李宏毅机器学习笔记:RNN循环神经网络
RNN
- 一、RNN
- 1、场景引入
- 2、如何将一个单词表示成一个向量
- 3种典型的RNN网络结构
- 二、LSTM
- LSTM和普通NN、RNN区别
- 三、 RNN的训练
- RNN与auto encoder和decoder
- 四、RNN和结构学习的区别
一、RNN
1、场景引入
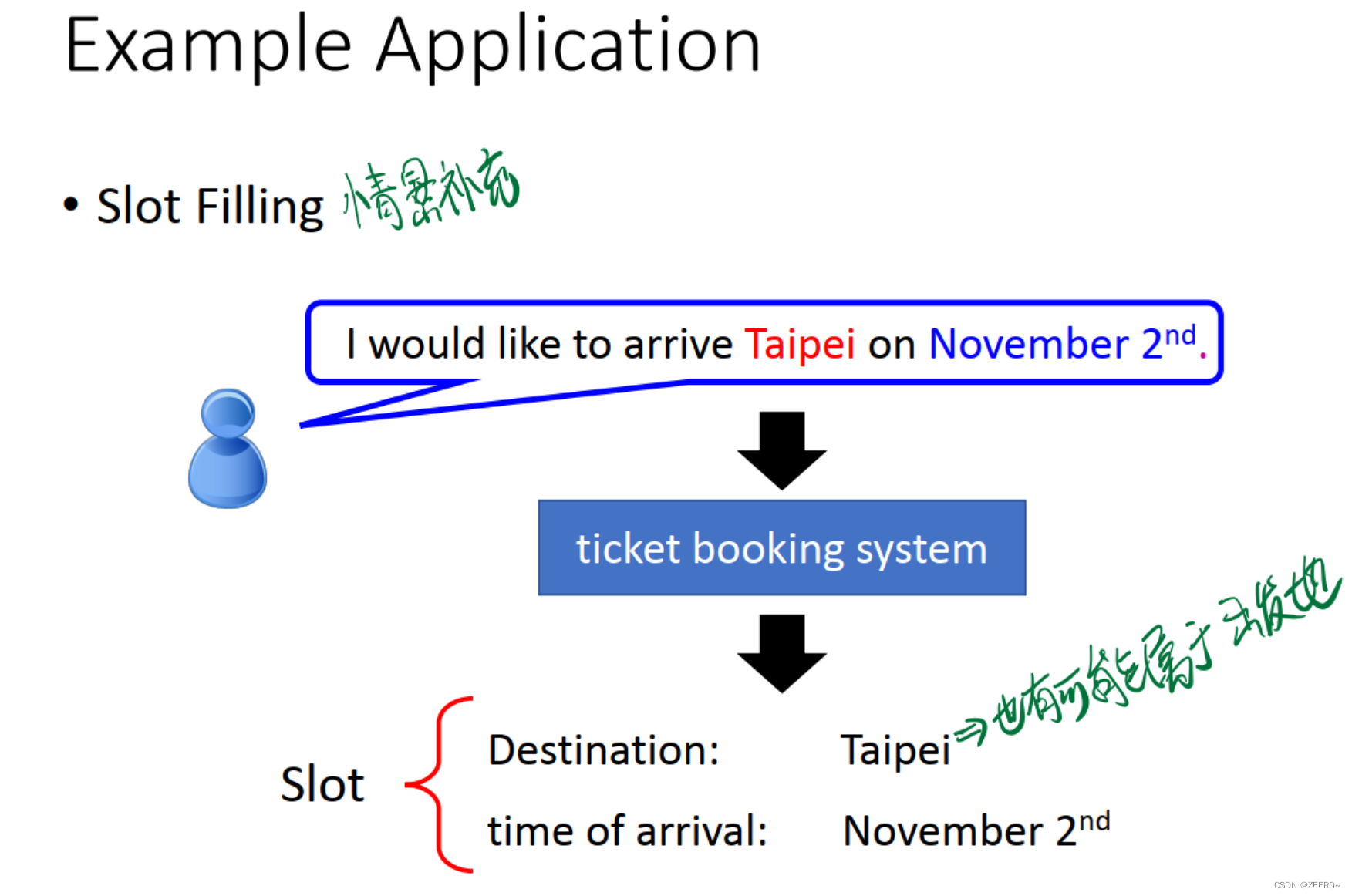
例如情景补充的情况,根据词汇预测该词汇所属的类别。这个时候的Taipi则属于目的地。但是,在订票系统中,Taipi也可能会属于出发地。到底属于目的地,还是出发地,如果不结合上下文,则很难做出判断。因此,使用传统的深度神经网络解决不了问题,必须引入RNN。
2、如何将一个单词表示成一个向量
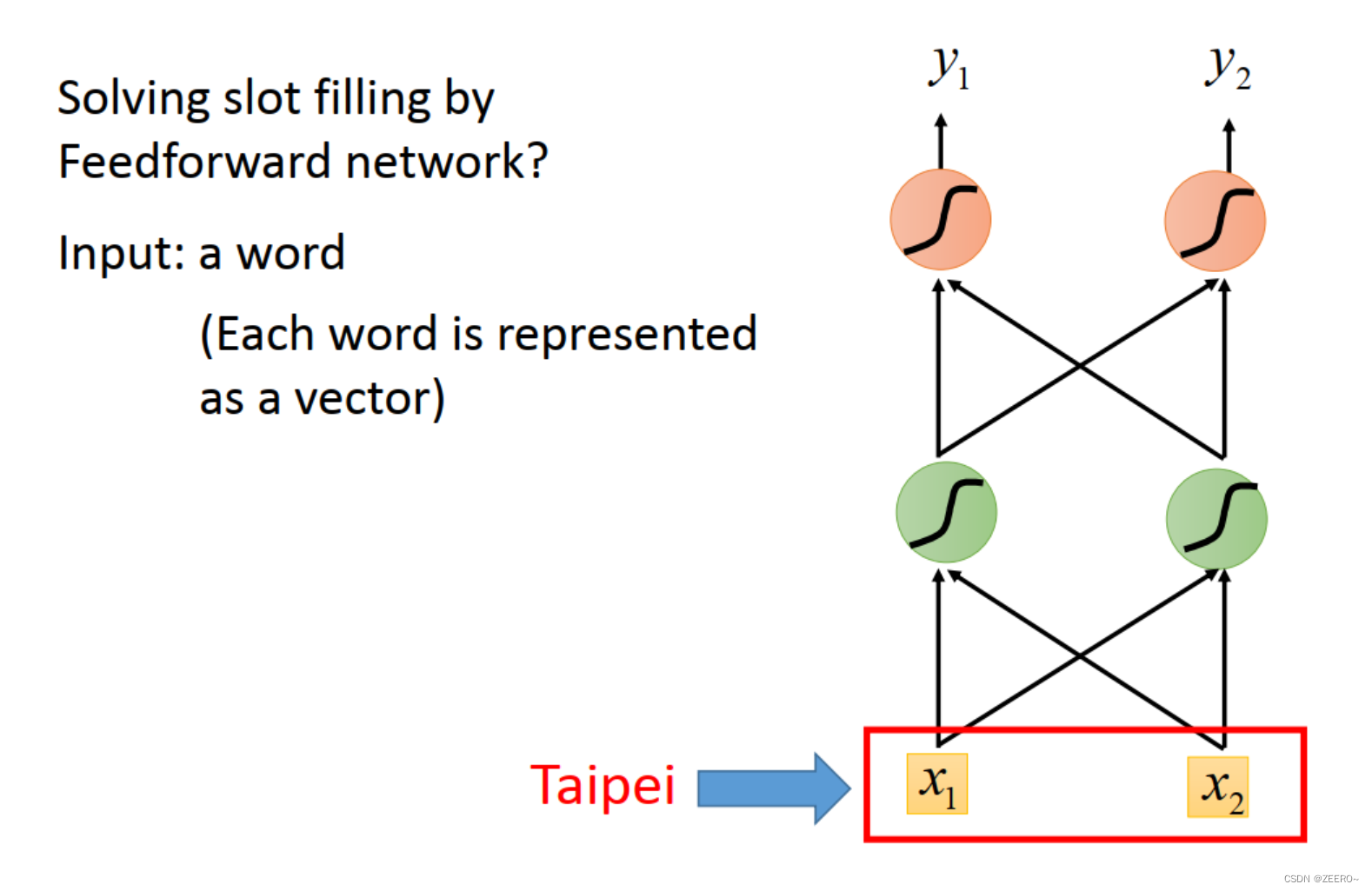
如上图所示,将词汇Taipi表示成[x1,x2]组成的向量。

一个最简单的方法是1-N encoding。思路是将所有的可能用到的词汇组成一个词典,然后假如我们一共只可能用到5个单词,则如上图所示,每个单词可以用1个五维向量来表示。
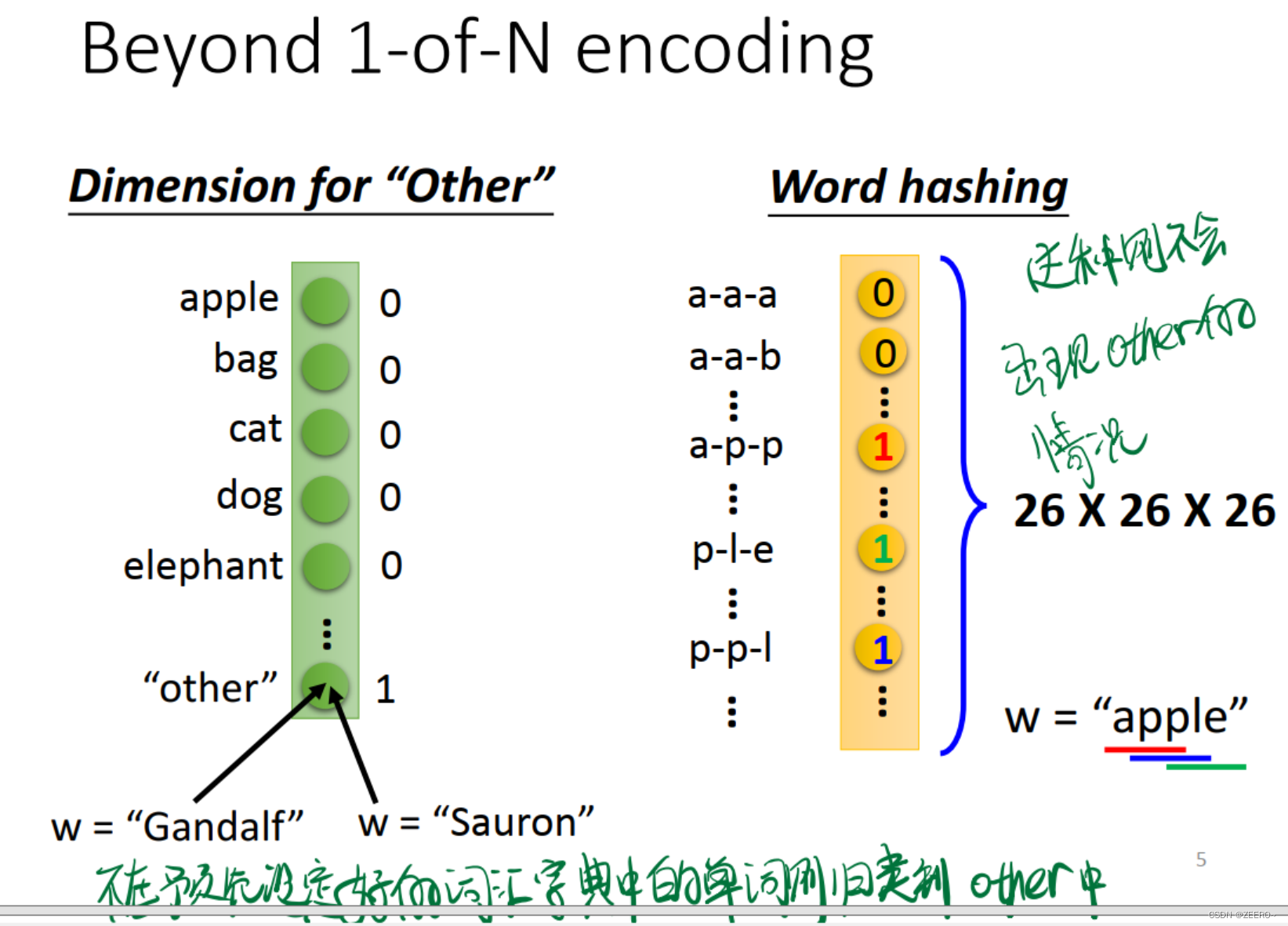
除了1-N econding之外,还有一些其他的方法。
第一种思路是设置1个other选项,将所有没有预先在词典中所设定的单词表示成other。
