计算机毕设 大数据商城人流数据分析与可视化 - python 大数据分析
文章目录
- 0 前言
- 课题背景
- 分析方法与过程
- 初步分析:
- 总体流程:
- 1.数据探索分析
- 2.数据预处理
- 3.构建模型
- 总结
- 最后
0 前言
🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是
🚩 基于大数据的基站数据分析与可视化
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:3分
课题背景
- 随着当今个人手机终端的普及,出行群体中手机拥有率和使用率已达到相当高的比例,手机移动网络也基本实现了城乡空间区域的全覆盖。根据手机信号在真实地理空间上的覆盖情况,将手机用户时间序列的手机定位数据,映射至现实的地理空间位置,即可完整、客观地还原出手机用户的现实活动轨迹,从而挖掘得到人口空间分布与活动联系特征信息。移动通信网络的信号覆盖从逻辑上被设计成由若干六边形的基站小区相互邻接而构成的蜂窝网络面状服务区,手机终端总是与其中某一个基站小区保持联系,移动通信网络的控制中心会定期或不定期地主动或被动地记录每个手机终端时间序列的基站小区编号信息。
- 商圈是现代市场中企业市场活动的空间,最初是站在商品和服务提供者的产地角度提出,后来逐渐扩展到商圈同时也是商品和服务享用者的区域。商圈划分的目的之一是为了研究潜在的顾客的分布以制定适宜的商业对策。
分析方法与过程
初步分析:
- 手机用户在使用短信业务、通话业务、开关机、正常位置更新、周期位置更新和切入呼叫的时候均产生定位数据,定位数据记录手机用户所处基站的编号、时间和唯一标识用户的EMASI号等。历史定位数据描绘了用户的活动模式,一个基站覆盖的区域可等价于商圈,通过归纳经过基站覆盖范围的人口特征,识别出不同类别的基站范围,即可等同地识别出不同类别的商圈。衡量区域的人口特征可从人流量和人均停留时间的角度进行分析,所以在归纳基站特征时可针对这两个特点进行提取。
总体流程:
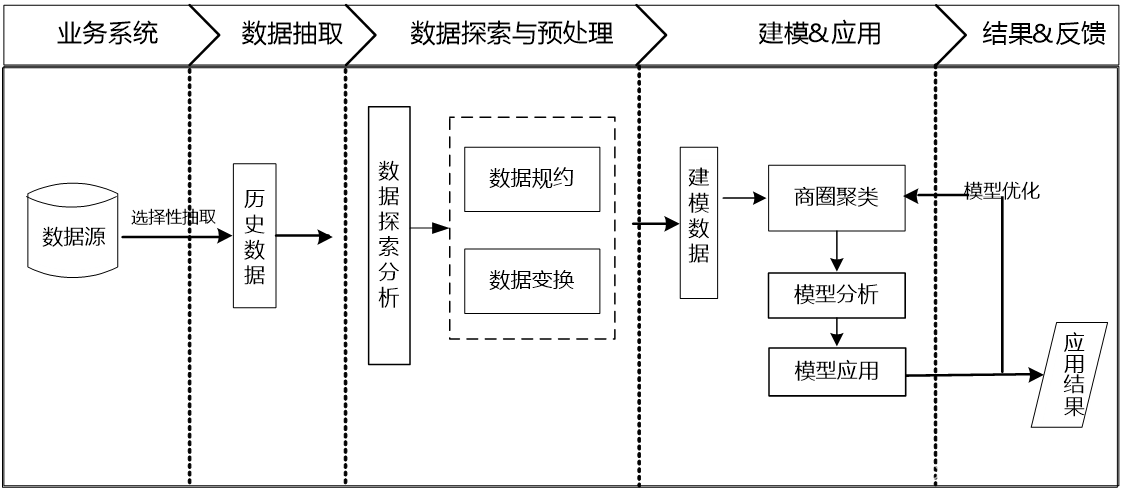
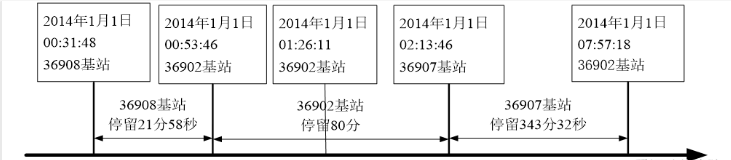
1.数据探索分析
EMASI号为55555的用户在2014年1月1日的定位数据

2.数据预处理
数据规约
- 网络类型、LOC编号和信令类型这三个属性对于挖掘目标没有用处,故剔除这三个冗余的属性。而衡量用户的停留时间并不需要精确到毫秒级,故可把毫秒这一属性删除。
- 把年、月和日合并记为日期,时、分和秒合并记为时间。
import numpy as npimport pandas as pddata=pd.read_excel('C://Python//DataAndCode//chapter14//demo//data//business_circle.xls')# print(data.head())#删除三个冗余属性del