【python爬虫】7.爬到的数据存到哪里?
文章目录
- 前言
- 存储数据的方式
- 存储数据的基础知识
- 基础知识:Excel写入与读取
- 基础知识:csv写入与读取
- 项目:存储周杰伦的歌曲信息
- 复习
前言
上一关我们以QQ音乐为例,主要学习了如何带参数地请求数据(get请求)和Request Headers的用法,最终爬取到了周杰伦歌曲信息的数据。
那么有一个新的问题来了——爬到的数据要怎么存下来?
可能你会想到这样的方案:把爬到的数据一条条复制黏贴,然后存成Excel文件。这样的方案对于存储十几条数据还好说,可是当我们爬取到的数据超过几百条时,这样的方案显然不可取。
走到这一关卡,获取数据、解析数据以及提取数据,我们都学会了。独独差了存储数据这一步,这也是整个爬虫过程中不可或缺的一步。
所以,这一关要讲解的核心内容就是存储数据的正确方式。后面会依旧以QQ音乐为例,把我们上一关爬取到的周杰伦的歌曲信息的数据存储下来。
存储数据的方式
其实,常用的存储数据的方式有两种——存储成csv格式文件、存储成Excel文件(不是复制黏贴的那种)。
我猜想,此时你会想问“csv”是什么,和Excel文件有什么区别?
前面,我有讲到json是特殊的字符串。其实,csv也是一种字符串文件的格式,它组织数据的语法就是在字符串之间加分隔符——行与行之间是加换行符,同行字符之间是加逗号分隔。
它可以用任意的文本编辑器打开(如记事本),也可以用Excel打开,还可以通过Excel把文件另存为csv格式(因为Excel支持csv格式文件)。
运行以下三行代码,你就能直观清晰地知道csv是什么。
file=open('test.csv','a+')
#创建test.csv文件,以追加的读写模式
file.write('美国队长,钢铁侠,蜘蛛侠')
#写入test.csv文件
file.close()
#关闭文件
