ClickHouse配置Hdfs存储数据
文章目录
- 背景
- 配置单机
- 配置HA高可用Hdfs集群
- 性能测试
- 统计trait最多的10个trait term
- 统计性状xxx minValue > 500 0000的数量
- 结论
- 参考文档
背景
由于公司初始使用Hadoop这一套,所以希望ClickHouse也能使用Hdfs作为存储
看了下ClickHouse的文档,拿Hdfs举例来说,有两种方式来完成,一种是直接关联Hdfs上的数据文件,比如说TSV格式的文件,这种模式不支持插入数据。第二种是将Hdfs作为存储,可以理解为云存储方式,这篇文章讲解第二种方式的配置
官方文档:External Disks for Storing Data
配置单机
修改config.xml文件,一般路径在/etc/clickhouse-server/config.xml
<storage_configuration><disks><hdfs><type>hdfs</type><endpoint>hdfs://hdfs1:9000/clickhouse/</endpoint></hdfs></disks><policies><hdfs><volumes><main><disk>hdfs</disk></main></volumes></hdfs></policies></storage_configuration><merge_tree><min_bytes_for_wide_part>0</min_bytes_for_wide_part></merge_tree>
配置后重启
配置HA高可用Hdfs集群
- 复制
hadoop下的配置文件hdfs-site.xml到/etc/clickhouse-server/下 - 修改
config.xml配置文件,将endpoint中的标签内容,替换为cluster
<disks><hdfs><type>hdfs</type><endpoint>hdfs://cluster1/clickhouse/</endpoint></hdfs></disks>
这种方式的配置是没有端口的
- 拷贝了
hdfs-site.xml文件,但是ClickHouse还不能识别到该文件,所以需要配置在config.xml的配置文件下
<hdfs><libhdfs3_conf>/etc/clickhouse-server/hdfs-site.xml</libhdfs3_conf></hdfs>
这里在官方文档的另外一处有提到
地址:HDFS
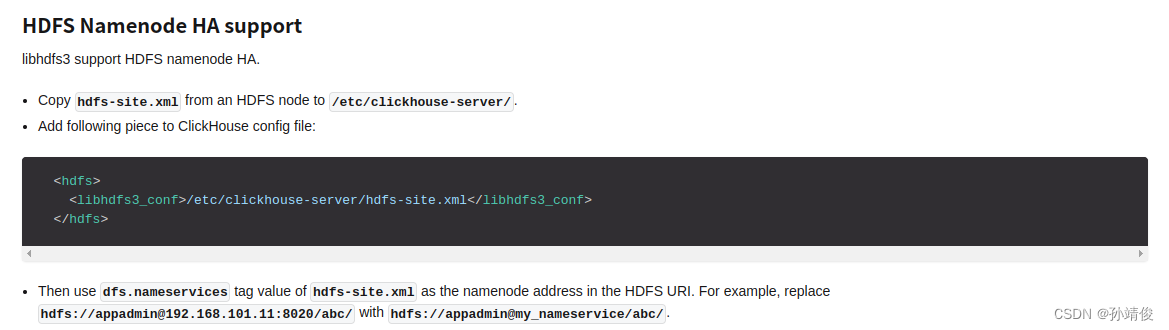
配置完成,重启
这里配置集群模式有些折腾,看到之前有讲如果是hdfs-client.xml这种的,可以参考下。中间还设置过环境变量:
How do I use an HDFS engine in HA mode
性能测试
使用hdfs作为外部存储的时候,需要在建表时,设置存储策略,举例如下:
CREATE TABLE trait_term
(id UUID,termName String
)
ENGINE = MergeTree
PRIMARY KEY (id)
ORDER BY id
SETTINGS index_granularity = 1024, storage_policy='hdfs', index_granularity_bytes = 0;
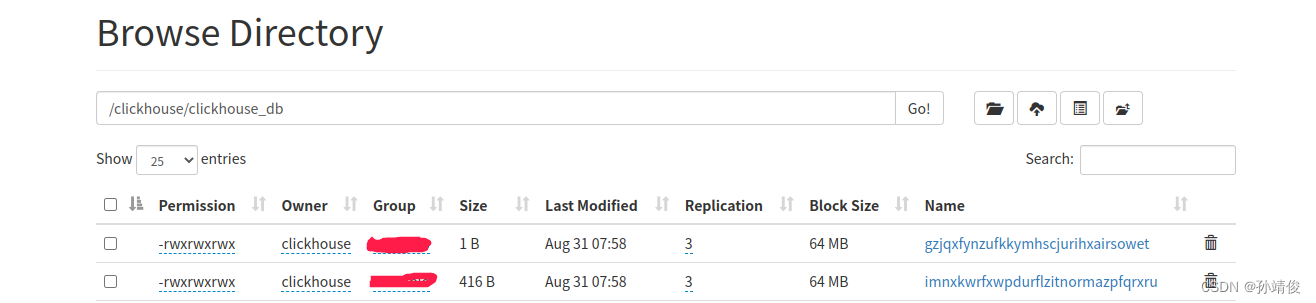
需要添加storage_policy='hdfs', 这样数据就会存储到hdfs中,在hdfs文件系统中查看
查询性能对比:

trait表大概有1700w条数据,这里主要和之前不使用外部存储,使用clickhouse当前机器的存储做对比
统计trait最多的10个trait term
| 场景 | 内部存储 | hdfs存储 |
|---|---|---|
| 直接查询 | 0.767s | 0.723s |
| 创建视图查询 | 0.495s | 0.471s |
| 子查询优化 | 0.157s | 0.172s |
统计性状xxx minValue > 500 0000的数量
| 场景 | 内部存储 | hdfs存储 |
|---|---|---|
| 直接查询 | 0.263s | 0.353s |
| 子查询优化 | 0.131s | 0.207s |
| 创建视图走索引 | 0.01s | 0.023s |
| 降低稀疏索引粒度 | 0.007s | 0.015s |
结论
根据测试结果,hdfs外部存储会比直接内部存储性能差一点点,但是也差不了多少,使用hdfs可以避免单机存储不够的问题,与公司的技术栈也会保持一致
参考文档
clickhouse之HDFS云存储
clickhouse hive/hdfs引擎由于HDFS-HA报错问题解决
How do I use an HDFS engine in HA mode