基于RabbitMQ的模拟消息队列之三——硬盘数据管理
文章目录
- 一、数据库管理
- 1.设计数据库
- 2.添加sqlite依赖
- 3.配置application.properties文件
- 4.创建接口MetaMapper
- 5.创建MetaMapper.xml文件
- 6.数据库操作
- 7.封装数据库操作
- 二、文件管理
- 1.消息持久化
- 2.消息文件格式
- 3.序列化/反序列化
- 4.创建文件管理类MessageFileManager
- 5.垃圾回收
- 三、统一管理数据库和文件
一、数据库管理
1.设计数据库
交换机、队列、绑定是交给数据库来管理的,所以,设计这三个表结构就够了,表的字段和核心类同名。
2.添加sqlite依赖
<!-- https://mvnrepository.com/artifact/org.xerial/sqlite-jdbc --><dependency><groupId>org.xerial</groupId><artifactId>sqlite-jdbc</artifactId><version>3.41.0.0</version></dependency>
3.配置application.properties文件
spring.datasource.url=jdbc:sqlite:./data/meta.db
spring.datasource.username=
spring.datasource.password=
spring.datasource.driver-class-name=org.sqlite.JDBC
mybatis.mapper-locations=classpath:mybatis/*Mapper.xml
4.创建接口MetaMapper
在mqserver包下新创建一个包,名字为mapper,在此包下,创建一个接口MetaMapper。添加注解@Mapper
5.创建MetaMapper.xml文件
在resource目录下,创建一个目录mybatis,在此目录下新建一个MetaMapper.xml文件。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.mq.mqserver.mapper.MetaMapper"></mapper>
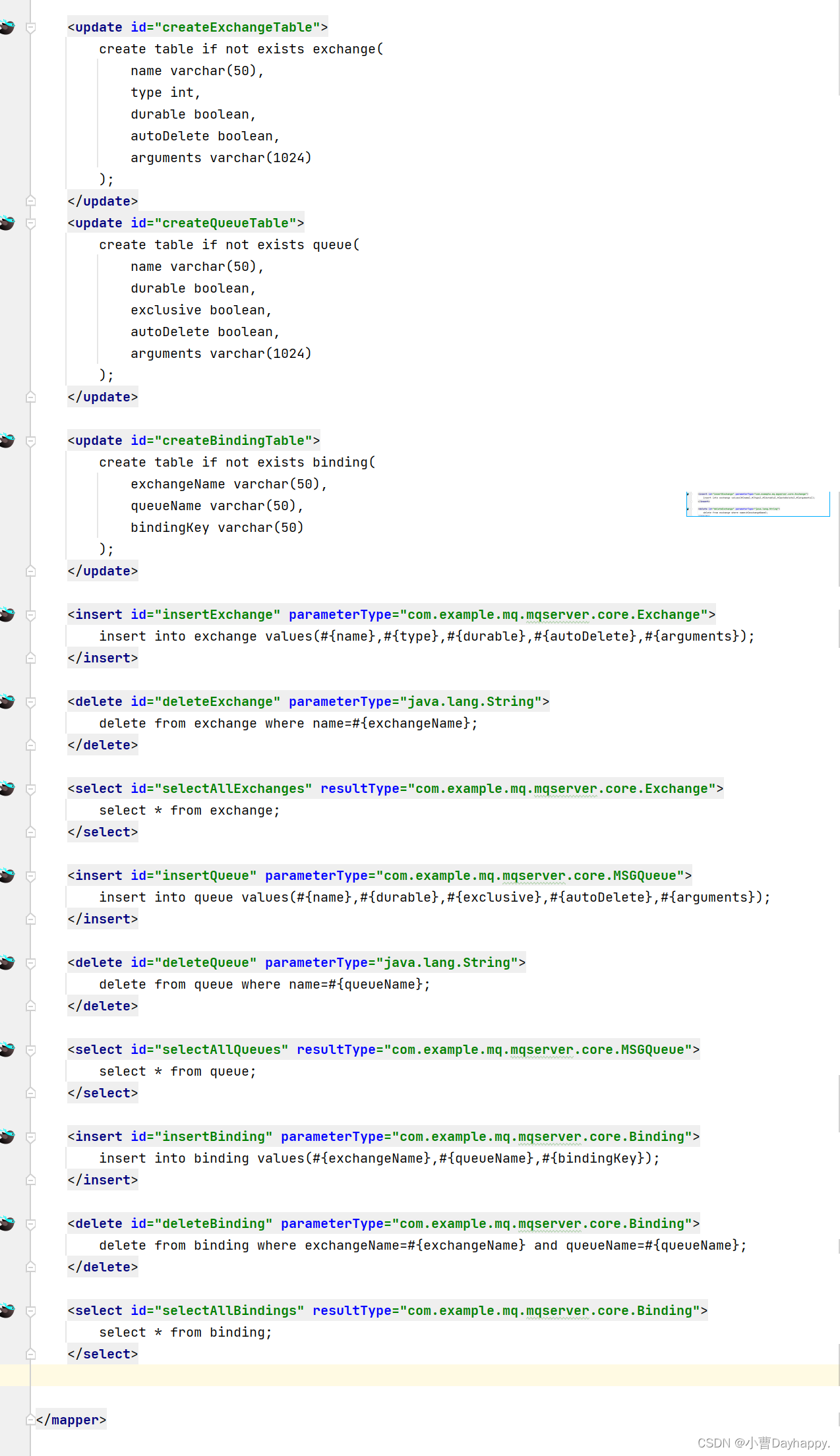
6.数据库操作
建库操作会在程序启动时,由mybatis在./data/meta.db这里自动生成。
所以这里只用针对交换机、队列、绑定创建表以及简单的插入、删除、查询操作就够了。
MetaMapper:

MetaMapper.xml:
7.封装数据库操作
新建一个包datacenter,创建一个类DatabaseManager,封装上述的数据库操作。
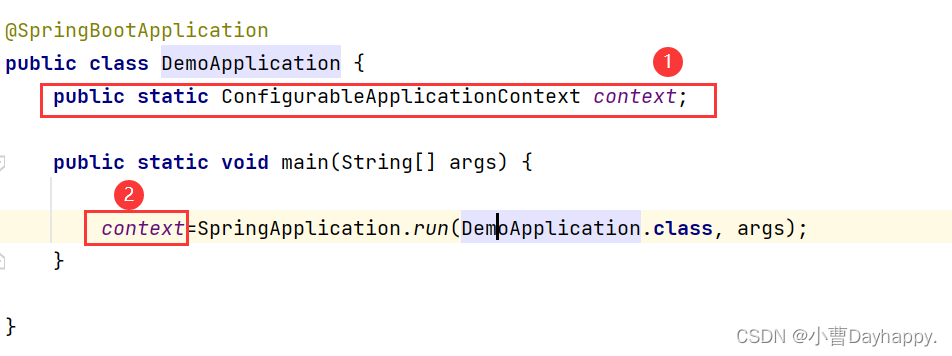
- 初始化数据库
准备工作:因为我们不打算把当前类注入容器,所有需要手动从上下文中获取Bean对象。在启动类中获取上下文。
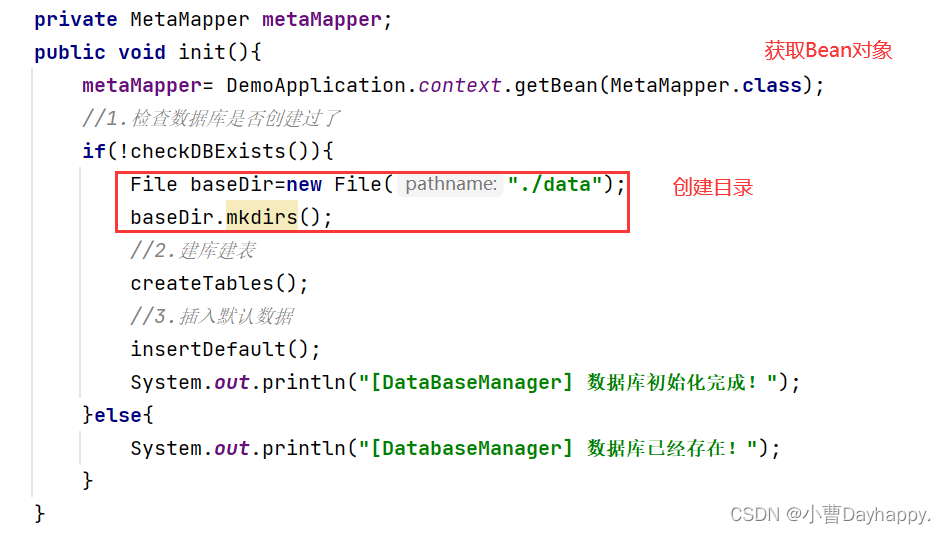
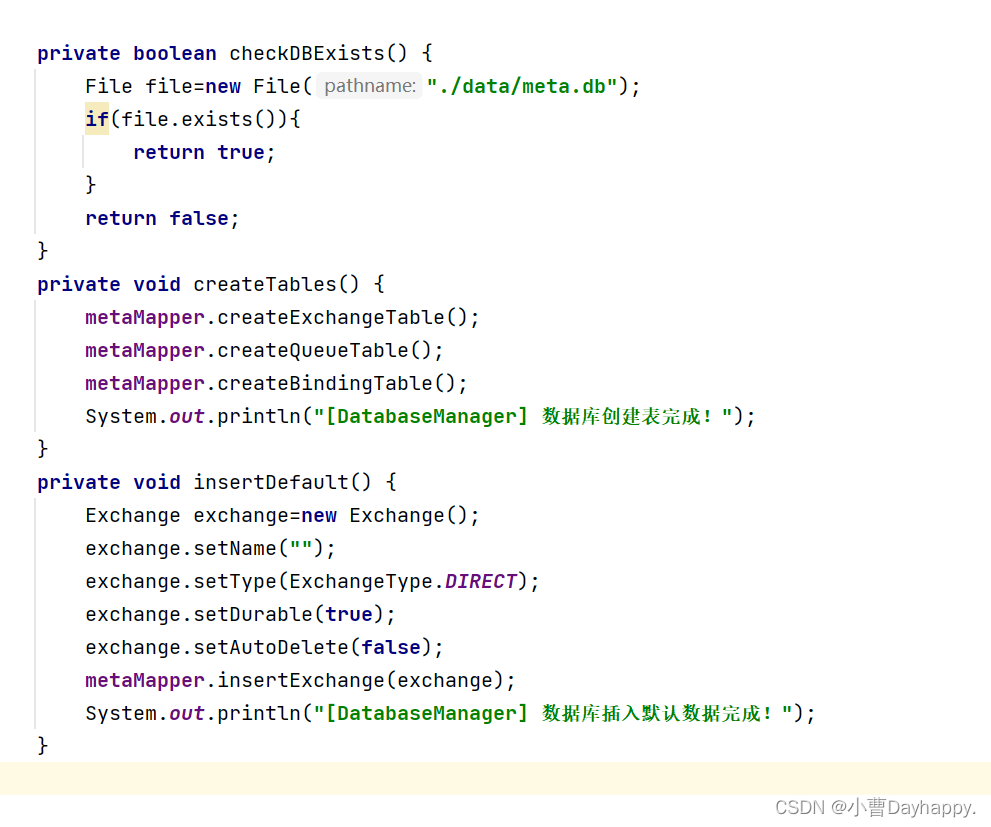
如果数据库已经存在,什么都不做(检查./data/meta.db是否存在);
如果不存在,创建目录,建表,插入默认数据。
-
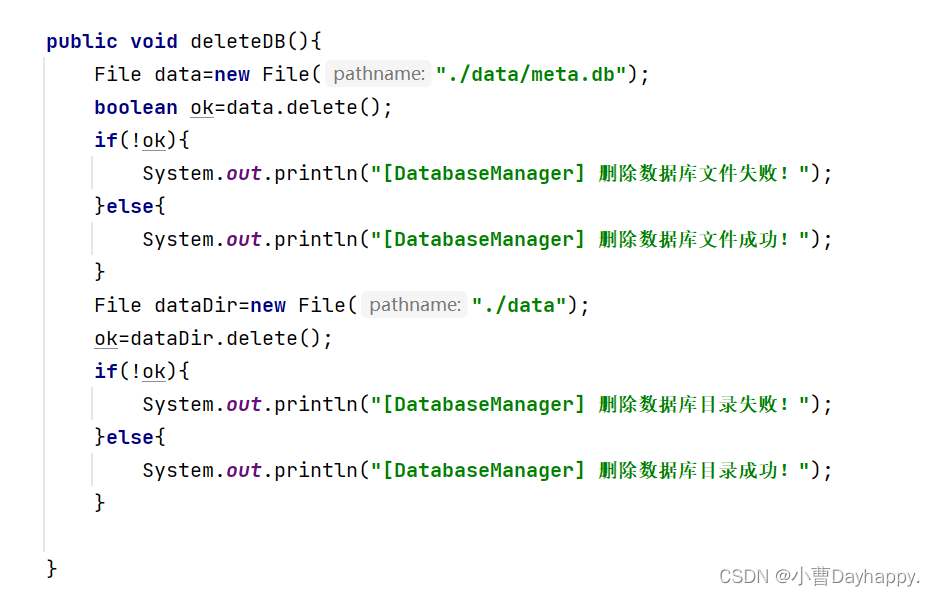
删除数据库文件及目录
删除文件(./data/meta.db)
删除目录(./data)
- 封装交换机、队列、绑定操作

二、文件管理
1.消息持久化
将消息持久化就是将消息存储到文件中。