第二种思路是利用26个字母进行hash映射。这种情况下则不需要额外考虑other的情况。
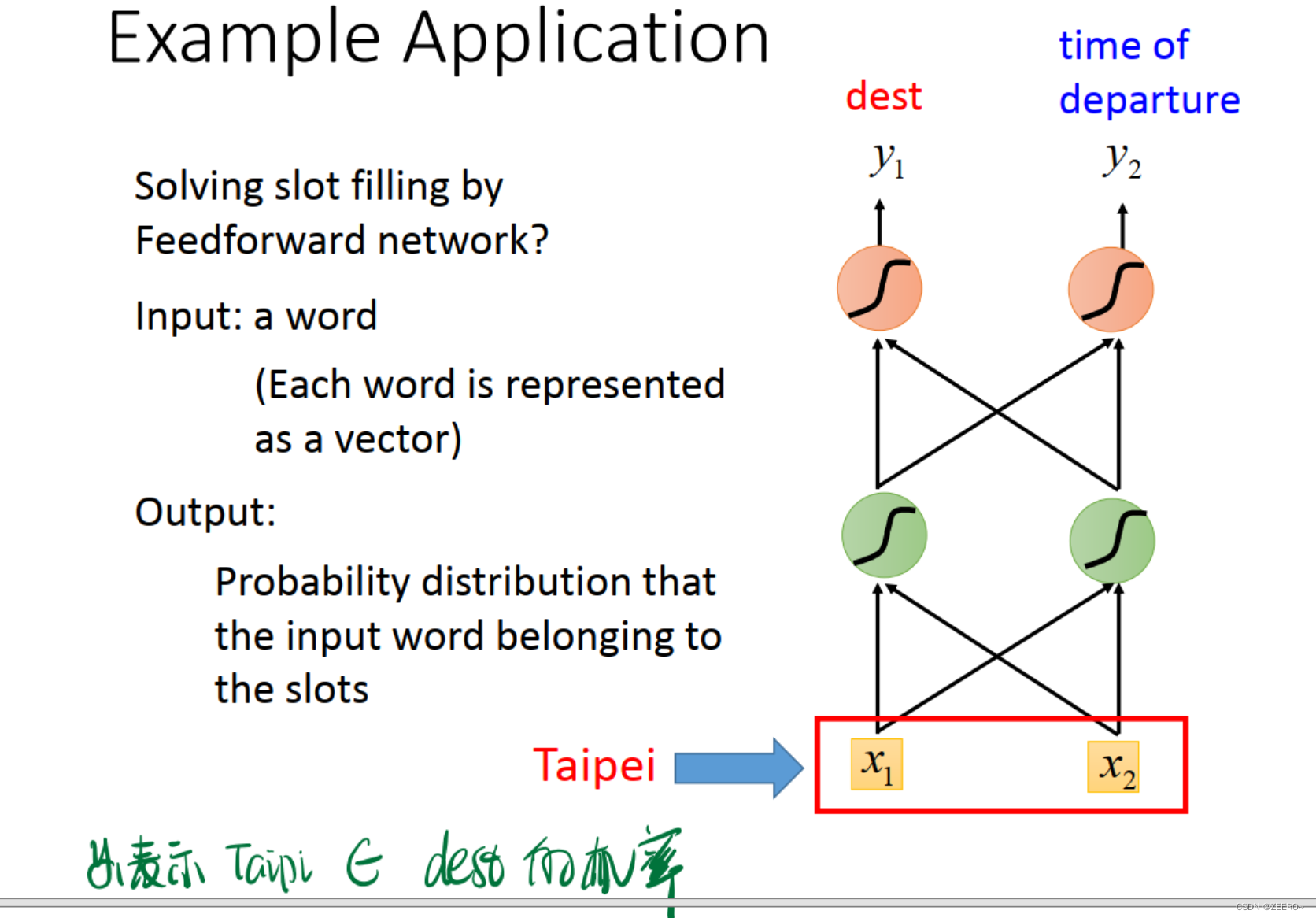
这样,将词汇向量化之后,我们指导,网络的输入为一个个的词汇向量,网络的输出则为:y1表示词汇属于dest目的地的概率,y2则表示词汇属于出发地的概率。最后其实应该还有一层,做出预测,属于哪个概率最大,则输出哪个。
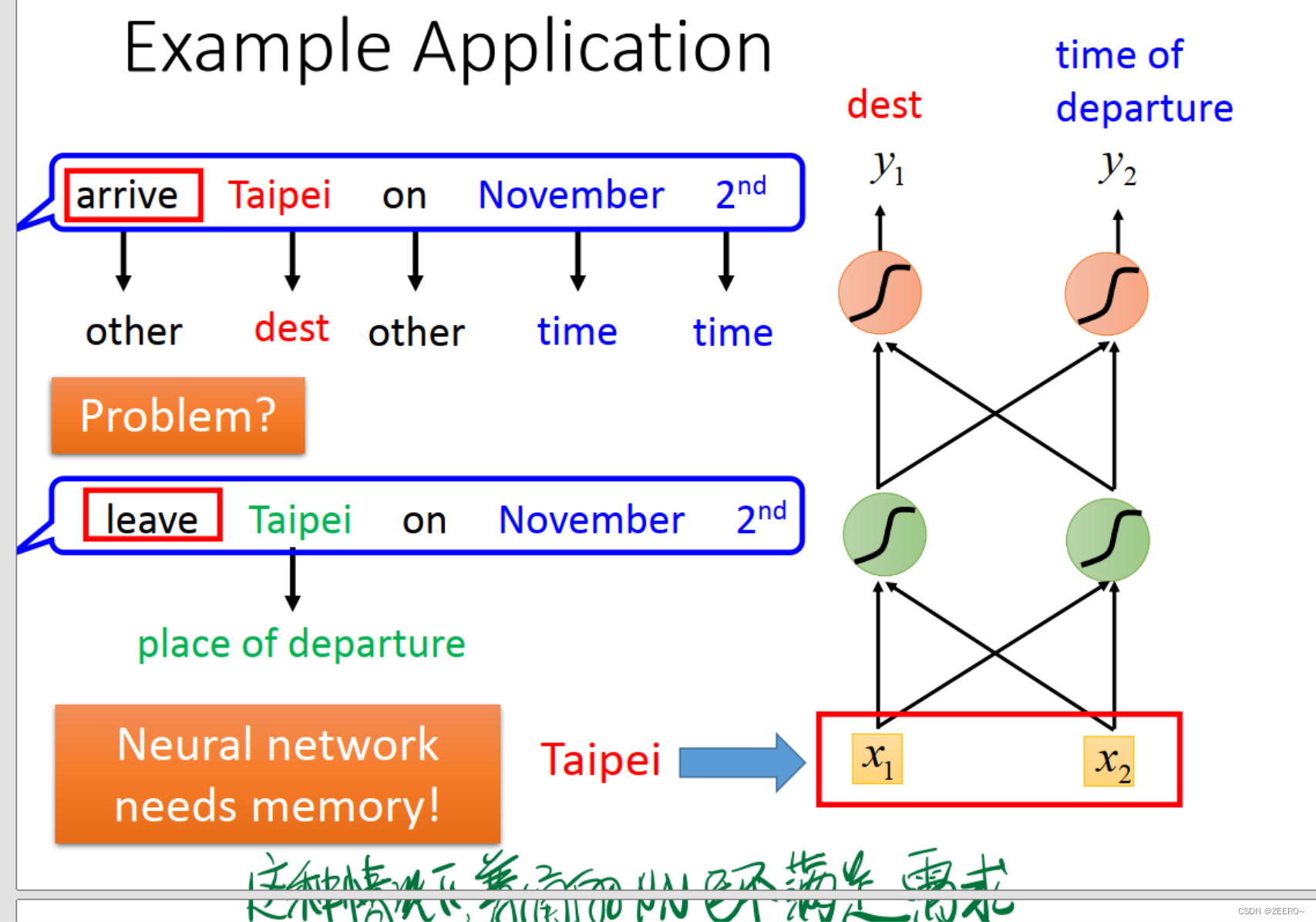
这个时候,我们所构建的NN则是需要有记忆的,否则无法解决该问题。
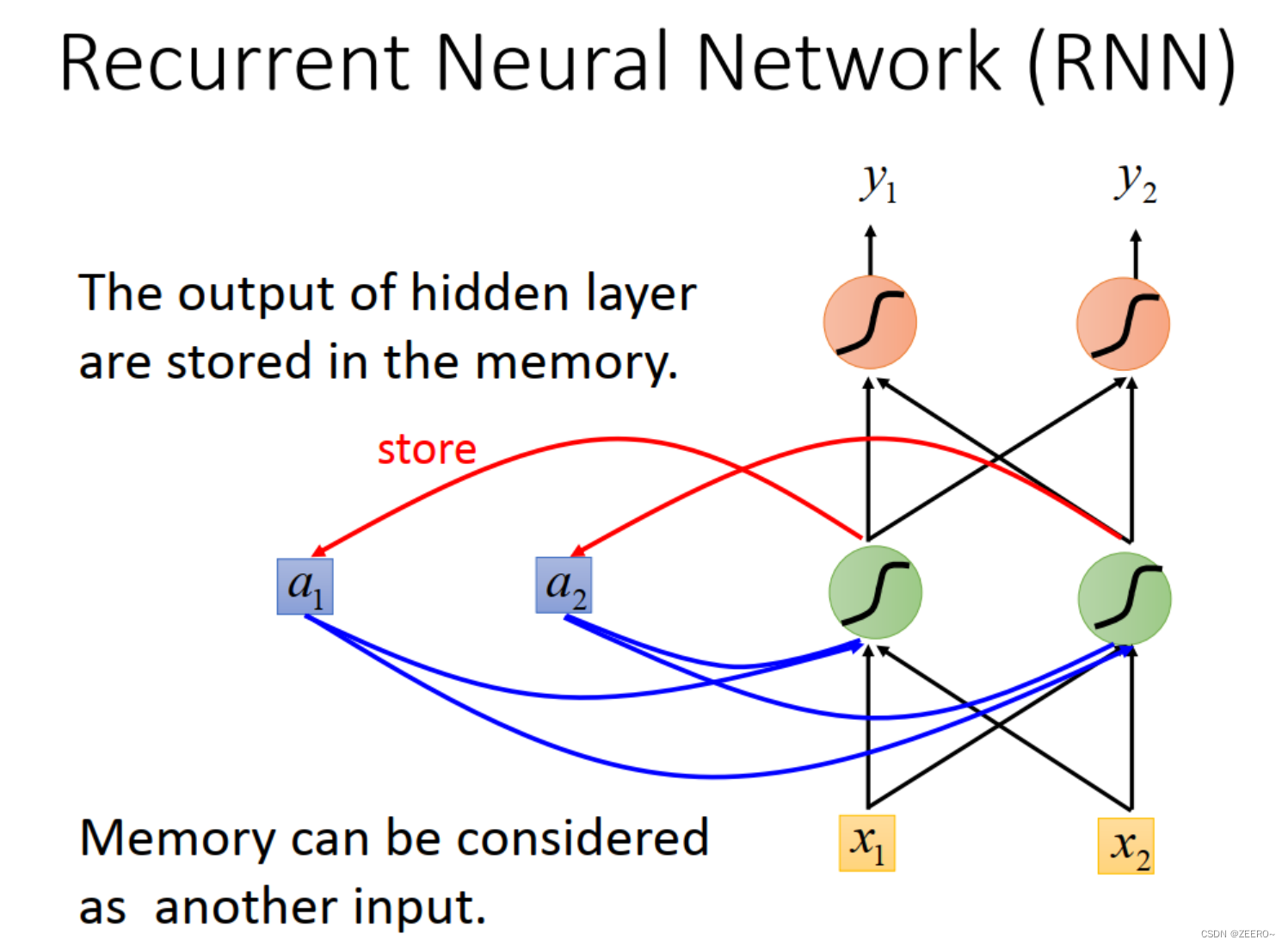
因此,我们引入了RNN来解决该问题。将每次hidden layer的输出先储存到memory cell中,作为下个词汇向量的输入。不断循环该过程。
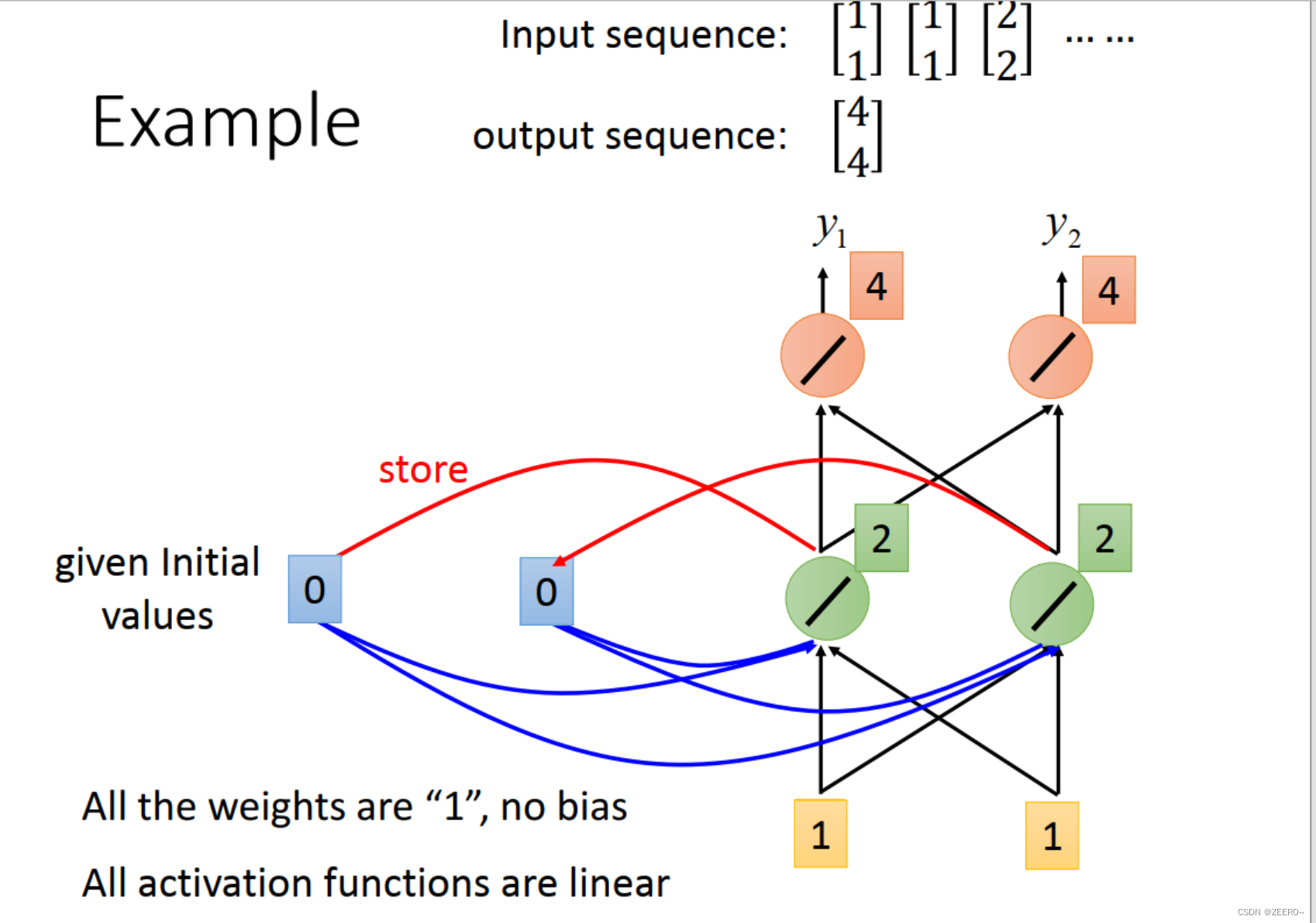
举例来说,我们输入的第一个向量为[1,1],则hidden layer的输出为[2,2],先被储存起来,输出为[4,4]。
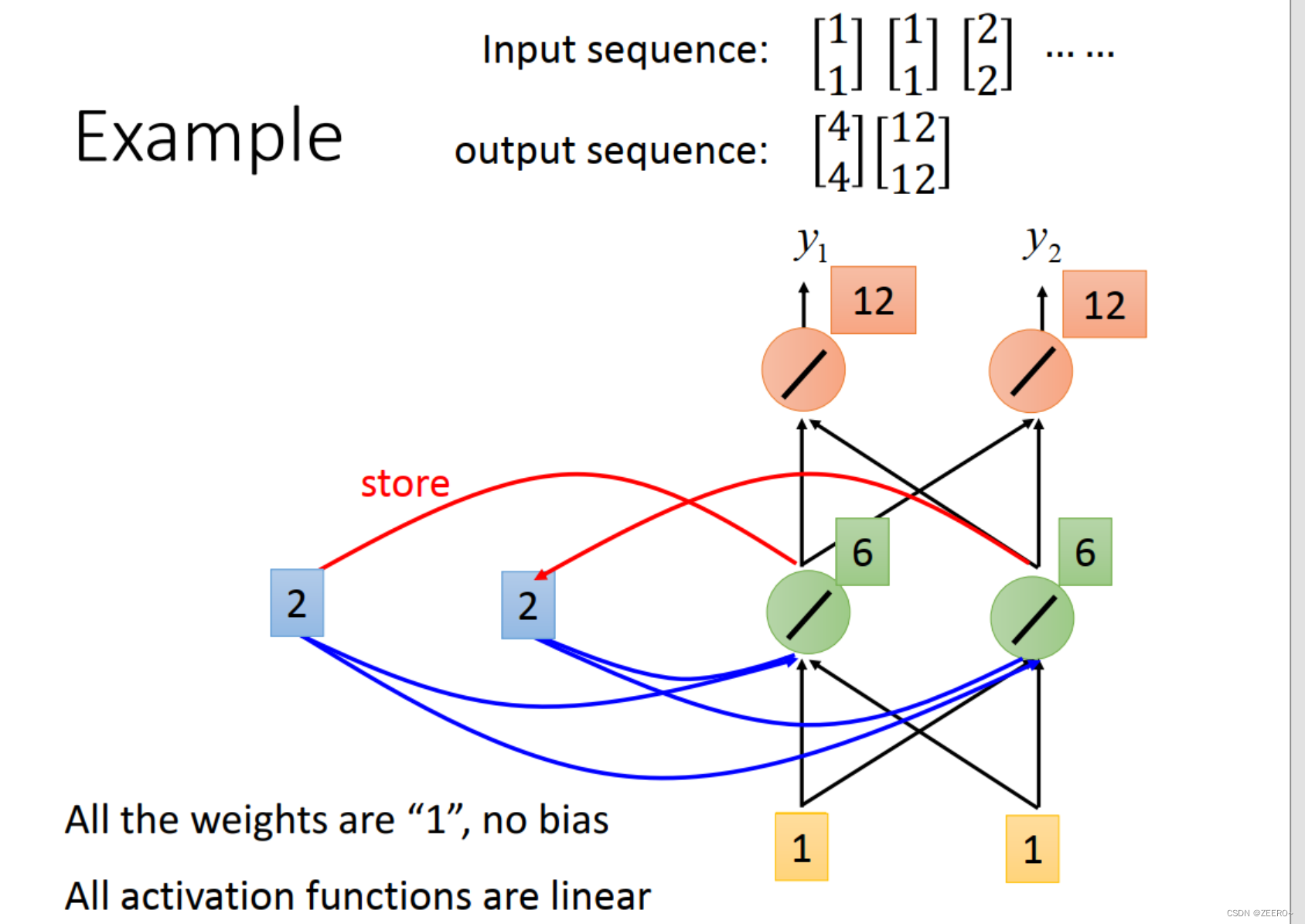
第2个输入仍然为[1,1]。这个时候结合前一个memory的输出[2,2],hdden layer的输出为[6,6],output为[12,12]。
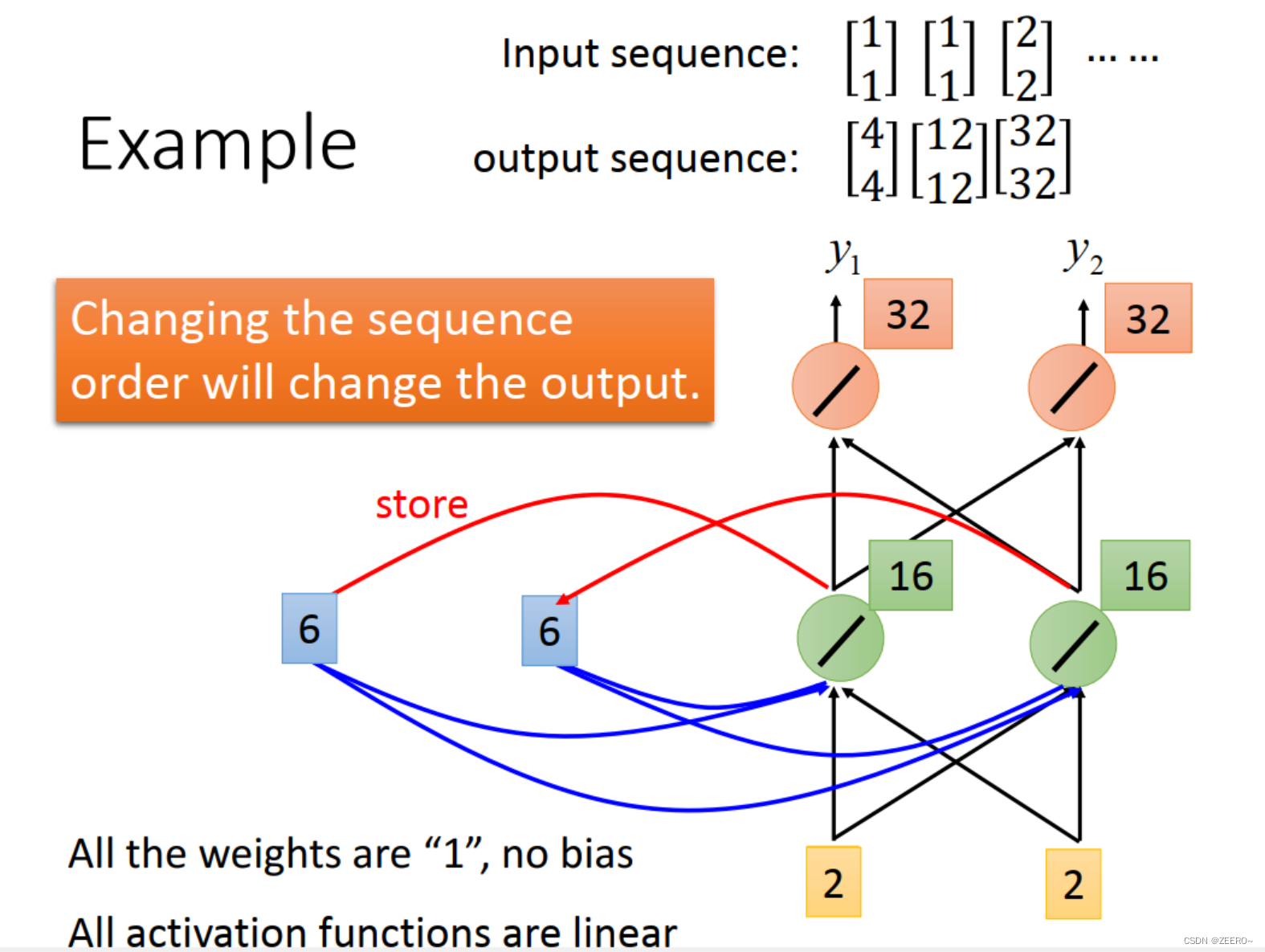
