] = i# 保存每个标题对应的标签数据,包括层级,标题和页码索引(页码-1)bookmark = []def get_pdf_Bookmark_inter(outlines, tab=0):for outline in outlines:if isinstance(outline, list):get_pdf_Bookmark_inter(outline, tab + 1)else:bookmark.append((tab, outline['/Title'], idnum2pagenum[outline.page.idnum]))get_pdf_Bookmark_inter(pdf_reader.outline)return bookmarkdef pdf_write_bookmark(bookmark, pdf_file, compress=True):pdf_reader = PdfReader(pdf_file)num_pages = len(pdf_reader.pages)pdf_writer = PdfWriter()for page in pdf_reader.pages:if compress:page.compress_content_streams()pdf_writer.add_page(page)# pdf_reader.last_cache = [None] * (max(bookmark, key=lambda x: x[0])[0] + 1)for tab, title, pagenum in bookmark:if pagenum >= num_pages:continueparent = last_cache[tab - 1] if tab > 0 else Noneindirect_id = pdf_writer.add_outline_item(title, pagenum, parent=parent)last_cache[tab] = indirect_idpdf_writer.page_mode = "/UseOutlines"with open(pdf_file, "wb") as out:pdf_writer.write(out)print("已成功将书签写入到", pdf_file)if __name__ == '__main__':file = r"C:\Users\sj\Desktop\集团管理层培训.pdf"bookmark = get_pdf_Bookmark(file)num_cache = [0] * 7last_tab = 0new_bookmark = []for tab, title, pagenum in bookmark:if tab > last_tab:num_cache[tab] = 1else:num_cache[tab] += 1new_title = titleif not title[0].isdigit():new_title = ".".join(map(str, num_cache[:tab + 1])) + " " + title# print(tab, new_title, pagenum)new_bookmark.append((tab, new_title, pagenum))last_tab = tabpdf_write_bookmark(new_bookmark, file)
处理后的PDF目录就有编号了:
