使用 BERT 进行文本分类 (03/3)

一、说明
在使用BERT(2)进行文本分类时,我们讨论了什么是PyTorch以及如何预处理我们的数据,以便可以使用BERT模型对其进行分析。在这篇文章中,我将向您展示如何训练分类器并对其进行评估。
二、准备数据的又一个步骤
上次,我们使用train_test_split将数据拆分为测试和验证数据。接下来需要的一个重要步骤是将数据转换为值列表,以便稍后可以在我们的训练器方法中调用它们。此步骤在其他教程中经常被忽略,当您无法微调模型时,这通常是问题所在。
# This is a continuation from the code written in Text Classification with BERT (2)
from sklearn.model_selection import train_test_split
X_train, X_val, y_train, y_val = train_test_split(df_balanced['Message'],df_balanced['Label'], stratify=df_balanced['Label'], test_size=.2)# Store everything in list of values
train_texts = X_train.to_list()
val_texts = X_val.to_list()
train_labels = y_train.to_list()
val_labels = y_val.to_list()2.1 标记化
现在我们已经准备好了我们的数据集,我们需要做一些标记化。我们将使用DistilBERT来实现这一点。引用拥抱脸的话:
DistilBERT是一种小型,快速,廉价和轻便的变压器模型,通过蒸馏Bert基础进行训练。它的参数比 bert-base-uncase 少 40%,运行速度快 60%,同时保留了 95% 以上的 Bert 性能,如 GLUE 语言理解基准测试所示。
导入模型后,我们将文本传递给分词器。如果您已经忘记了填充和截断,请检查使用 BERT 进行文本分类 (01/3) 的 文
from transformers import DistilBertTokenizerFast
tokenizer = DistilBertTokenizerFast.from_pretrained('distilbert-base-uncased')train_encodings = tokenizer(train_texts, truncation=True, padding=True)
val_encodings = tokenizer(val_texts, truncation=True, padding=True)2.2 格式化我们的数据集
在这里,我们需要将输入数据转换为可用于使用 PyTorch 训练深度学习模型的格式。
import torchclass SmapDataset(torch.utils.data.Dataset):def __init__(self, encodings, labels):self.encodings = encodingsself.labels = labelsdef __getitem__(self, idx):item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}item['labels'] = torch.tensor(self.labels[idx])return itemdef __len__(self):return len(self.labels)train_dataset = SmapDataset(train_encodings, train_labels)
val_dataset = SmapDataset(val_encodings, val_labels) 类的构造函数方法 () 通过将输入存储为 和 类属性来初始化数据集对象。__init__SmapDatasetencodingslabels
此类的方法用于从给定索引处的数据集中检索单个项目。它返回一个包含两个元素的字典对象:__getitem__idxitem
- 该元素是包含输入编码的字典对象,其中键是编码功能的名称,值是包含给定索引处的编码数据的 PyTorch 张量。
encodingsidx - 该元素是一个 PyTorch 张量,其中包含给定索引处的标签数据。
labelsidx
此类的方法返回数据集中的样本总数。__len__
最后,代码创建两个数据集对象,并使用类传入 、、 和 作为输入参数。这些数据集对象可用于在 PyTorch 模型中进行训练和验证。train_datasetval_datasetSmapDatasettrain_encodingstrain_labelsval_encodingsval_labels