第3个输入为[2,2],结合前一个memory的输入为[6,6],这个时候hidden layer的输出为[16,16],output为[32,32]。
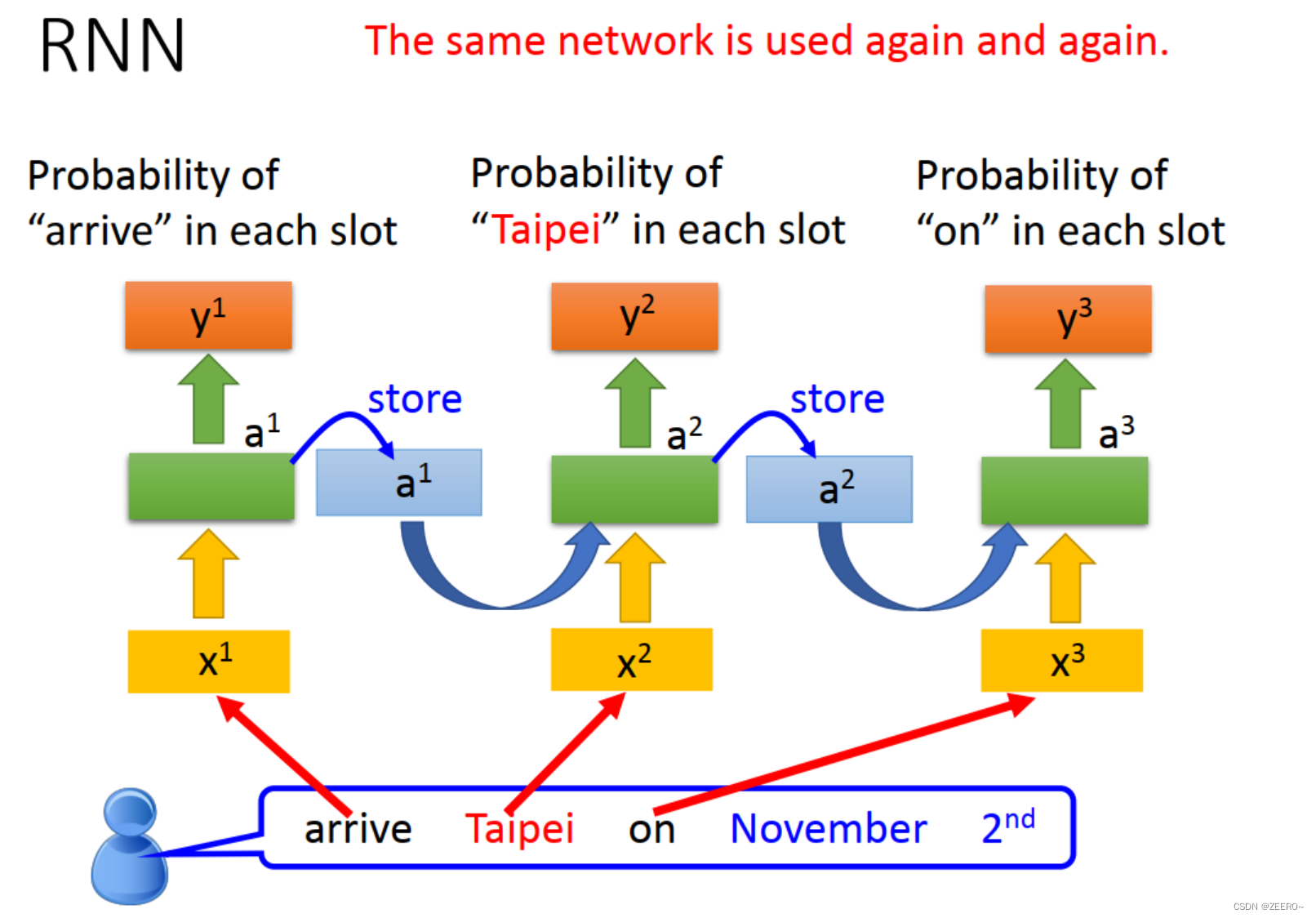
RNN的网络结构如上图所示,重复利用了同一种相同的网络结构。
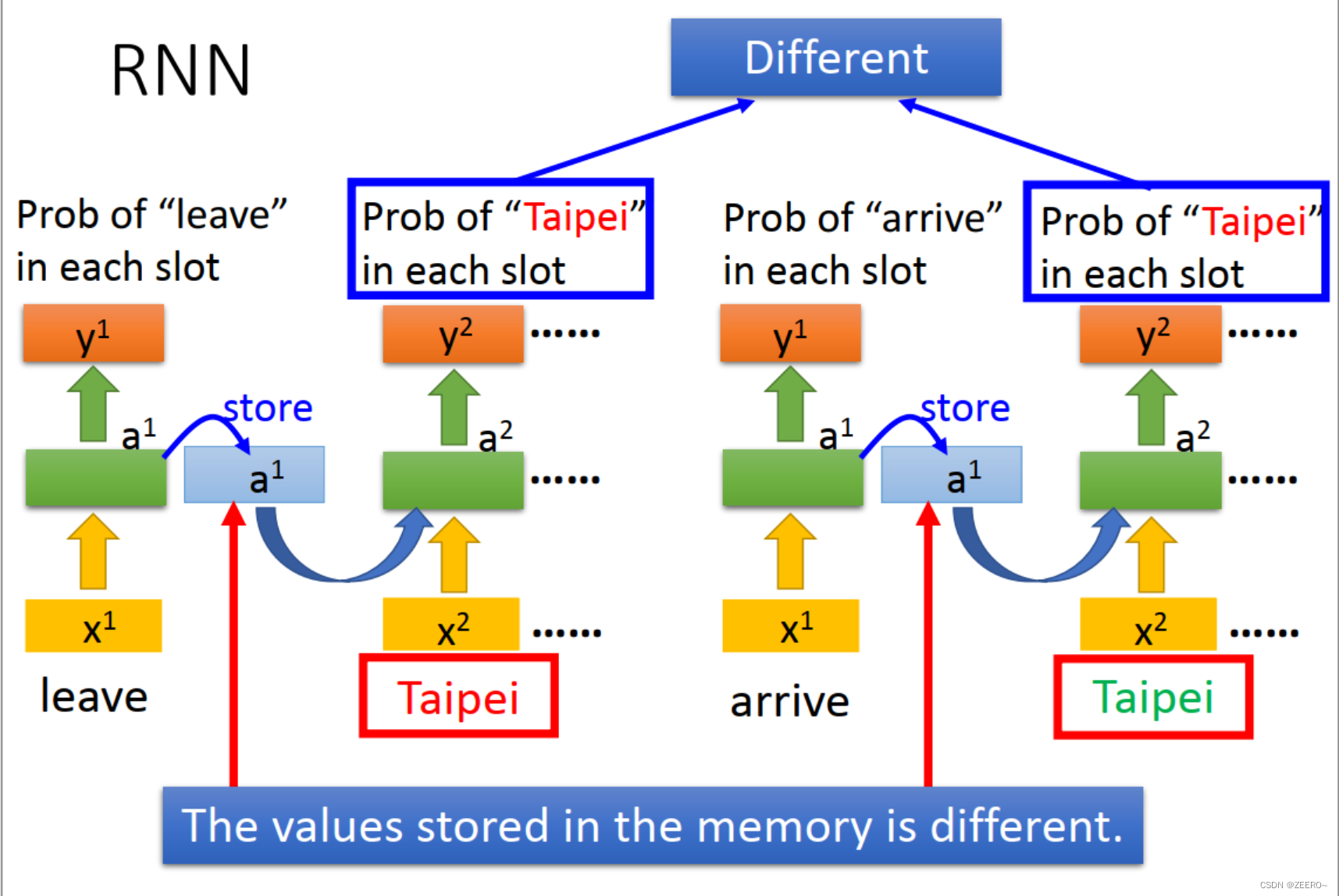
每次储存在memory中的值并不相同。
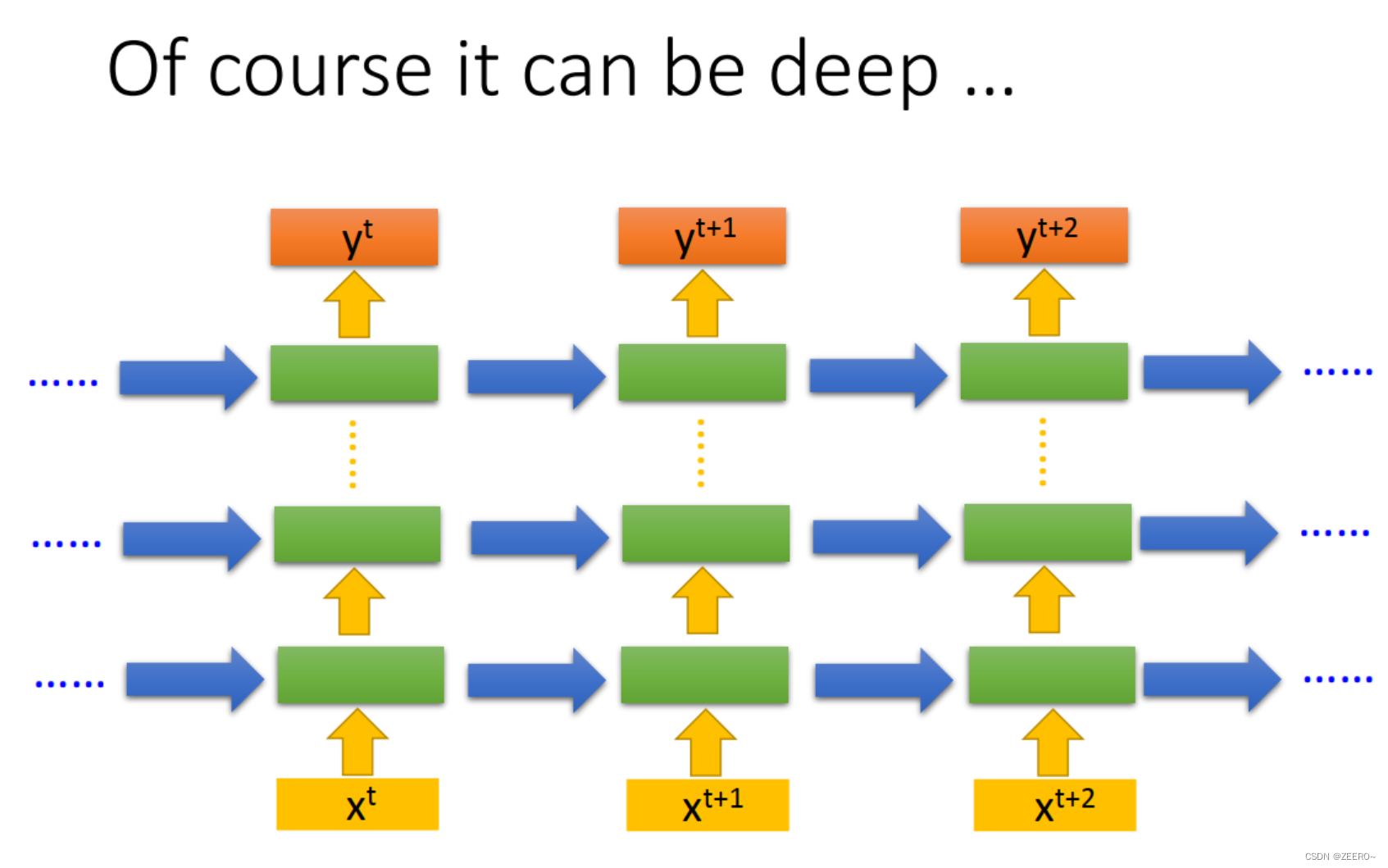
当然,也可以把hidden layer的层数加深。
3种典型的RNN网络结构
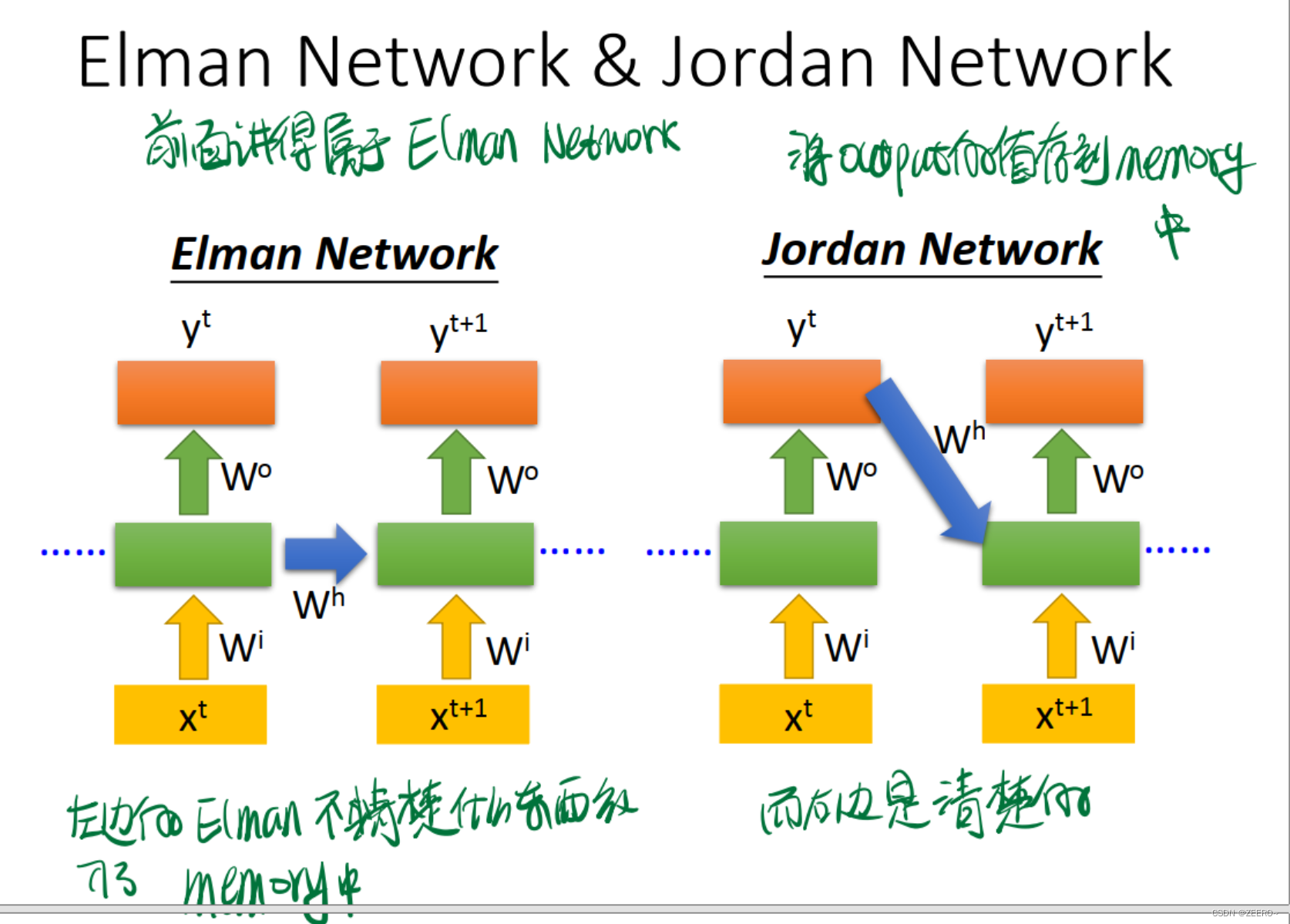
Jordan Network和Elamn Network的区别在于是将每个output的值作为下一个的输入。右侧的网络结构可解释性更强。
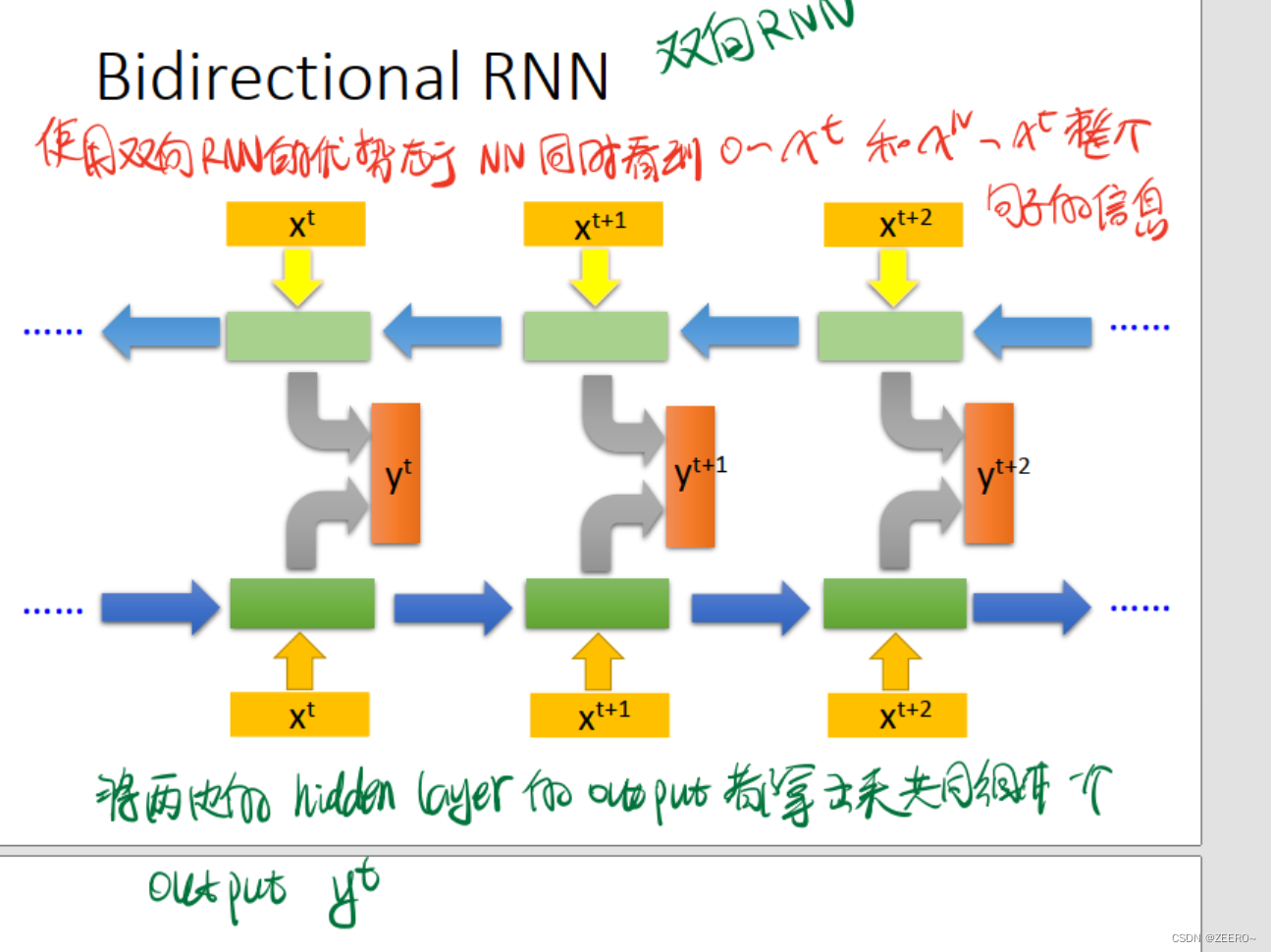
双向RNN则更为全面,同时兼顾到了前后的上下文信息,而不仅仅是前面的信息。
二、LSTM
我们在实际过程中使用更多的则是LSTM。
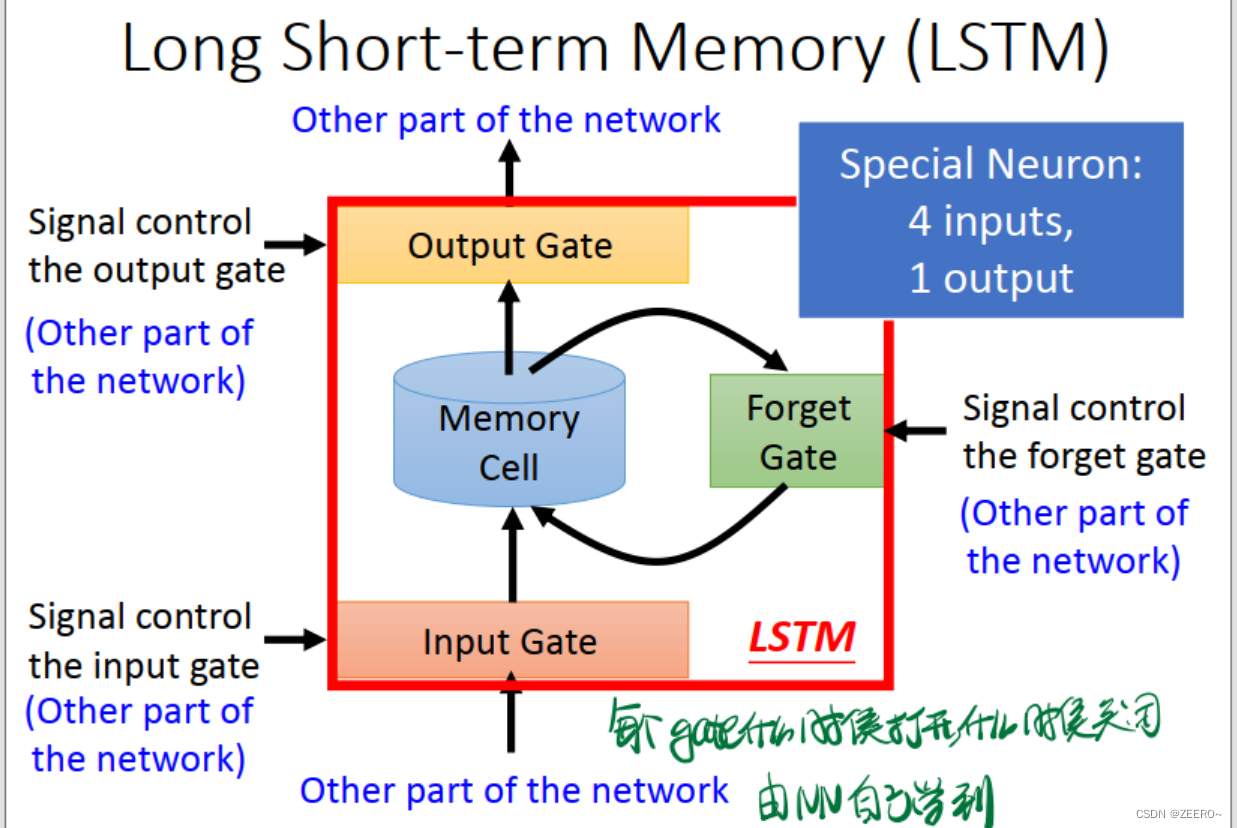
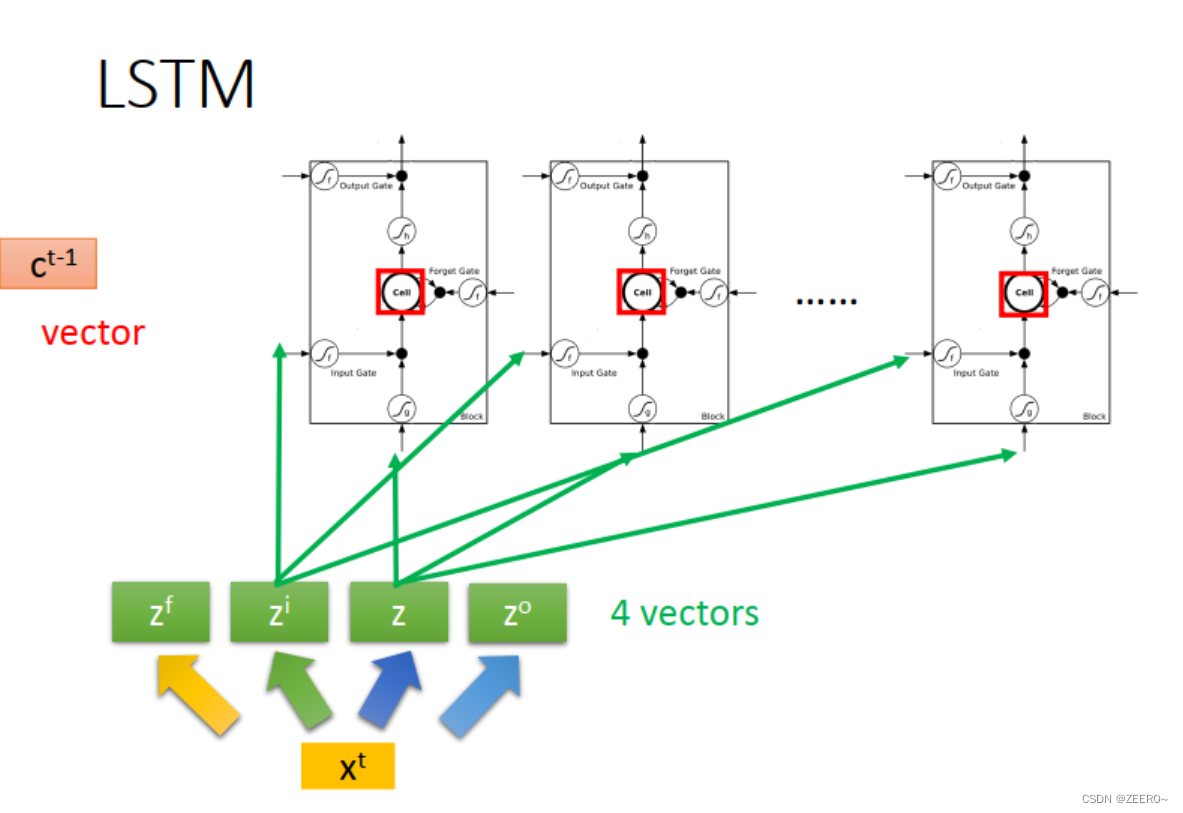
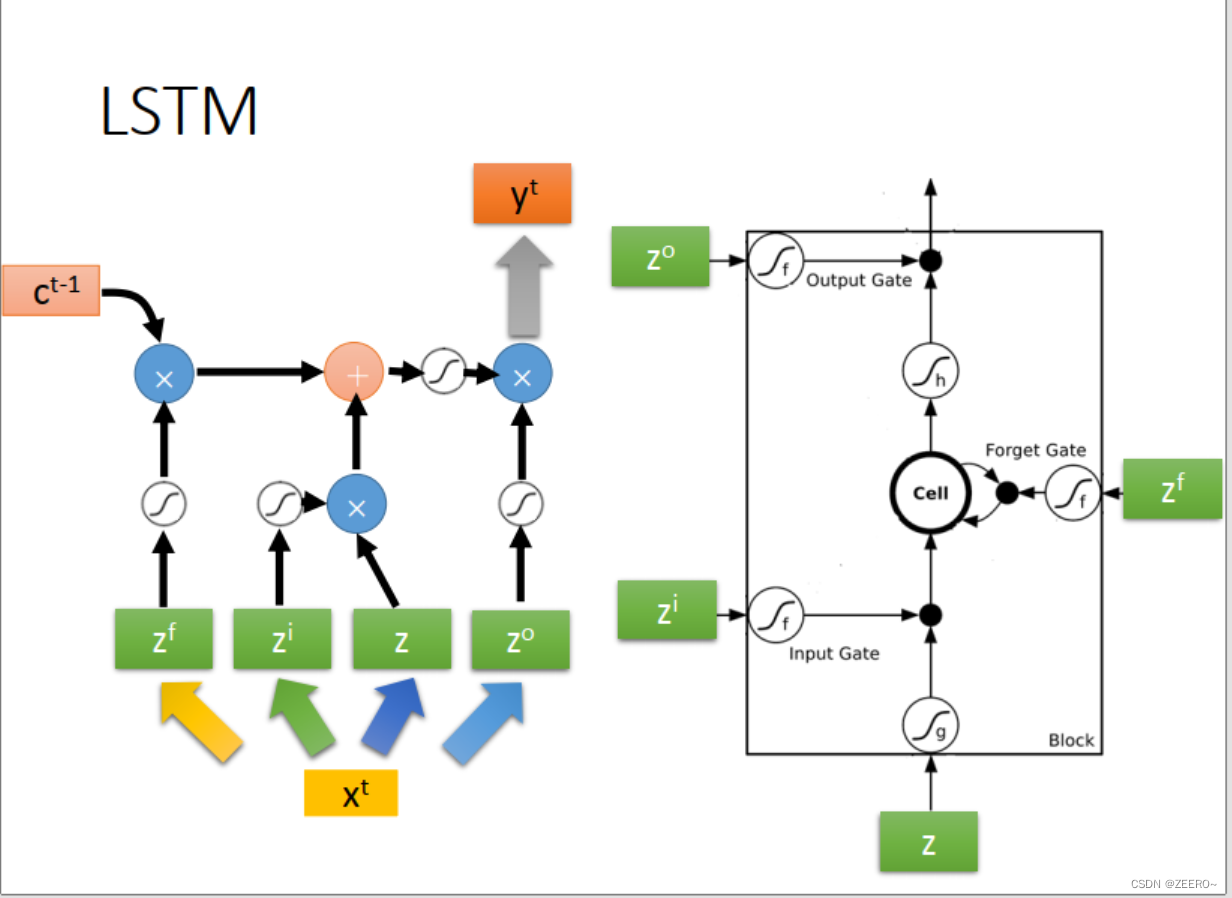