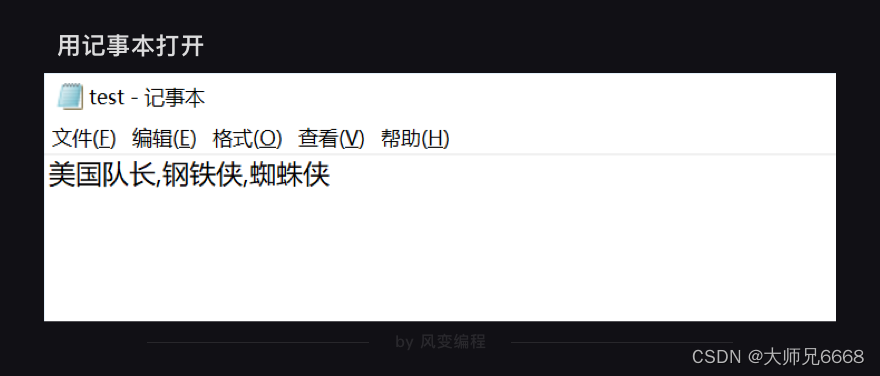
将我们刚刚写入的csv文件用记事本打开,你会看到:
用Excel打开,则是这样的:
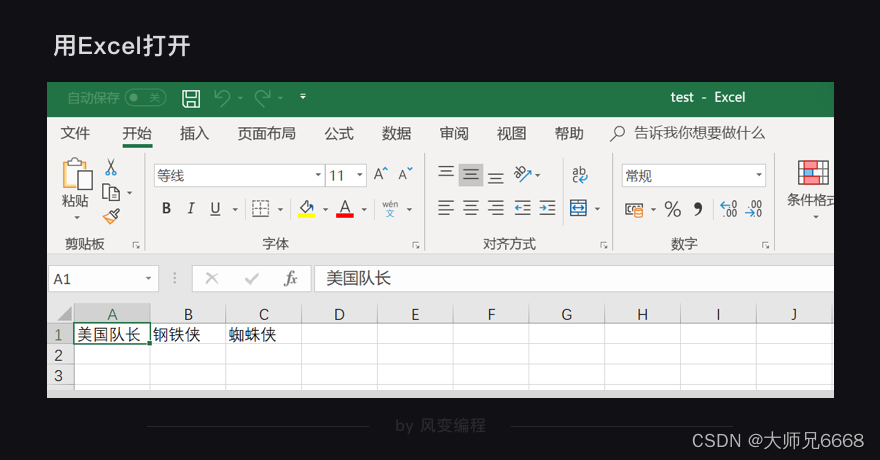
发现了吗?csv文件里的逗号可以充当分隔同行字符串的作用。
为什么要加分隔符?因为不加的话,数据都堆在一起,会显得杂乱无章,也不方便我们之后提取和查找。这也是一种让数据变得有规律的组织方式。
另外,用csv格式存储数据,读写比较方便,易于实现,文件也会比Excel文件小。但csv文件缺少Excel文件本身的很多功能,比如不能嵌入图像和图表,不能生成公式。
至于Excel文件,不用我多说你也知道就是电子表格。它有专门保存文件的格式,即xls和xlsx(Excel2003版本的文件格式是xls,Excel2007及之后的版本的文件格式就是xlsx)。
好啦,csv和Excel文件你都清楚了,我们可以继续学习存储数据的基础知识——如何写入与读取csv格式文件和Excel文件的数据。
存储数据的基础知识
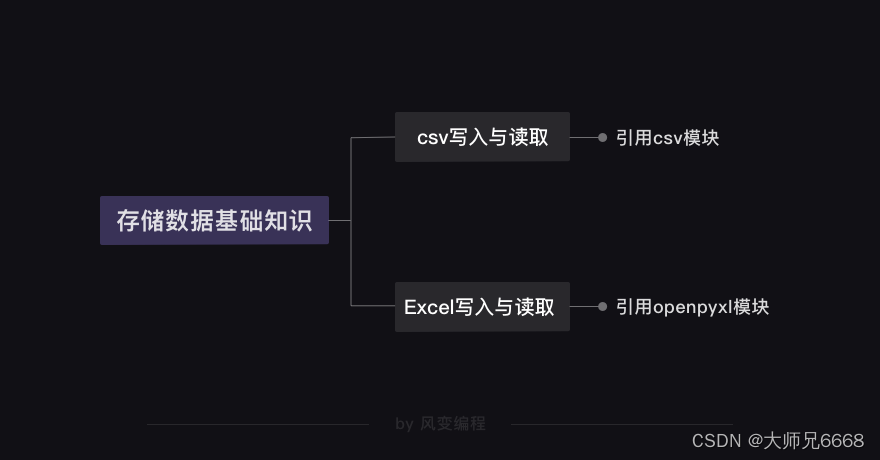
存储成csv格式文件和存储成Excel文件,这两种不同的存储方式需要引用的模块也是不同的。操作csv文件我们需要借助csv模块;操作Excel文件则需要借助openpyxl模块。
放心,两个模块都并不复杂。本节的实操环节我们会用到Excel,先来一起学习一下。
基础知识:Excel写入与读取
好。请你跟着我的节奏,我们一起搞清楚如何往Excel格式文件写入和读取数据。
不过,在开始讲Excel文件的写入与读取前,我们还得稍微了解一下Excel文档的基本概念(考验你对Excel有多了解的时候到了٩(๑❛ᴗ❛๑)۶)。
【提问抢答环节】请问工作簿、工作表和单元格在Excel里分别是指什么?
