mysql索引为什么提高查询速度(底层原理)
一、索引原理图
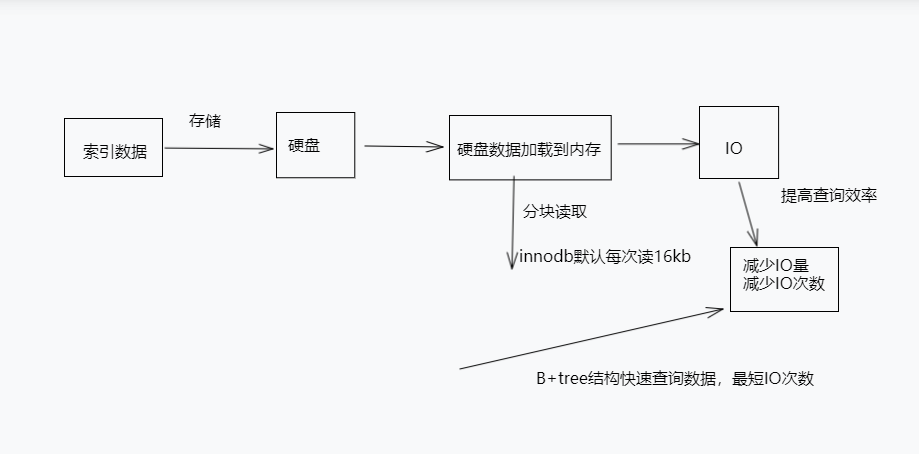
二、索引数据存储到硬盘而不是内存?
| 硬盘 | 内存 |
| 成本低 | 成本高 |
| 容量大 | 容量小 |
| 读写速度一般 | 读取速度快 |
| 断电后数据永久存储 | 断电后数据清空 |
三、硬盘数据为什么要读取到内存?为啥不直接读取硬盘
1、将数据直接从硬盘读取可能会导致较长的等待时间,影响系统的响应速度
2、将数据读取到内存中,可以充分利用内存的高速读写能力,加快数据的访问速度
3、通过将数据缓存到内存中,可以减少对硬盘的频繁读写,降低硬盘的负载,延长硬盘的使用寿命
四、为什么要分块读取?
1、减少硬盘寻道时间:硬盘的读取速度相对较慢,将数据分成多个块进行读取,可以减少硬盘进行寻道的次数
2、提高数据传输效率:硬盘数据的读取通常是通过DMA(直接内存访问)技术进行的,而DMA传输的单位是块。将数据分成多个块进行读取,可以充分利用DMA的高效传输能力
3、避免内存浪费:将数据分块读取可以避免一次性将大量数据加载到内存中,从而避免浪费内存资源。同时,分块读取也可以更好地适应内存的大小限制
五、索引提高查询效率本质,
减少IO次数和量
1、减少数据读取量:索引更快地定位到需要的数据行,从而减少了需要扫描的数据量,减少IO次数
2、利用索引覆盖:索引覆盖是指查询语句只需要通过索引就能够取得需要的数据,而无需再次访问数据行
3、顺序访问:利用索引的有序性,进行顺序访问,减少磁盘IO的随机访问