LSTM实际上,是将RNN中hidden layer的输出存入memory cell的过程稍微复杂化了一些,使用了3个gate进行代替。input gate的作用是控制输入通过,forget gate的作用是控制对memory cell中的值是否进行清空。output gate的作用是控制是否将该memory cell的值输出。
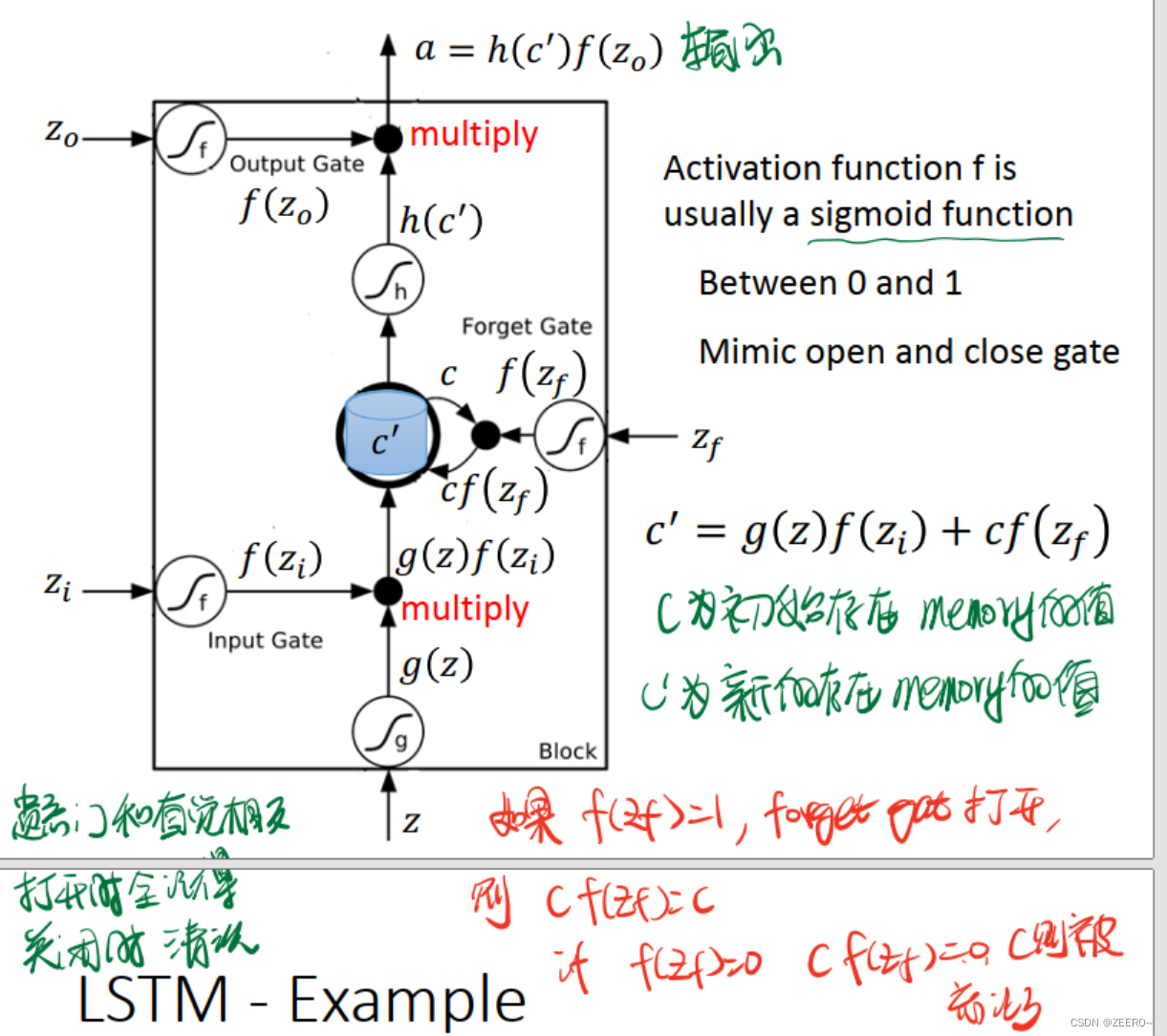
每个门的激活函数都是sigmoid函数,因为这样恰好可以将输入值映射到(0,1)之间。0表示不允许通过,1表示可以通过。
这里额外说下,forget gate和直觉似乎有点相反。当 f ( z f ) = 1 f(z_{f})=1 f(zf)=1时,表示forget gate打开,但是 c f ( z f ) = 1 cf(z_{f})=1 cf(zf)=1,c表示前一个memory cell的值, c ′ c' c′表示本次计算出来的值。这个时候,前一次计算出来的c的信息完全没有被forget。因此,forget gate打开时,不是表示forget,而是表示unforget。
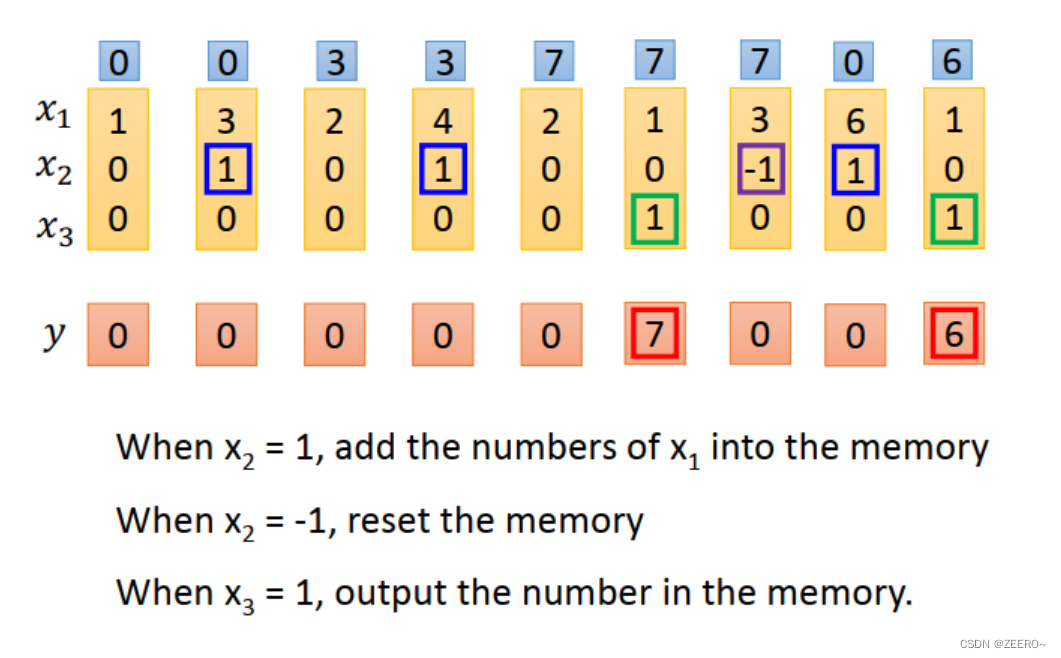
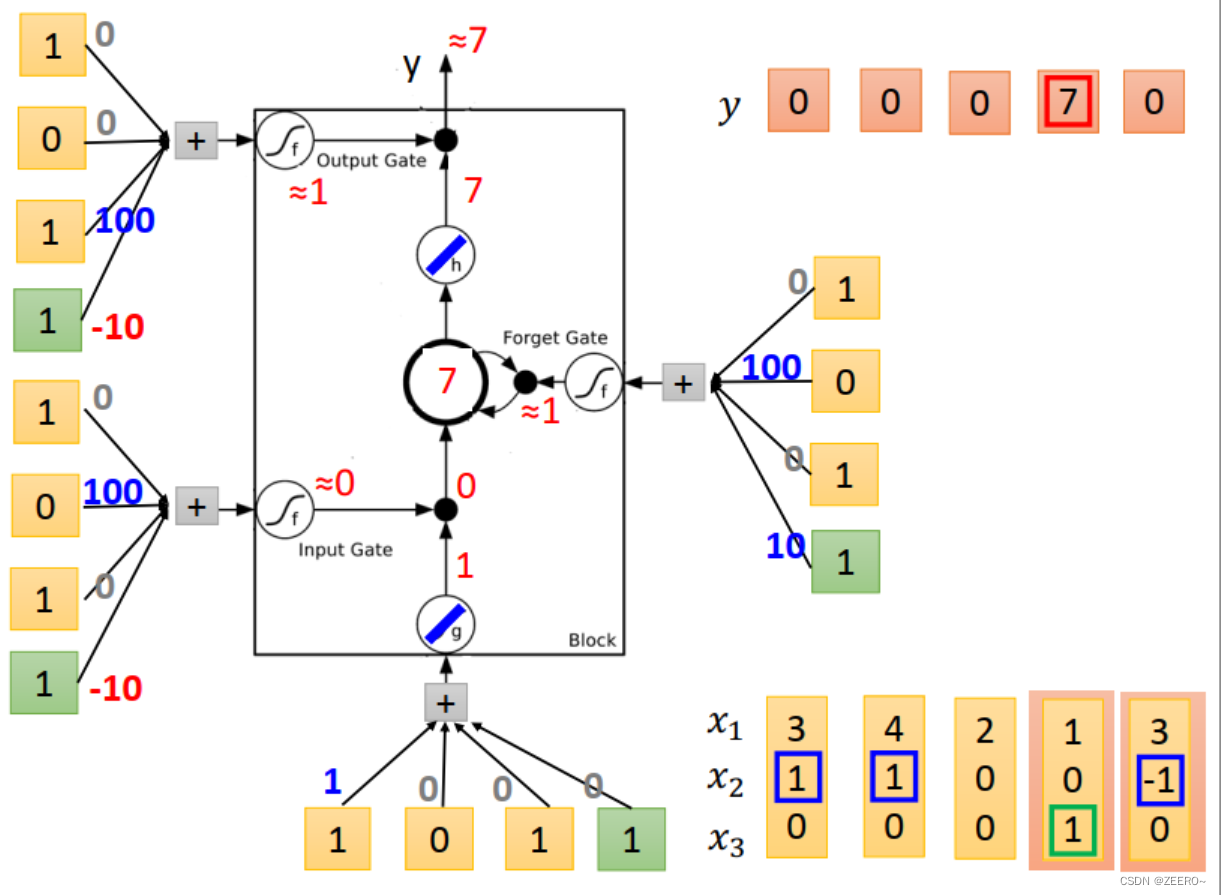
举例来说,假如想设计一个LSTM网络,实现上面的功能。