2.3 使用培训师进行微调
我们以培训师预期的方式准备了数据。现在我们需要根据数据微调预训练模型。默认情况下,trainer.train 方法将仅报告训练损失。我将定义自己的指标函数并将其传递给培训师。
from sklearn.metrics import accuracy_score, precision_recall_fscore_supportdef compute_metrics(pred):labels = pred.label_idspreds = pred.predictions.argmax(-1)precision, recall, f1, _ = precision_recall_fscore_support(labels, preds, average='weighted', zero_division=0)acc = accuracy_score(labels, preds)return {'accuracy': acc,'f1': f1,'precision': precision,'recall': recall}- 准确性: 这是正确分类的样本占数据集中样本总数的比例。换句话说,它衡量模型正确预测数据集中所有样本的类标签的能力。虽然准确性是一个常用的指标,但在某些情况下可能会产生误导,尤其是在处理类分布不相等的不平衡数据集时。
- 精度:此指标度量真阳性预测(正确预测的正样本)在模型做出的所有正预测中的比例。换句话说,它衡量模型正确预测正样本的频率。当我们想要避免假阳性预测时,即当错误地将样本预测为阳性时,当样本实际上是负数时,精度非常有用。
- 召回:此指标衡量数据集中所有真阳性样本中真正预测的比例。换句话说,它衡量模型找到所有正样本的能力。当我们想要避免假阴性预测时,即当错误地将样本预测为阴性时,当样本实际上是阳性时,召回率很有用。
- F1比分:此指标是精度和召回率的调和平均值,并提供了一种平衡这两个指标的方法。它衡量精度和召回率之间的平衡,并且在假阳性和假阴性错误都有后果时很有用。
from transformers import DistilBertForSequenceClassification, Trainer, TrainingArgumentstraining_args = TrainingArguments(output_dir='./results', # output directorynum_train_epochs=3, # total number of training epochsper_device_train_batch_size=16, # batch size per device during trainingper_device_eval_batch_size=64, # batch size for evaluationwarmup_steps=500, # number of warmup steps for learning rate schedulerweight_decay=0.01, # strength of weight decaylogging_dir='./logs', # directory for storing logslogging_steps=10,evaluation_strategy="steps"
)model = DistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased")trainer = Trainer(model=model, # the instantiated 🤗 Transformers model to be trainedargs=training_args, # training arguments, defined abovetrain_dataset=train_dataset, # training dataseteval_dataset=val_dataset, # validation datasetcompute_metrics=compute_metrics
)trainer.train()2.4 结果
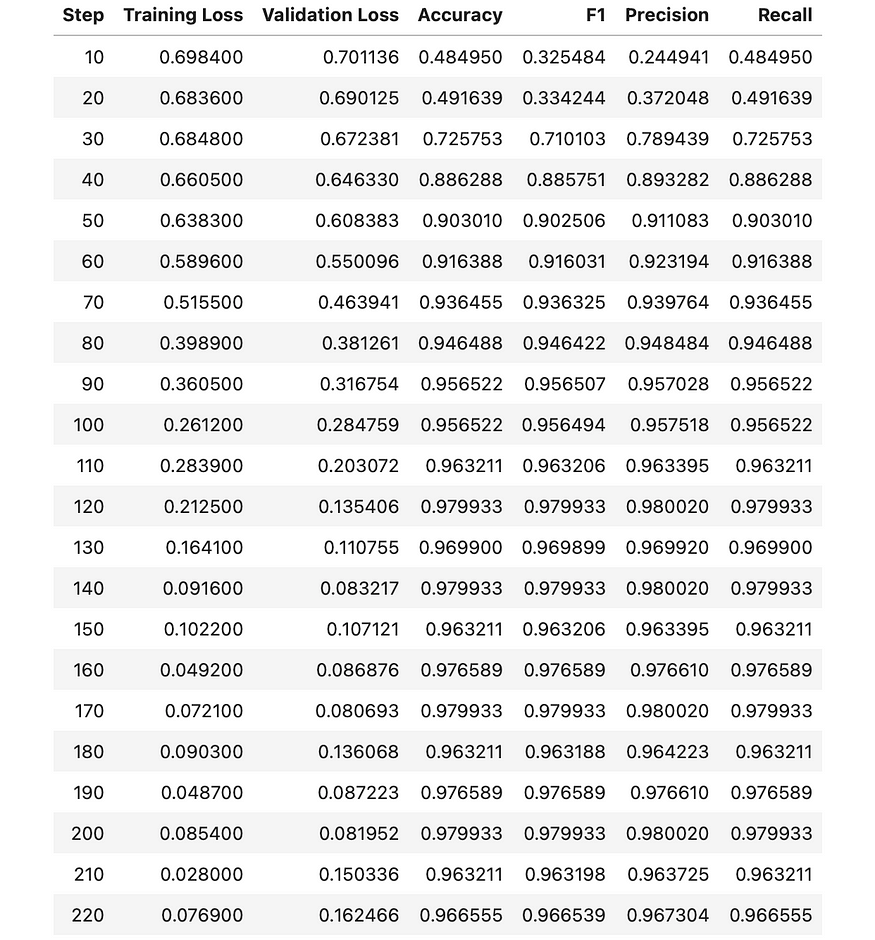
正如我们所看到的,我们的 F1 分数达到了 98% 左右,这表明我们的模型在判断邮件在我们的验证数据集中是垃圾邮件还是正常邮件方面表现良好。请记住,真正的测试数据集是野外未标记的消息。在本案例研究中,我们没有特权测试它在现实世界中的执行方式。
三、总结
在这篇文章中,我们学习了如何微调BERT模型以进行文本分类,并定义了自己的函数来评估我们的自定义模型。达门·