在data目录下,每个队列又对应一个子目录,与队列名一致。子目录下有两个文件,一个是消息内容文件(queue_data.txt),一个是消息统计文件(queue_stat.txt)。
形如:

2.消息文件格式
- queue_data.txt (消息内容文件)
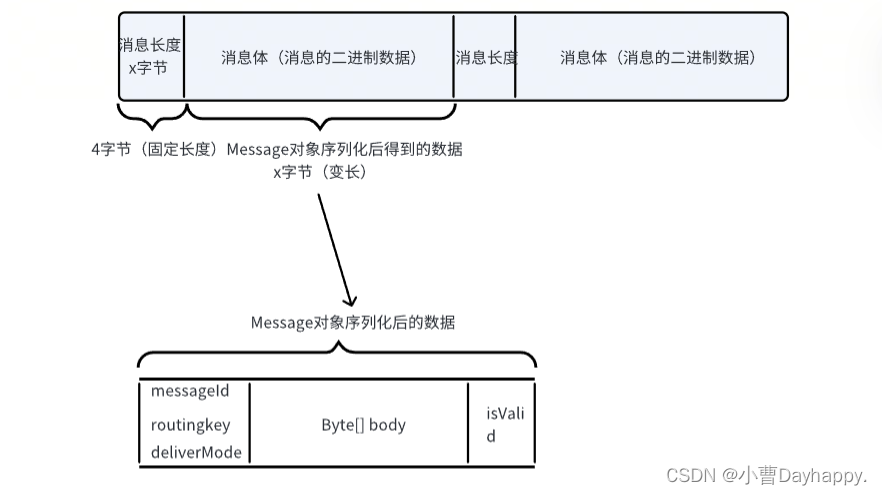
实例: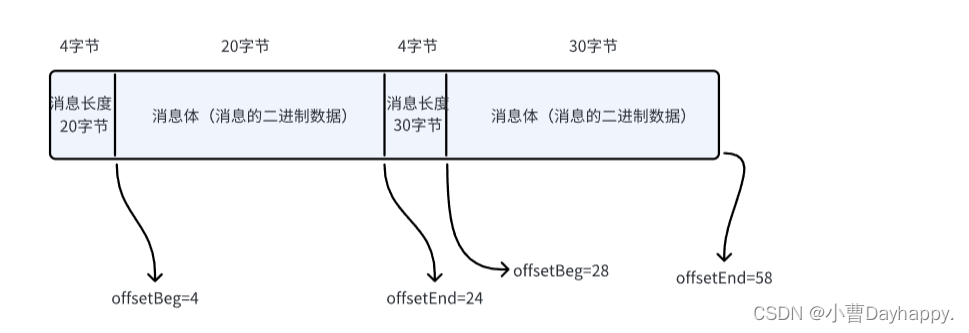
-
queue_stat.txt (消息统计文件)
消息总数数 /t 有效消息数
形如:2300/t1800
3.序列化/反序列化
在common包下添加一个公共工具类BinaryTool,实现序列化、反序列化
-
序列化
1.把byte数组写到ByteArrayOutputStream
2.用ObjectOutputStream关联ByteArrayOutputStream