当x2=1时,将x2的值写入到memory中。memory时最上面蓝色框的值。
当x2=-1时,将memory中的值进行reset。
当x3=1时,将memory中的值进行输出。
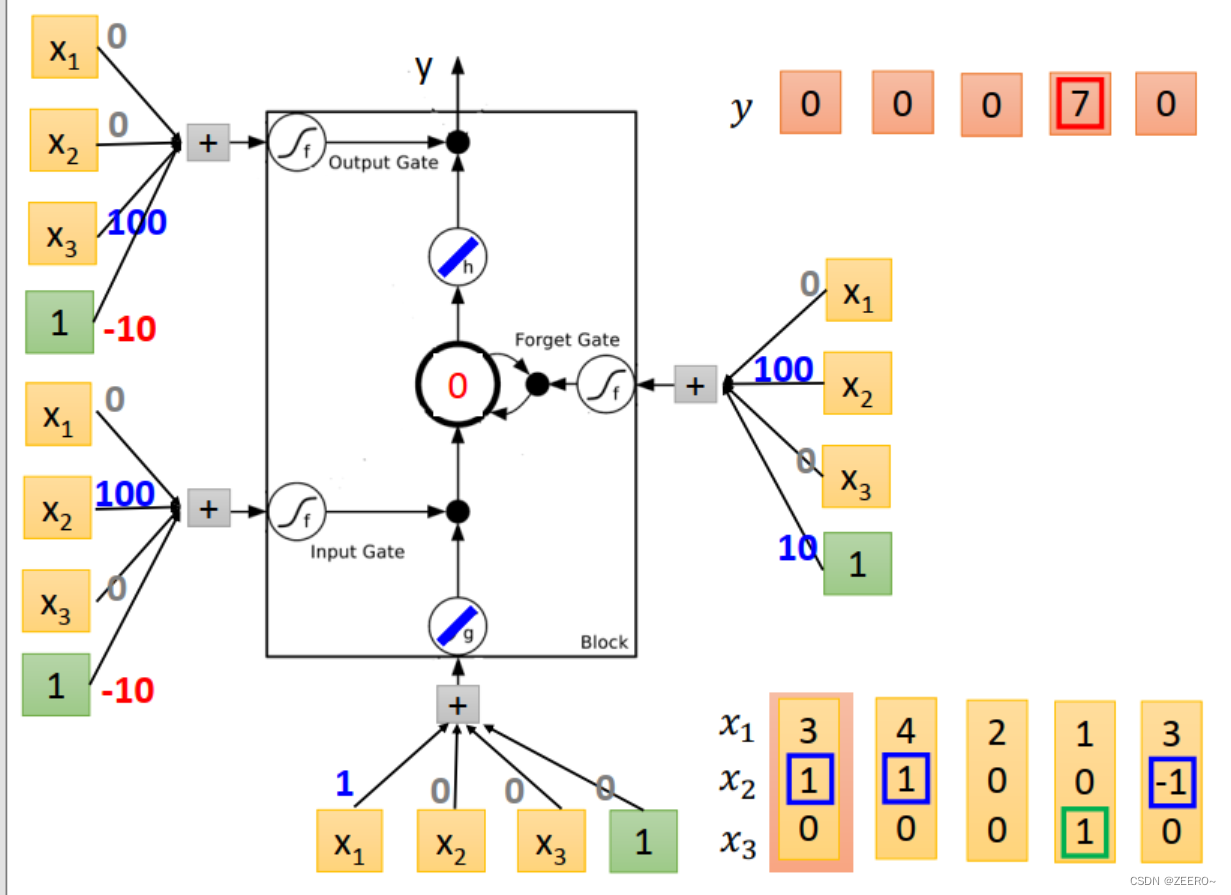
我们设计的NN结构如上图所示。输入乘的4个weight为[1,0,0,0]。input gate控制信号为输入与[0,100,0,-10]相乘,依次类推。
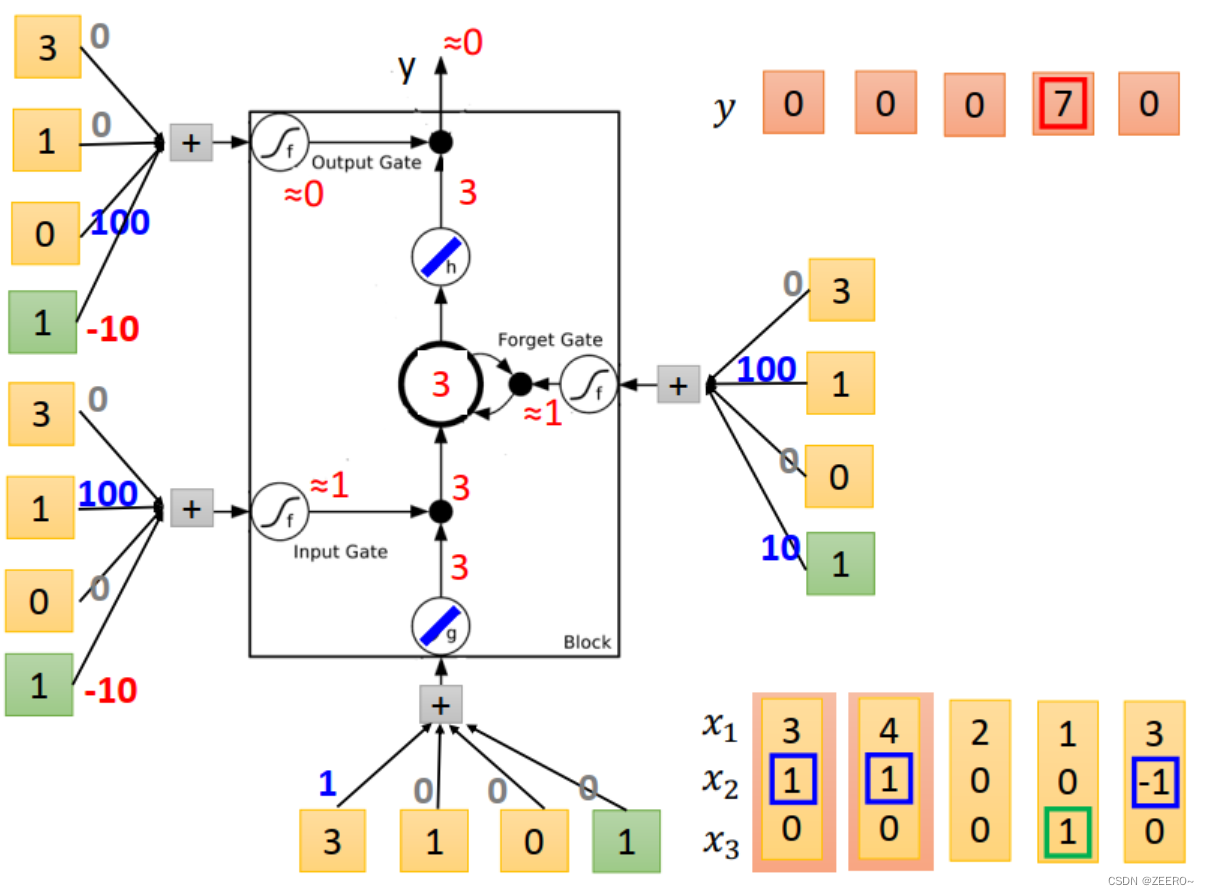
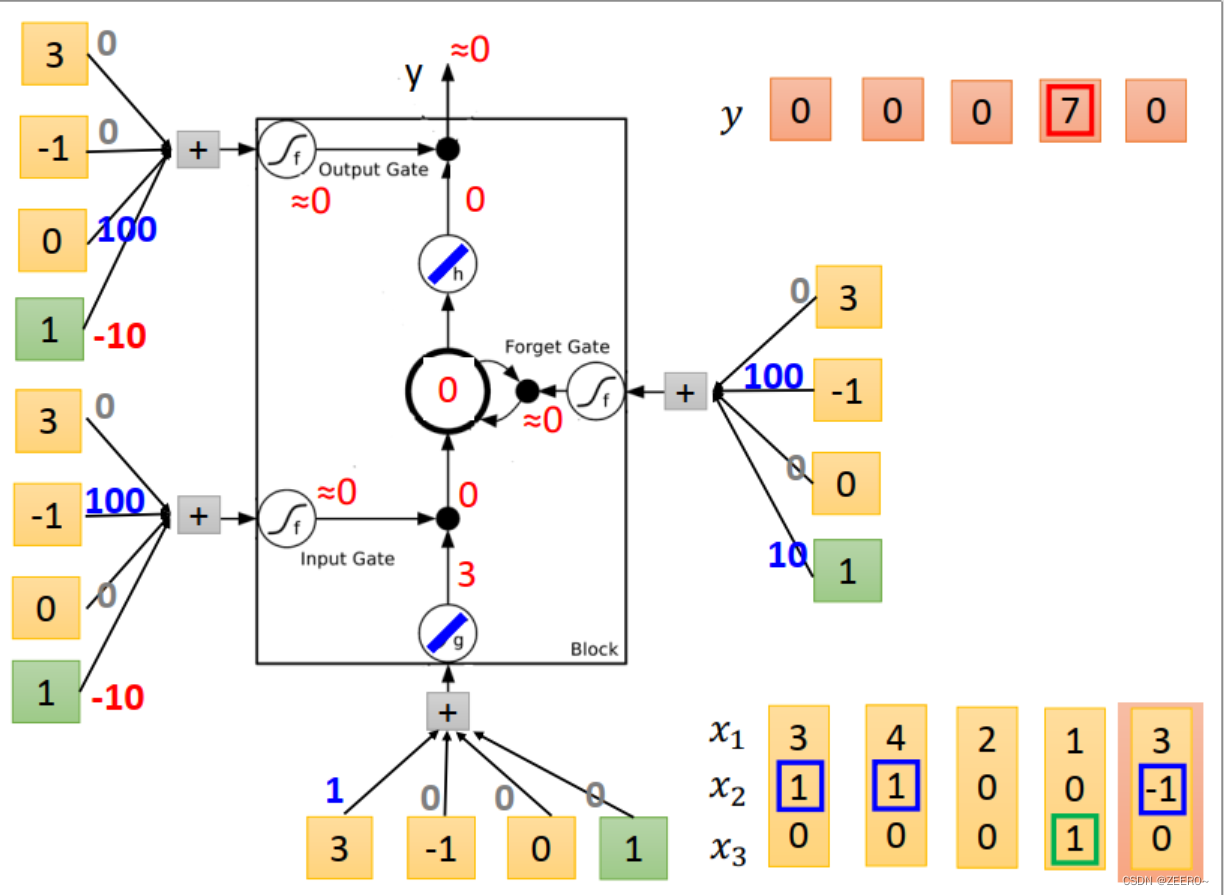
当输入为[3,1,0]时,input的值为3,input gate的值为1,multiply之后得到3.forget gate 的值为1,与前一个memory cell的值0相乘后再加3得到3,outputgate 的值为0,因此输出为0,memory cell的值更新为3,为本次运算的结果。

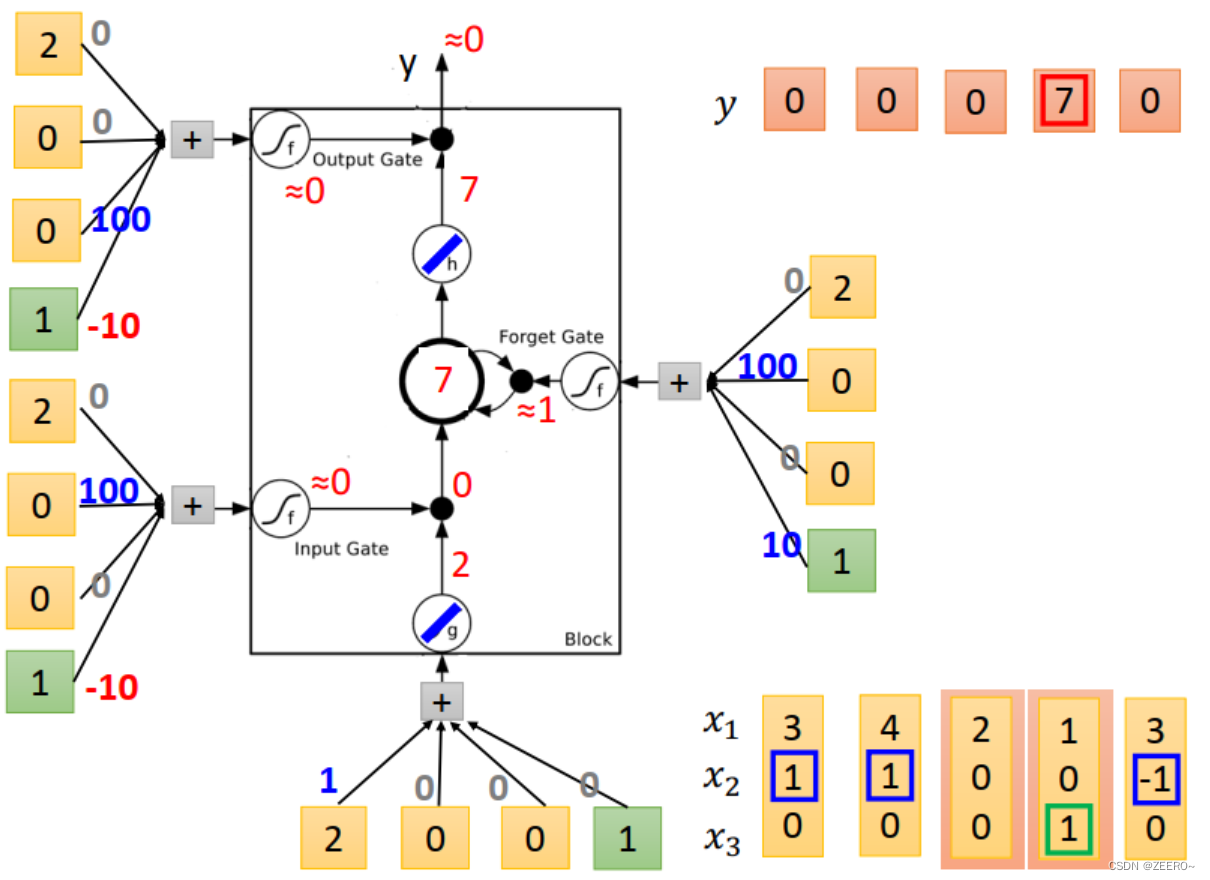
当输入为[4,1,0]时,input 的值为4,input gate=1,multiply之后得到4,forgat gate =1,与 C t − 1 = 3 C_{t-1}=3 Ct−1=3相乘后+4=7,forget gate的值为0,因此output=0,memory cell更新为7.