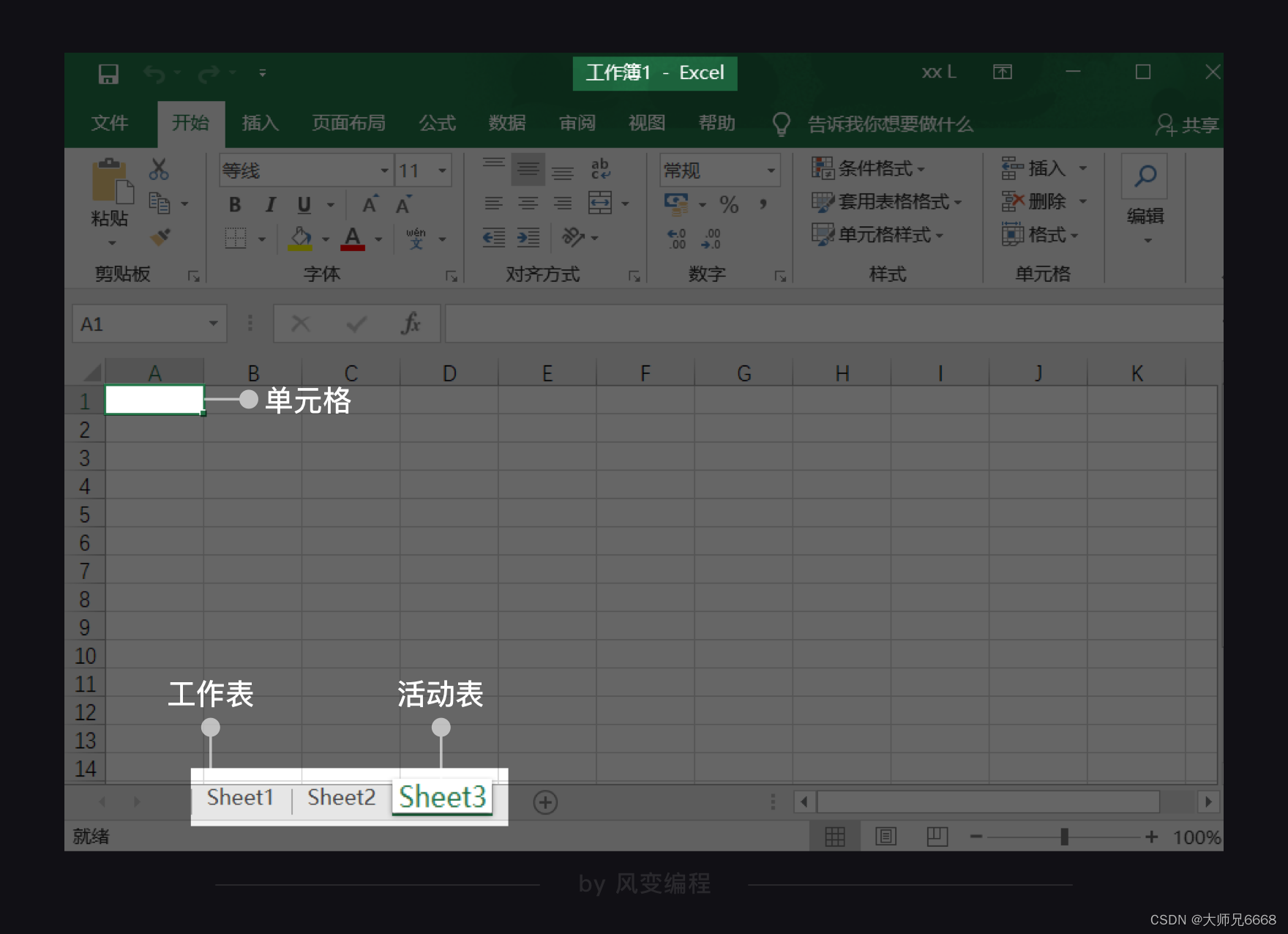
一个Excel文档也称为一个工作簿(workbook),每个工作簿里可以有多个工作表(worksheet),当前打开的工作表又叫活动表。
每个工作表里有行和列,特定的行与列相交的方格称为单元格(cell)。比如上图第A列和第1行相交的方格我们可以直接表示为A1单元格。
清楚了Excel的基础概念,我们可以来说下openpyxl模块是怎么操作Excel文件的了。照例先说写入后说读取。
提醒:我们得先提前安装好openpyxl模块。课程的终端是已经安装好了,如果你想要在本地操作的话,就需要在本地上安装。(安装方法:window电脑:在终端输入命令:pip install openpyxl,按下enter键;mac电脑:在终端输入命令:pip3 install openpyxl,按下enter键)
装好openpyxl模块后,首先要引用它,然后通过openpyxl.Workbook()函数就可以创建新的工作簿,代码如下:
# 引用openpyxl
import openpyxl # 利用openpyxl.Workbook()函数创建新的workbook(工作簿)对象,就是创建新的空的Excel文件。
wb = openpyxl.Workbook()
创建完新的工作簿后,还得获取工作表。不然程序会无所适从,不知道要把内容写入哪张工作表里。
# wb.active就是获取这个工作簿的活动表,通常就是第一个工作表。
sheet = wb.active# 可以用.title给工作表重命名。现在第一个工作表的名称就会由原来默认的“sheet1”改为"new title"。
sheet.title = 'new title'
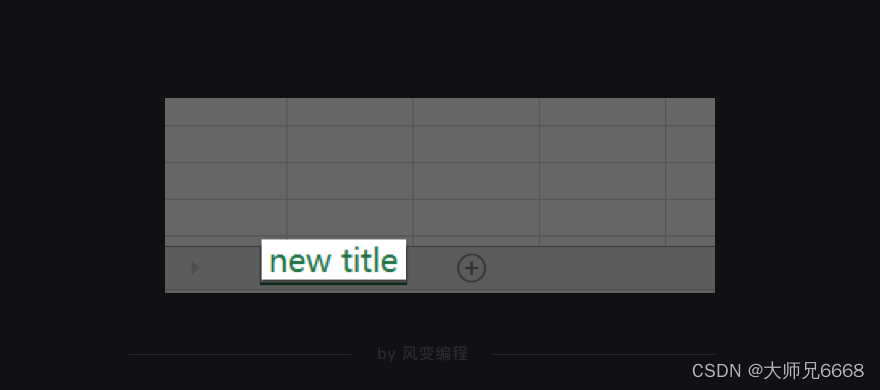
添加完工作表,我们就能来操作单元格,往单元格里写入内容。
# 把'漫威宇宙'赋值给第一个工作表的A1单元格,就是往A1的单元格中写入了'漫威宇宙'。
sheet['A1'] = '漫威宇宙'
往单元格里写入内容只要定位到具体的单元格,如A1(根据Excel的坐标,A1代表第一列第一行相交的单元格),然后给这个单元格赋值即可。
如果我们想往工作表里写入一行内容的话,就得用到append函数。
# 把我们想写入的一行内容写成列表,赋值给row。
row = ['美国队长','钢铁侠','蜘蛛侠']# 用sheet.append()就能往表格里添加这一行文字。