3.调用ObjectOutputStream的writeObject方法,将object序列化成二进制数据,写入ByteArrayOutputStream中
4.调用ByteArrayOutputStream的toByteArray,输出byte[]数组

-
反序列化
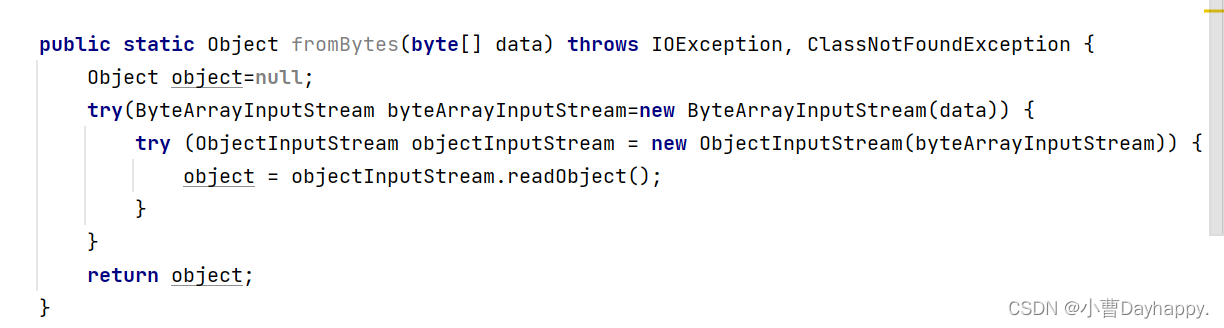
1.使用ByteArrayInputStream读取byte数组
2.使用ObjectInputStream关联ByteArrayInputStream
3.使用ObjectInputStream的readObject方法,读取字节数组出来,再反序列化成Object对象,使用Object接收
4.返回Object对象
4.创建文件管理类MessageFileManager
- 获取目录
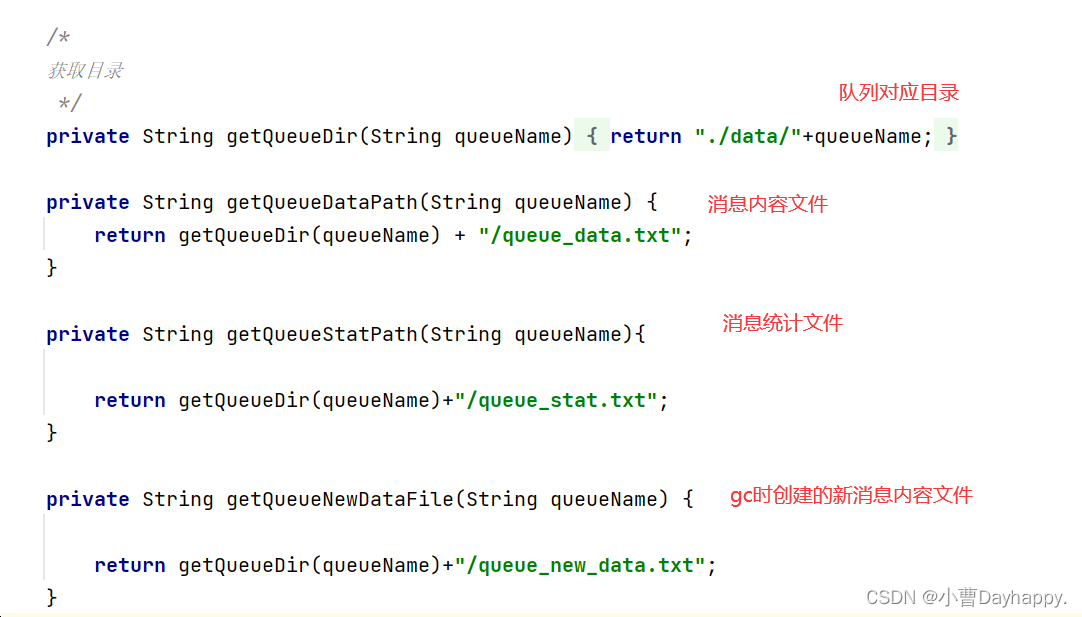
-
消息统计文件读写