LSTM和普通NN、RNN区别
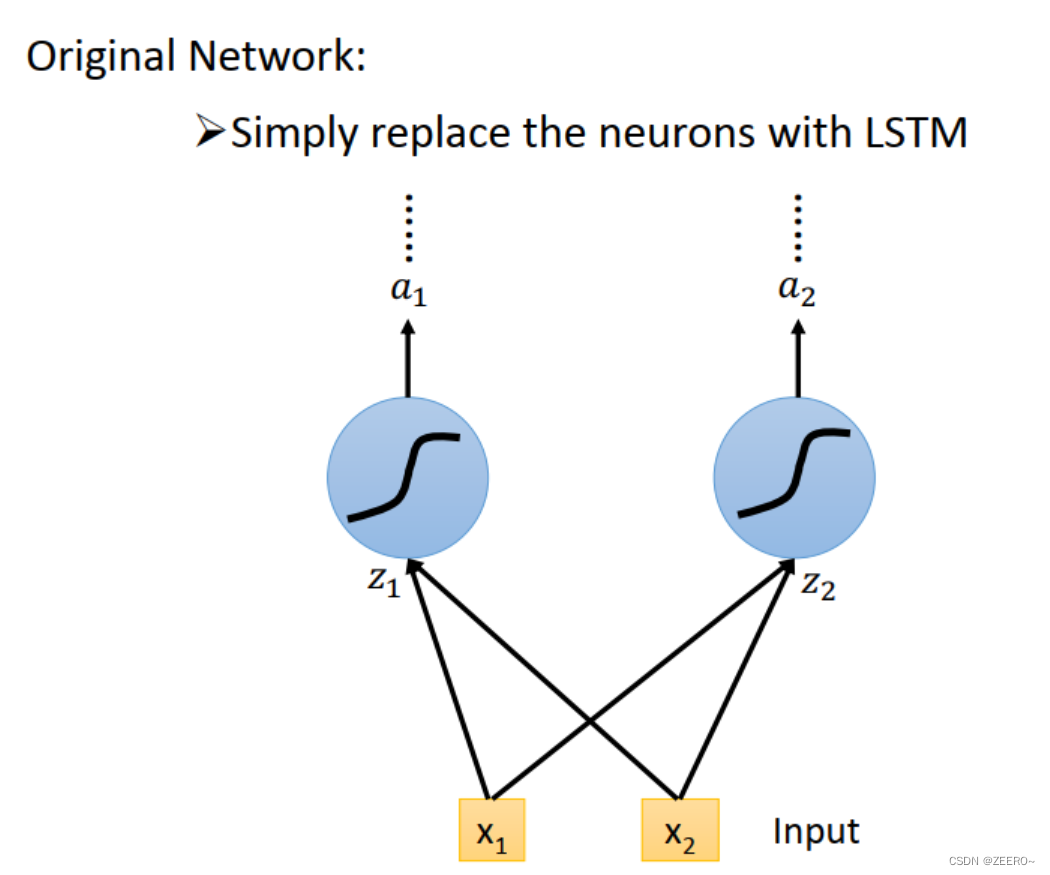
前面已经讲述过,LSTM可以看作是将普通的hidden layer替代成由4个输入控制的cell。
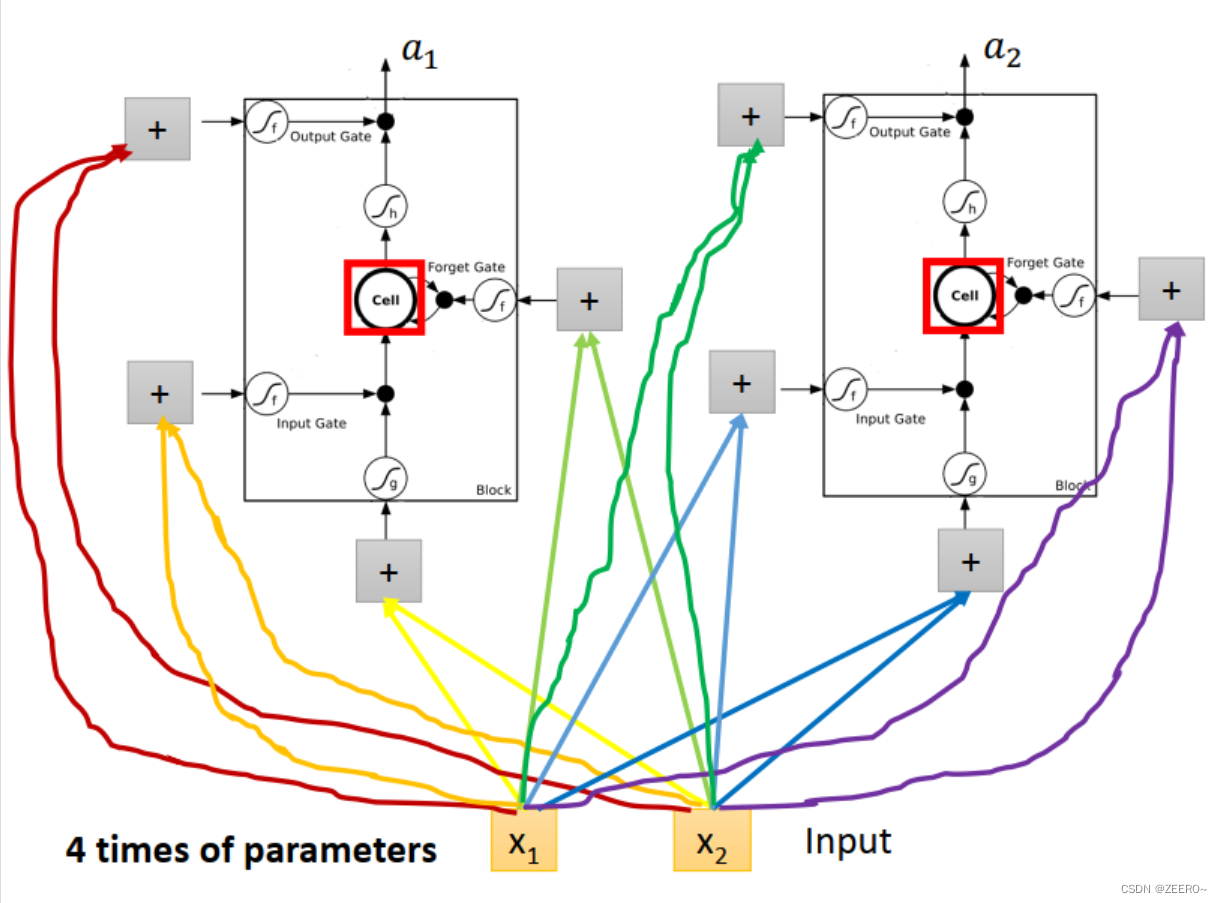
将输入[x1,x2]分别乘上不同的matrix后输入,用于控制input ,input gate,forget gate,output gate。因此,LSTM网络结构的参数量是普通NN的4倍。
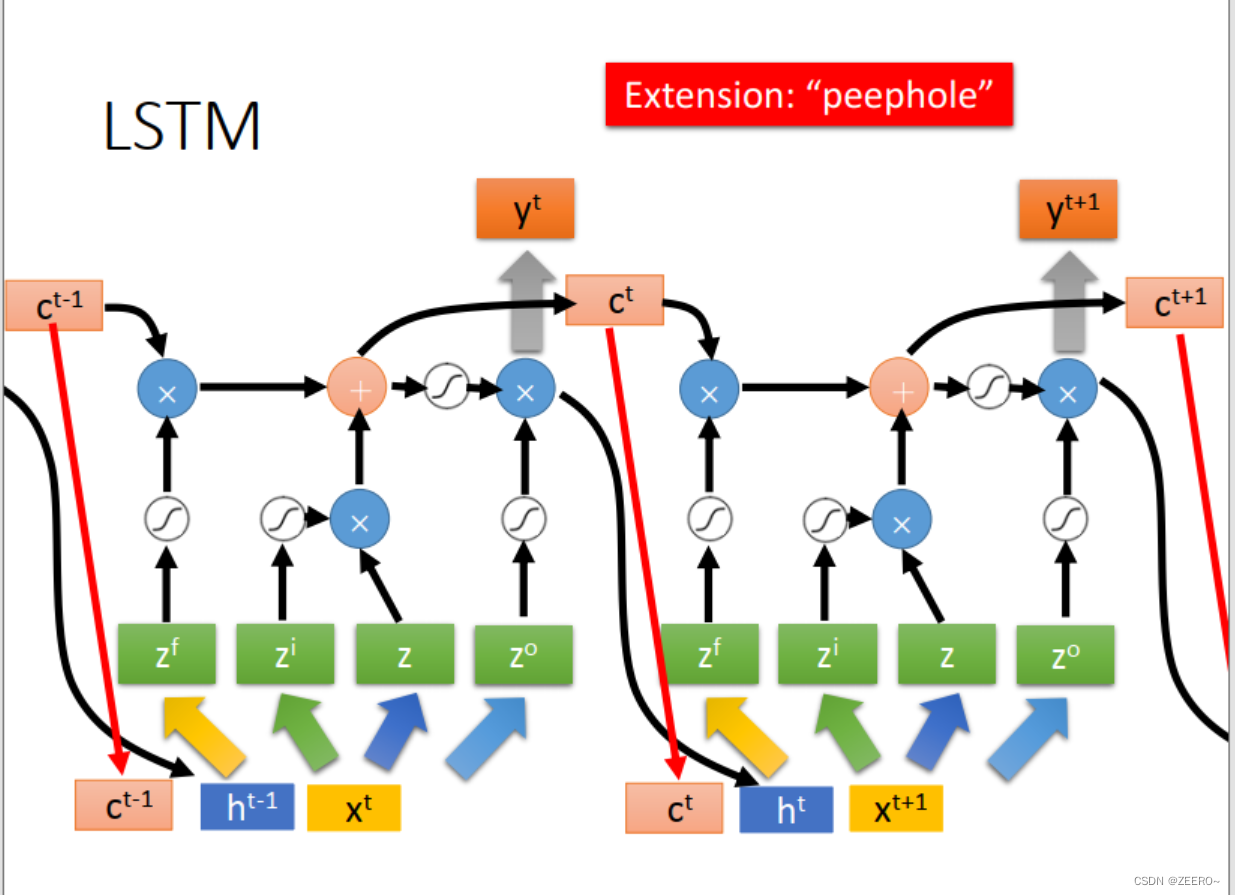
这里,peephole,指的是,在实际LSTM网络结构设计中,会将前一时刻的memory cell的值ct,输出ht的值一并加入到下一时刻作为输入。
这里LSTM虽然看起来很复杂,但是在实际中往往这是最标准化的设计。我们可以借助工具来实现它。
三、 RNN的训练
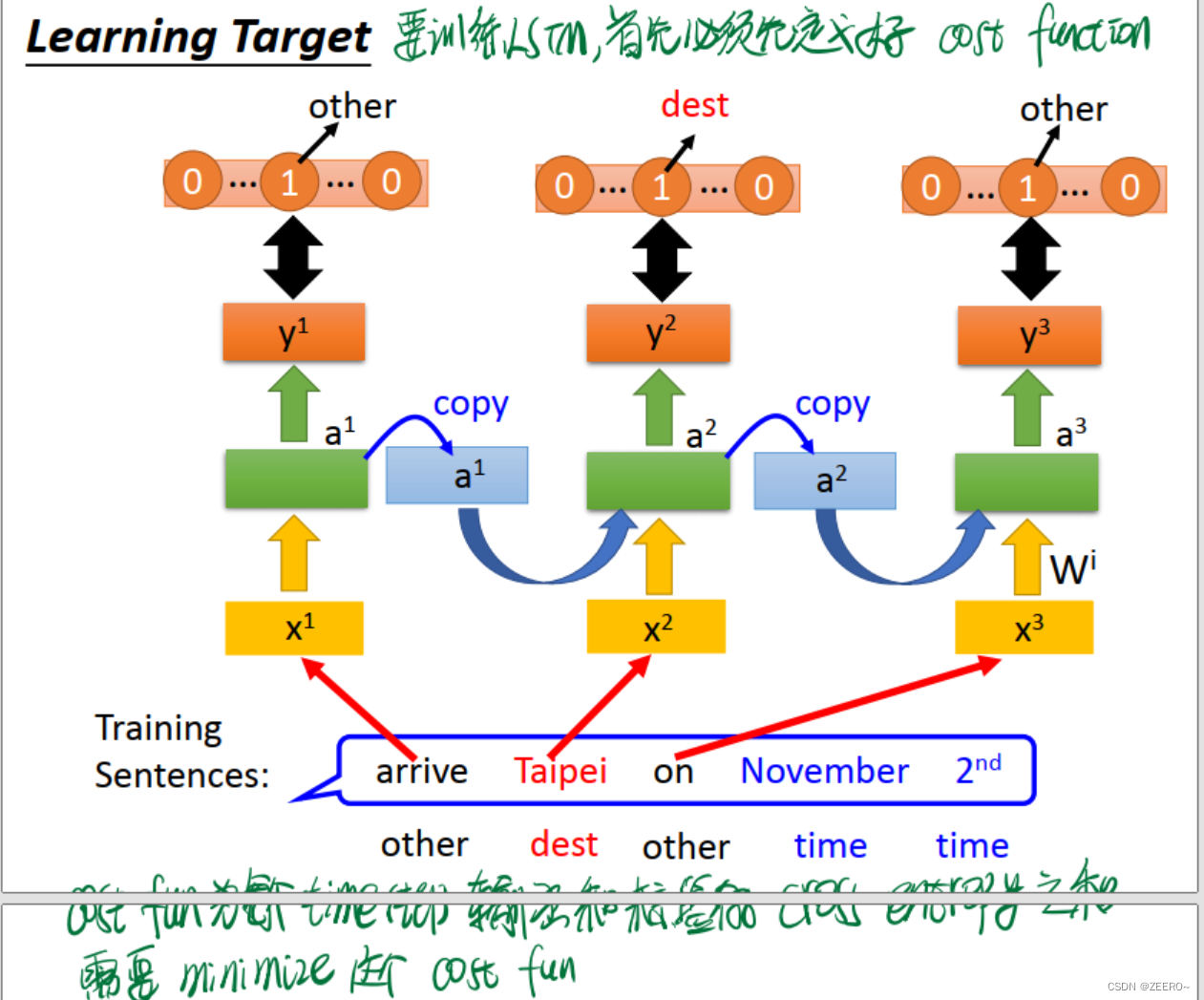
如果需要train一个RNN,则必须首先定义好cost function。很显然,这里RNN的cost function为每个time step的输出和对应标签vector的cross entropy之和,也是我们需要minimize的函数。