data[['网络类型','LOC编号','信令类型']]#合并年月日periods=pd.PeriodIndex(year=data['年'],month=data['月'],day=data['日'],freq='D')data['日期']=periodstime=pd.PeriodIndex(hour=data['时'],minutes=data['分'],seconds=data['秒'],freq='D')data['时间']=timedata['日期']=pd.to_datetime(data['日期'],format='%Y/%m/%d')data['时间']=pd.to_datetime(data['时间'],format='%H/%M/%S')
数据变换
假设原始数据所有用户在观测窗口期间L( 天)曾经经过的基站有 N个,用户有 M个,用户 i在 j天在 num1 基站的工作日上班时间停留时间为
weekday_num1,在 num1 基站的凌晨停留时间为night_num1 ,在num1基站的周末停留时间为weekend_num1, 在
num1基站是否停留为 stay_num1 ,设计基站覆盖范围区域的人流特征:
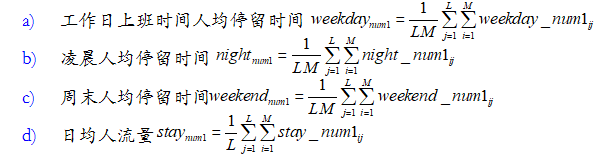

由于各个属性的之间的差异较大,为了消除数量级数据带来的影响,在进行聚类前,需要进行离差标准化处理。
#-*- coding: utf-8 -*-#数据标准化到[0,1]import pandas as pd#参数初始化filename = '../data/business_circle.xls' #原始数据文件standardizedfile = '../tmp/standardized.xls' #标准化后数据保存路径data = pd.read_excel(filename, index_col = u'基站编号') #读取数据data = (data - data.min())/(data.max() - data.min()) #离差标准化data = data.reset_index()data.to_excel(standardizedfile, index = False) #保存结果
3.构建模型
构建商圈聚类模型
采用层次聚类算法对建模数据进行基于基站数据的商圈聚类,画出谱系聚类图。从图可见,可把聚类类别数取3类。
#-*- coding: utf-8 -*-#谱系聚类图import pandas as pd#参数初始化standardizedfile = '../data/standardized.xls' #标准化后的数据文件data = pd.read_excel(standardizedfile, index_col = u'基站编号') #读取数据import matplotlib.pyplot as pltfrom scipy.cluster.hierarchy import linkage,dendrogram#这里使用scipy的层次聚类函数Z = linkage(data, method = 'ward', metric = 'euclidean') #谱系聚类图P = dendrogram(Z, 0) #画谱系聚类图plt.show()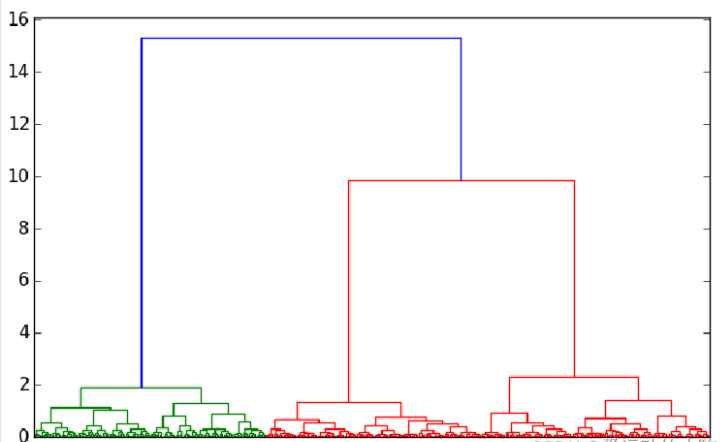
模型分析
针对聚类结果按不同类别画出4个特征的折线图。