将消息统计文件的内容封装成一个类Stat。属性有消息总数,有效消息数。

-
创建目录及文件

-
删除目录及文件

-
检查文件是否存在

-
写入消息文件
以追加的方式写入到文件中。
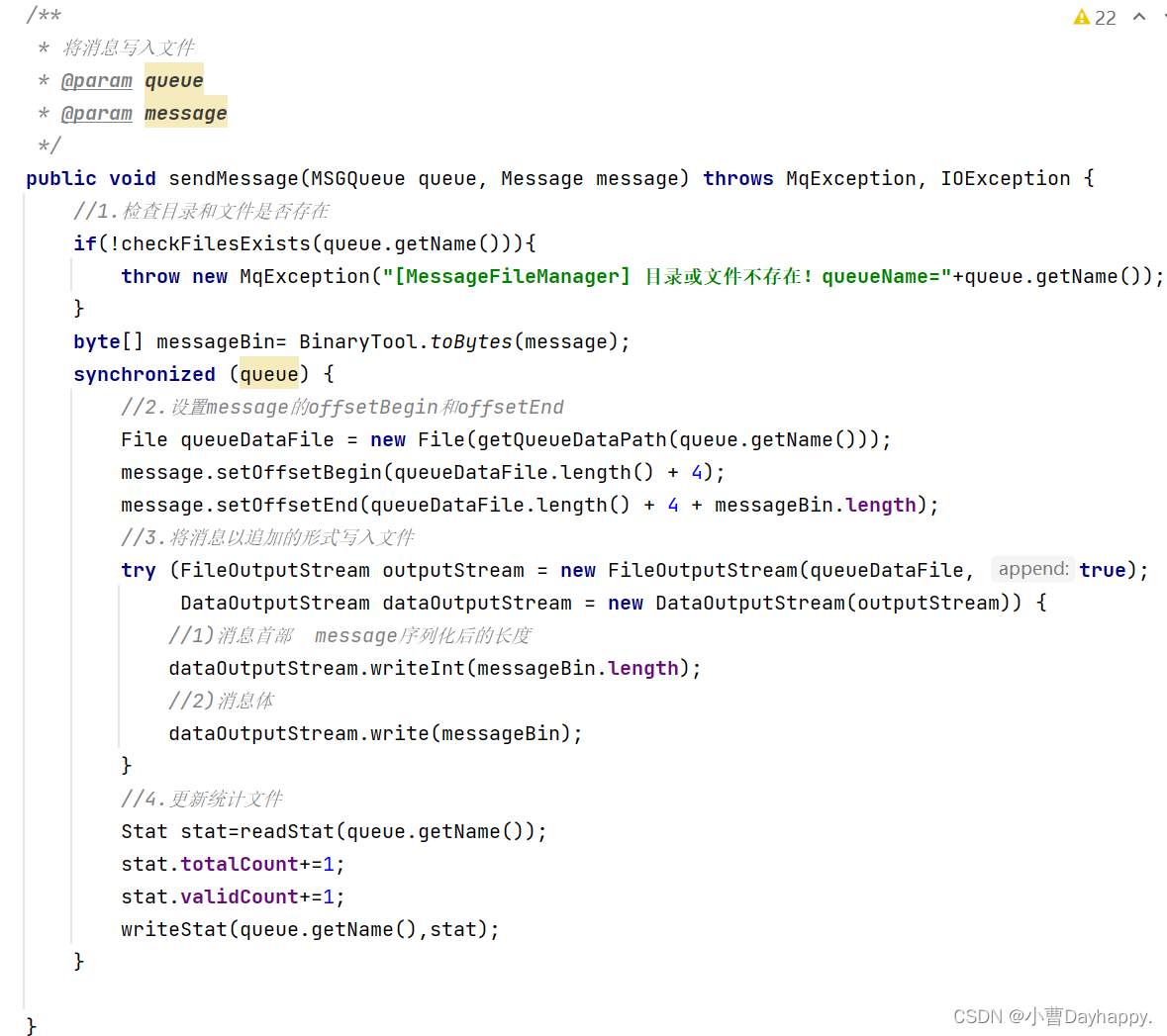
-
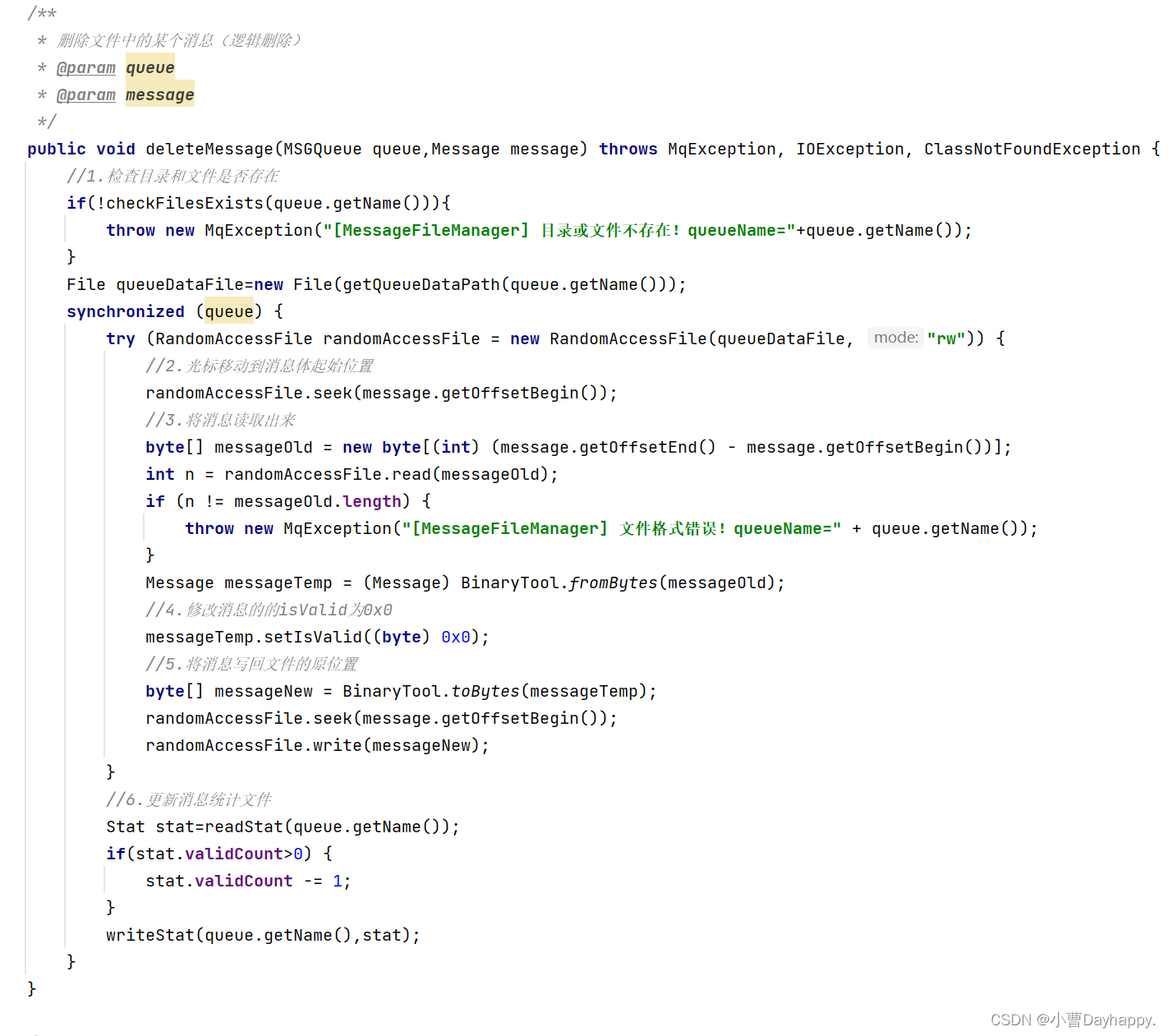
删除消息(逻辑删除)
定位到消息所处文件的位置,将消息反序列化出来,修改isValid为0x0,然后写回文件原位置。
- 读取消息文件

5.垃圾回收
此处约定,当消息总数超过2000并且有效消息数小于30%时,触发垃圾回收机制。
此处的垃圾回收机制采用复制算法。
- 触发垃圾回收

- 垃圾回收

三、统一管理数据库和文件
创建DiskDataCenter,整合数据库和文件。
- 初始化
- 封装交换机、队列(创建队列时创建目录,删除队列时删除目录)、绑定操作
- 封装消息操作