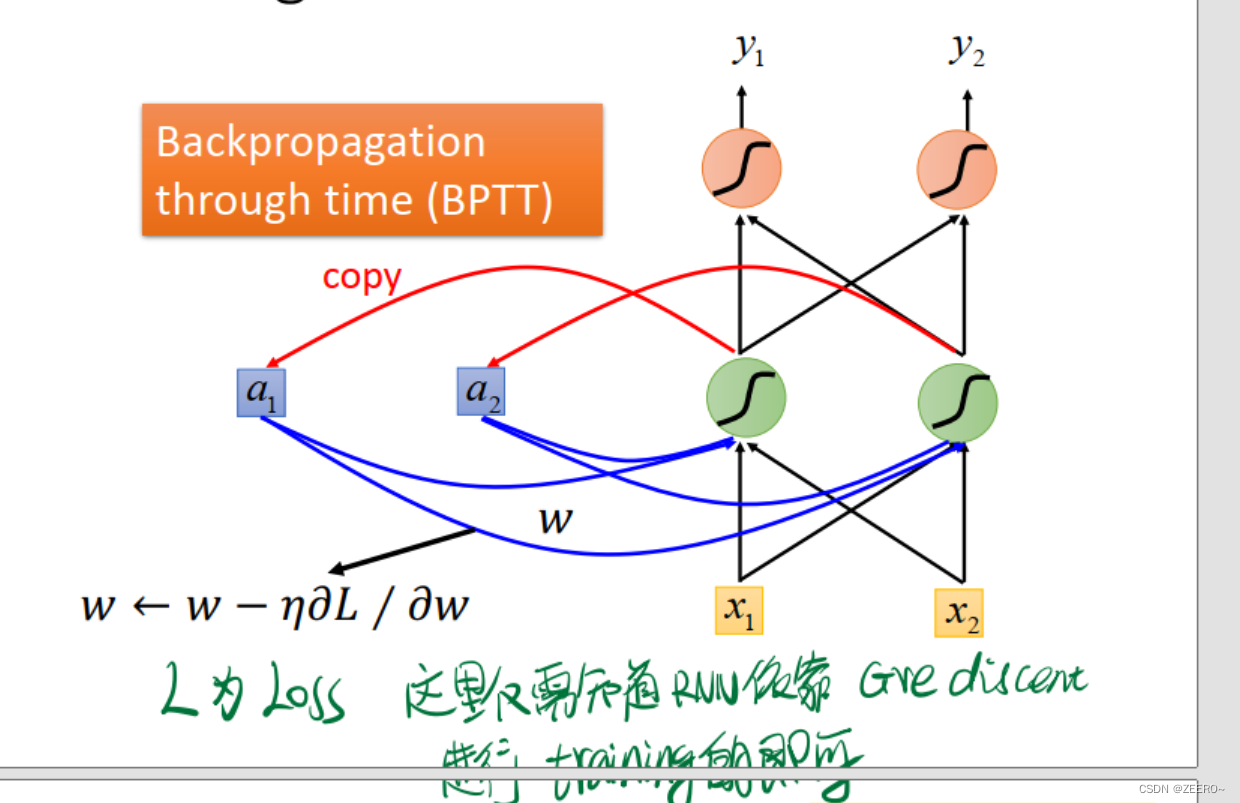
使用的方法呢,叫做BNPP(Backpropagation through time),和一般的bp有细微的区别。

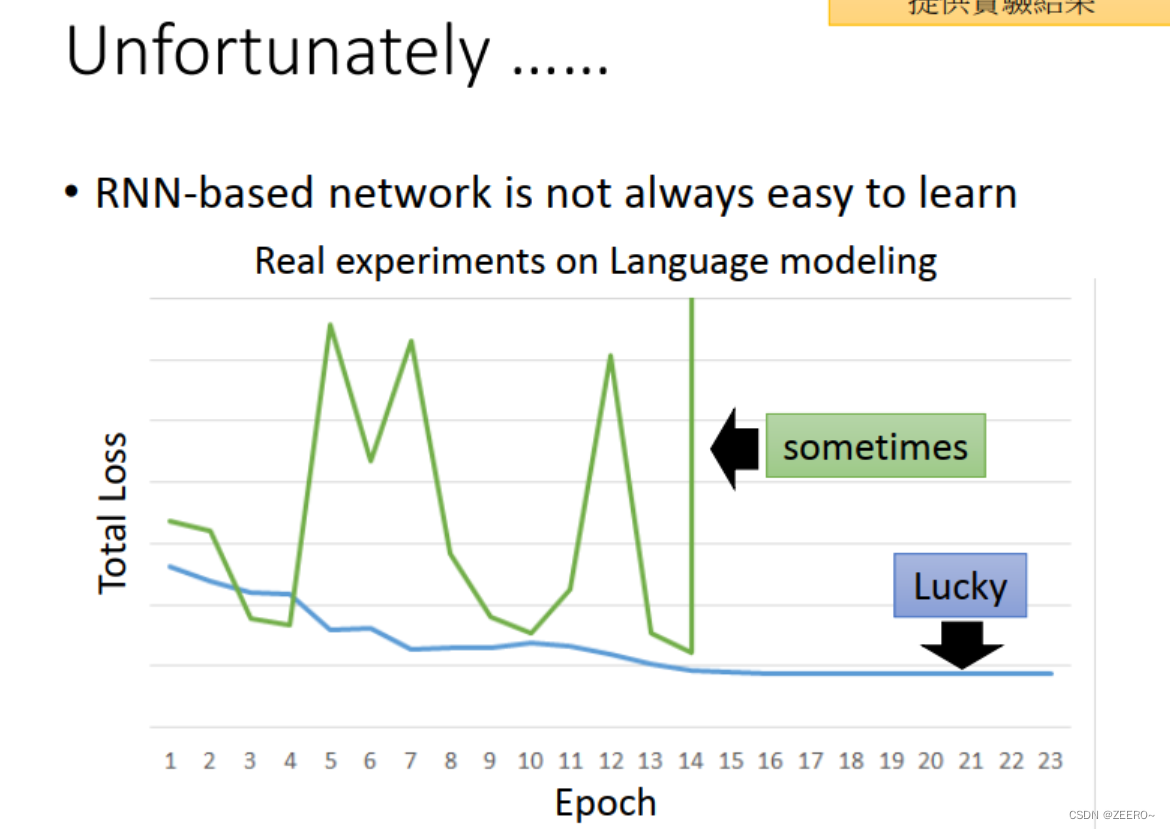
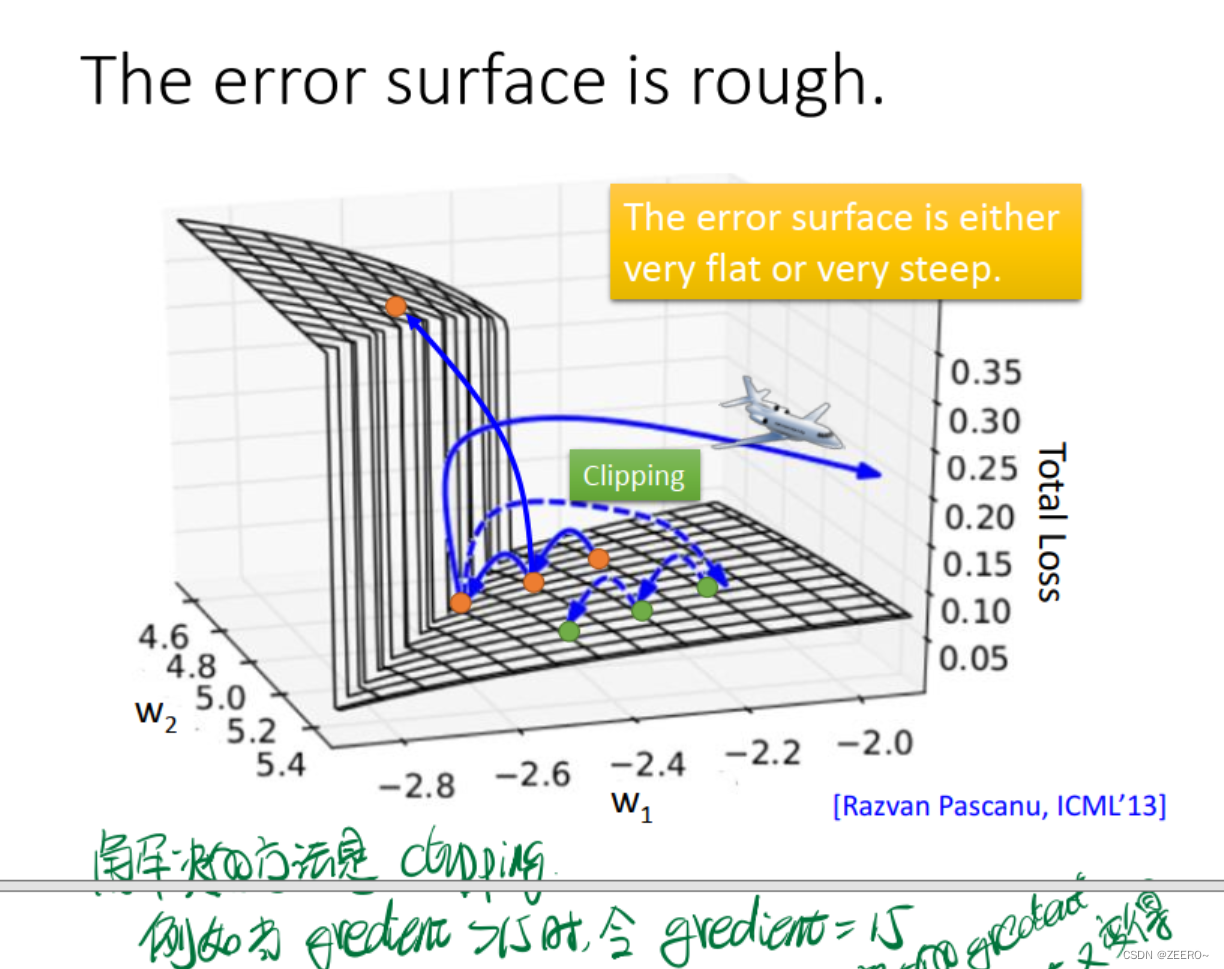
为何会出现这种情况呢,我们可以分析原因。
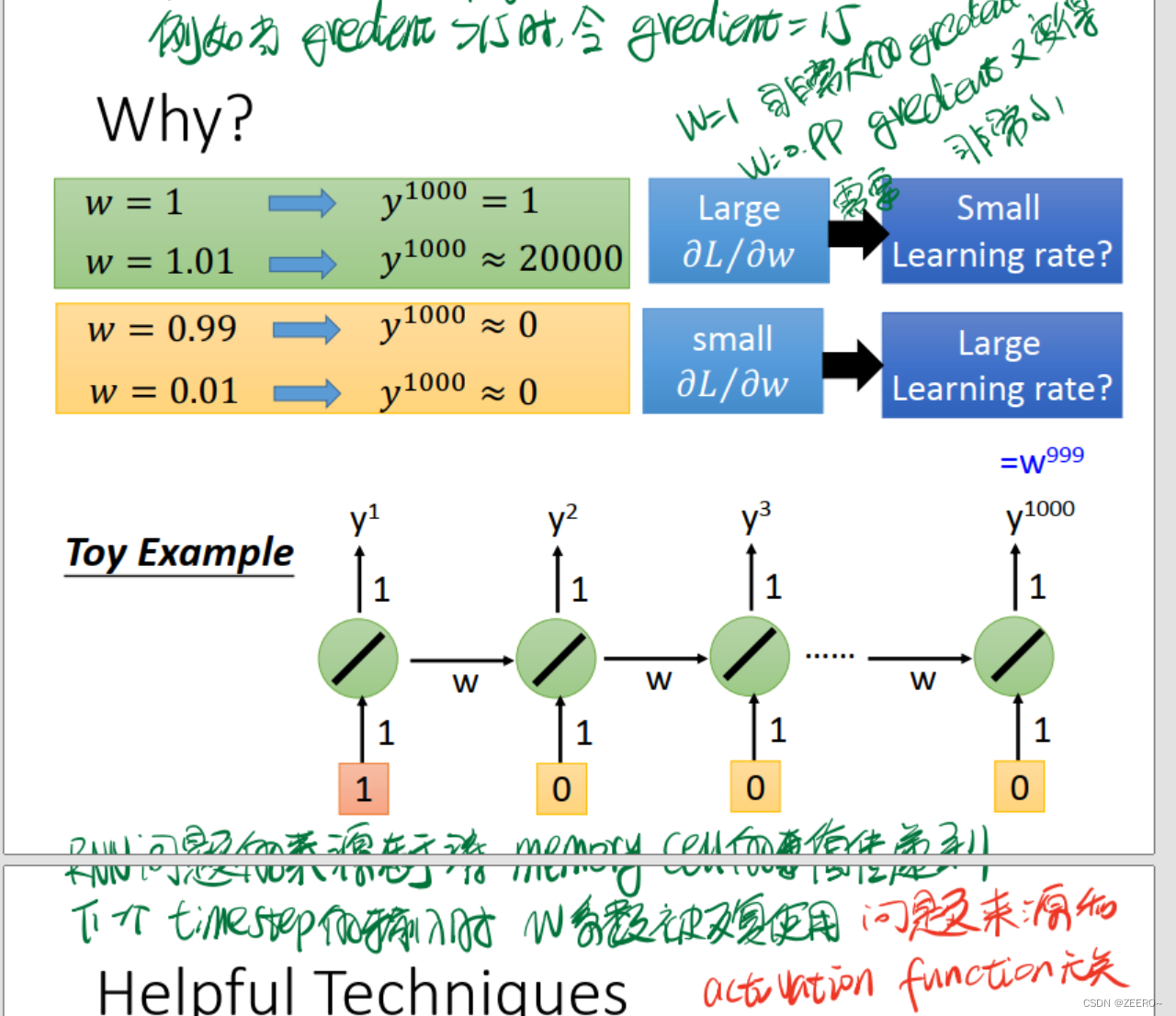
其实问题的来源,就是在于长序列导致的梯度消失或爆炸。一个非常实用的方法则是使用LSTM。
LSTM可以解决梯度消失的问题,但不能解决梯度爆炸的问题。
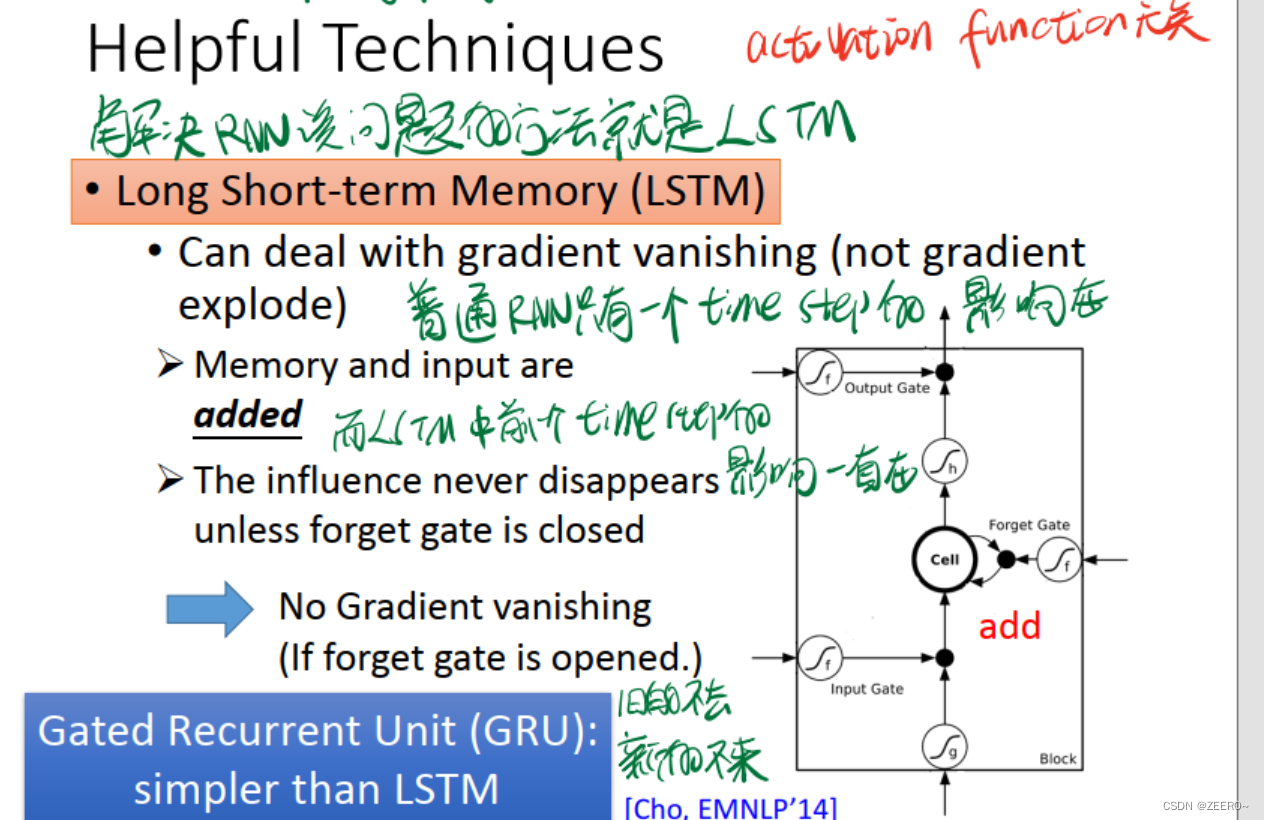
为什么LSTM可以解决梯度消失的问题呢。因为对于LSTM来说,前面每一个timestep中的信息,只要forget gate没有关闭,便会一直累加到最后。而普通的RNN,只会保留上一个timestep的信息。
一般来说,再设计LSTM网络结构时,需要做到使得大多数情况下forget gate是开启的,仅在少部分情况下forget gate会关闭。