#-*- coding: utf-8 -*-#层次聚类算法import pandas as pd#参数初始化standardizedfile = '../data/standardized.xls' #标准化后的数据文件k = 3 #聚类数data = pd.read_excel(standardizedfile, index_col = u'基站编号') #读取数据from sklearn.cluster import AgglomerativeClustering #导入sklearn的层次聚类函数model = AgglomerativeClustering(n_clusters = k, linkage = 'ward')model.fit(data) #训练模型#详细输出原始数据及其类别r = pd.concat([data, pd.Series(model.labels_, index = data.index)], axis = 1) #详细输出每个样本对应的类别r.columns = list(data.columns) + [u'聚类类别'] #重命名表头import matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号style = ['ro-', 'go-', 'bo-']xlabels = [u'工作日人均停留时间', u'凌晨人均停留时间', u'周末人均停留时间', u'日均人流量']pic_output = '../tmp/type_' #聚类图文件名前缀for i in range(k): #逐一作图,作出不同样式plt.figure()tmp = r[r[u'聚类类别'] == i].iloc[:,:4] #提取每一类for j in range(len(tmp)):plt.plot(range(1, 5), tmp.iloc[j], style[i])plt.xticks(range(1, 5), xlabels, rotation = 20) #坐标标签plt.title(u'商圈类别%s' %(i+1)) #我们计数习惯从1开始plt.subplots_adjust(bottom=0.15) #调整底部plt.savefig(u'%s%s.png' %(pic_output, i+1)) #保存图片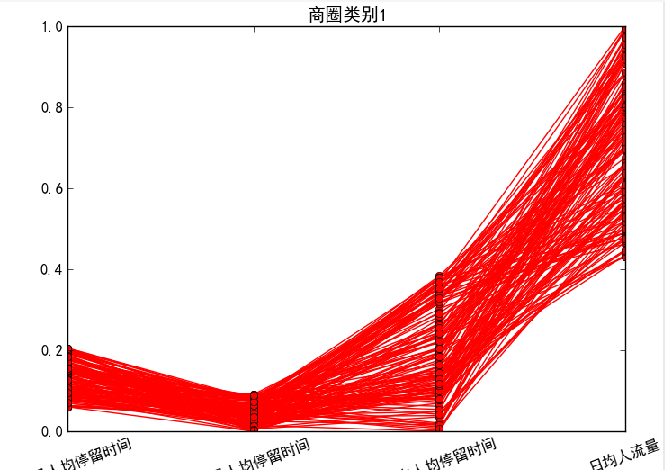
对于商圈类别1,日均人流量较大,同时工作日上班时间人均停留时间、凌晨人均停留时间和周末人均停留时间相对较短,该类别基站覆盖的区域类似于商业区

对于商圈类别2,凌晨人均停留时间和周末人均停留时间相对较长,而工作日上班时间人均停留时间较短,日均人流量较少,该类别基站覆盖的区域类似于住宅区。
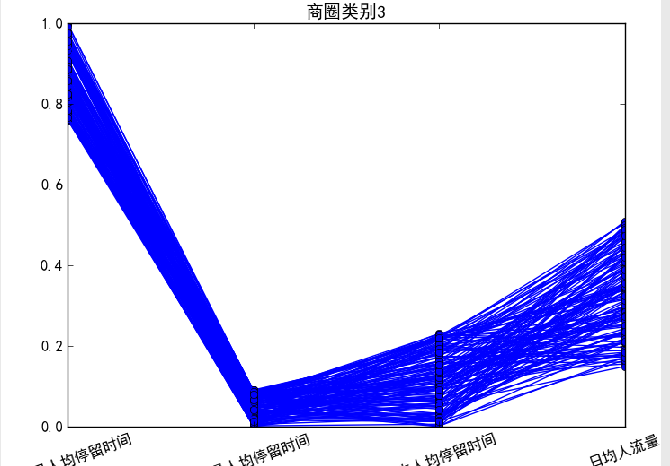
对于商圈类别3,这部分基站覆盖范围的工作日上班时间人均停留时间较长,同时凌晨人均停留时间、周末人均停留时间相对较短,该类别基站覆盖的区域类似于白领上班族的工作区域。
总结
商圈类别2的人流量较少,商圈类别3的人流量一般,而且白领上班族的工作区域一般的人员流动集中在上下班时间和午间吃饭时间,这两类商圈均不利于运营商的促销活动的开展,商圈类别1的人流量大,在这样的商业区有利于进行运营商的促销活动。