另外一种LSTM的变种结构叫做GRU,GRU区别于LSTM,仅有2个gate。核心思想为旧的不去,新的不来。LSTM中的input gate和forget gate相互拮抗,只有forget gate关闭时,input gate才会打开。forget gate打开时,input gate则会关闭。
RNN与auto encoder和decoder

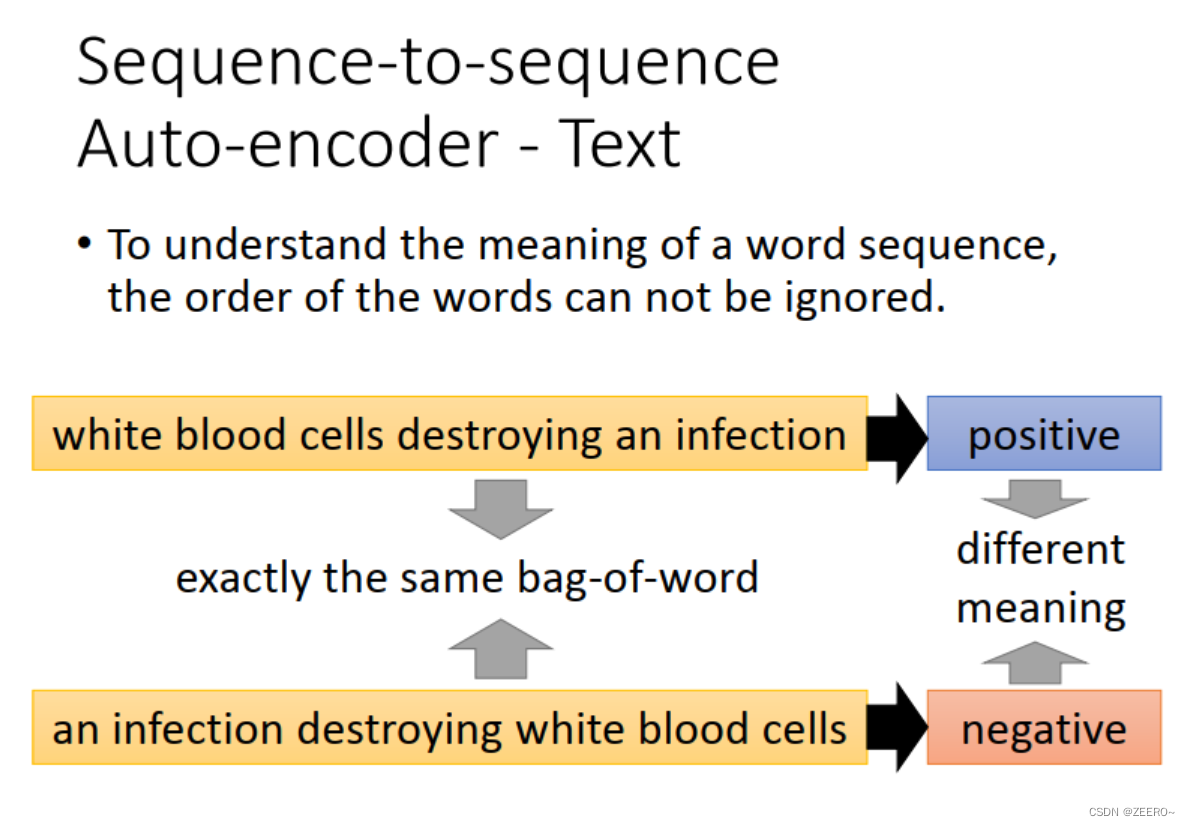
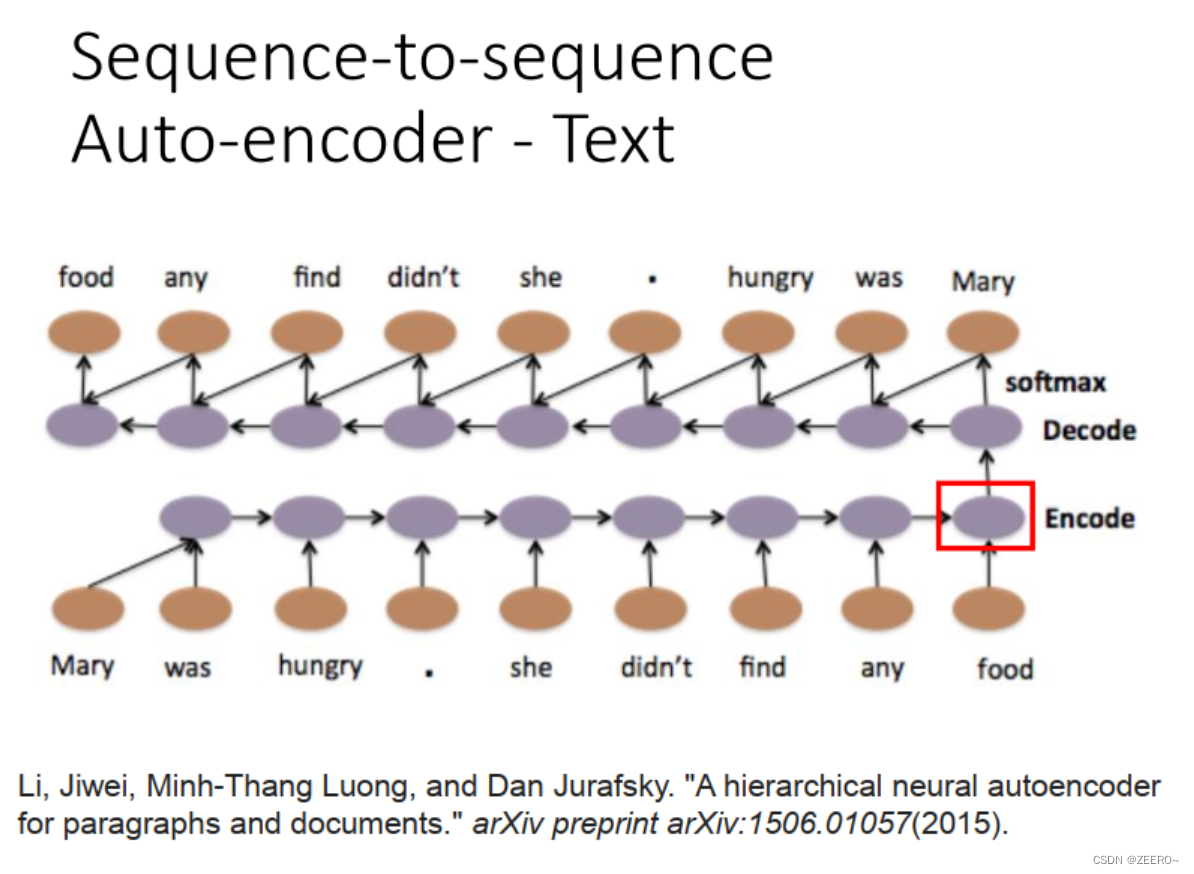
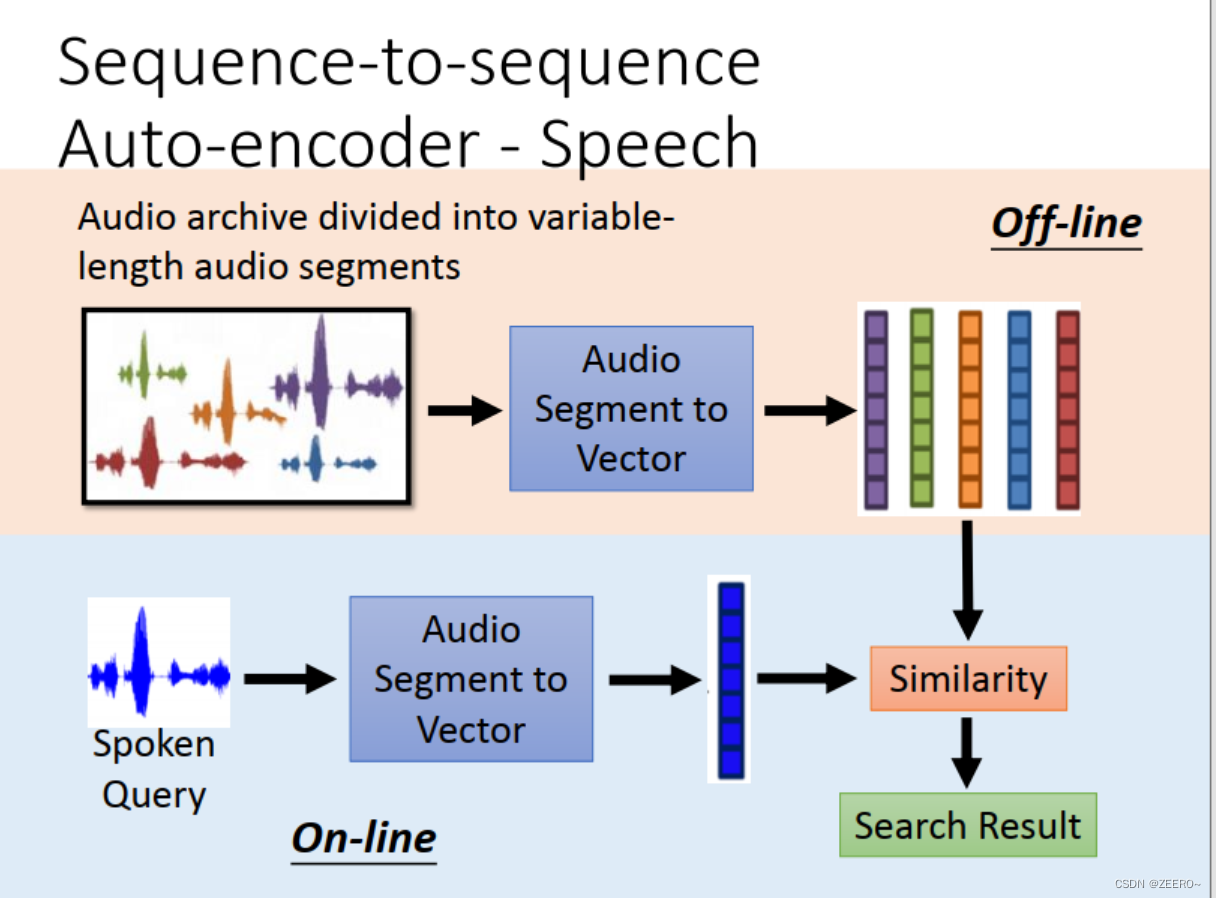
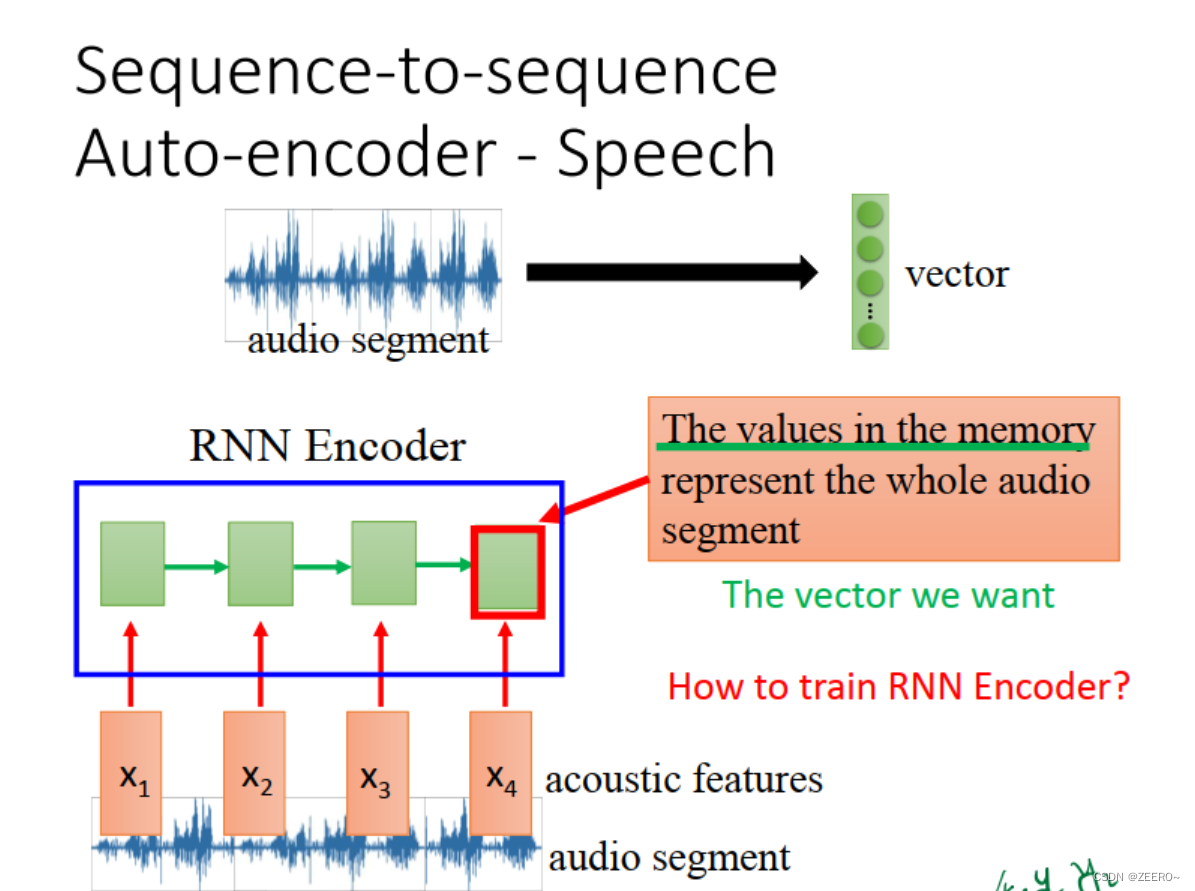
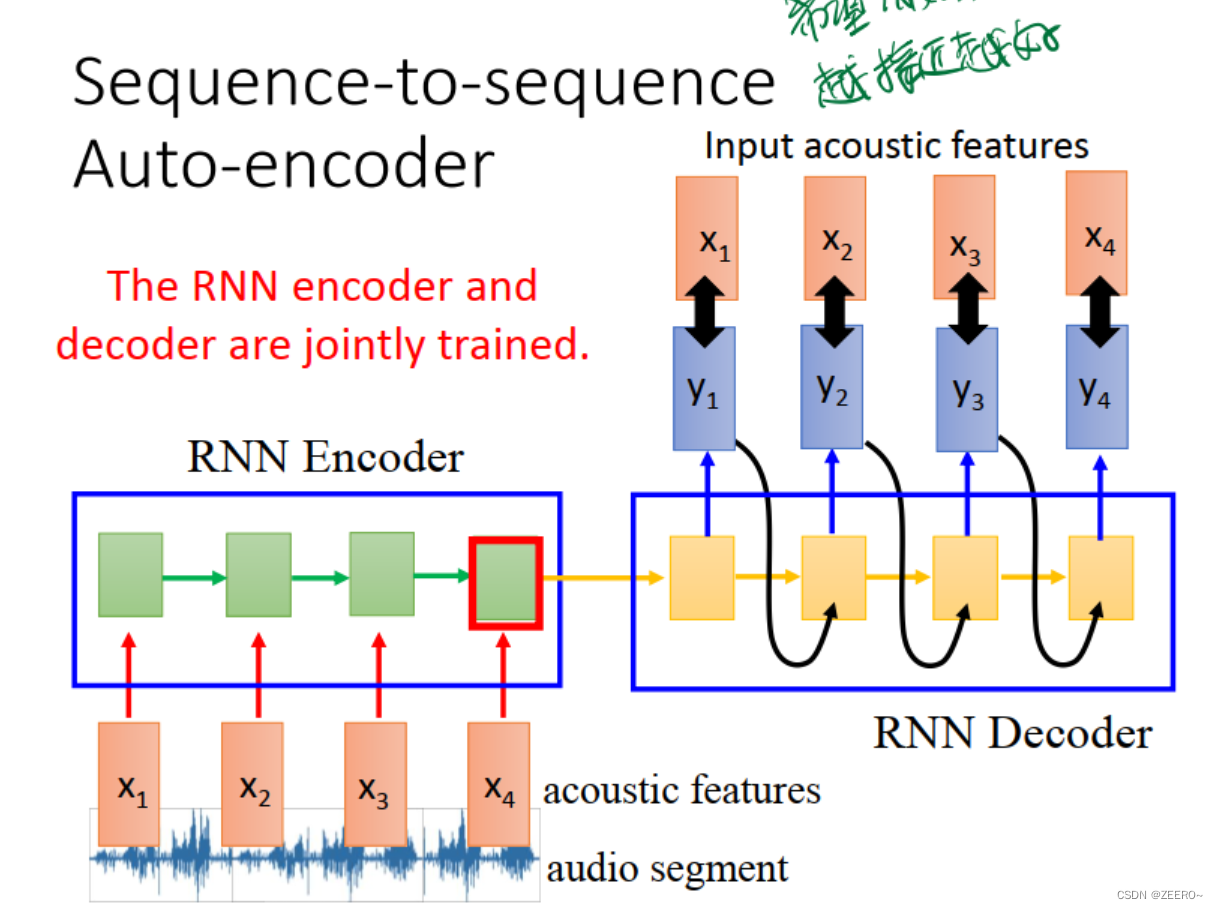
四、RNN和结构学习的区别

(1)从考虑上下文情况来看,单向RNN仅考虑到前文的信息,没有考虑到后文的信息。HMM如果使用viterbi算法的话,则同时考虑了整个sequence的信息。这里来看,结构学习似乎更有优势,但是,双向RNN也可以同时考虑整个sequence信息。
(2)RNN的cost和error是直接相关的,而结构学习并不是。cost往往高于error。
(3)最大的一个区别在于RNN可以deep,而结构学习在deep上则没有优势。