sheet.append(row)
如果我们想要一次性写入的不止一行,而是多行内容,又该怎么办?请你花10s思考一下这个问题。
想出结果了吗?(提示:用for循环,再点击会出现答案)
# 先把要写入的多行内容写成列表,再放进大列表里,赋值给rows。
rows = [['美国队长','钢铁侠','蜘蛛侠'],['是','漫威','宇宙', '经典','人物']]# 遍历rows,同时把遍历的内容添加到表格里,这样就实现了多行写入。
for i in rows:sheet.append(i)# 打印rows
print(rows)
成功写入后,我们千万要记得保存这个Excel文件,不然就白写啦!
# 保存新建的Excel文件,并命名为“Marvel.xlsx”
wb.save('Marvel.xlsx')
这样,Excel文件写入的代码我们就写好了,可以运行一下代码。
import openpyxl
wb=openpyxl.Workbook()
sheet=wb.active
sheet.title='new title'
sheet['A1'] = '漫威宇宙'
rows= [['美国队长','钢铁侠','蜘蛛侠'],['是','漫威','宇宙', '经典','人物']]
for i in rows:sheet.append(i)
print(rows)
wb.save('Marvel.xlsx')
来,请你把上面Excel写入的代码敲一遍,你可以把需要写入的文字替换成你想写入的内容。
恭喜你,Excel文件的写入已经学会啦!此处应该有掌声(激动)!
下面,我们来搞定存储数据的另一个基础知识点——Excel文件的读取。
请你运行一下代码,我们来读取刚刚写入内容的“Marvel.xlsx”文件。
import openpyxl
# 写入的代码:
wb = openpyxl.Workbook()
sheet = wb.active
sheet.title = 'new title'
sheet['A1'] = '漫威宇宙'
rows = [['美国队长','钢铁侠','蜘蛛侠','雷神'],['是','漫威','宇宙', '经典','人物']]
for i in rows:sheet.append(i)
print(rows)
wb.save('Marvel.xlsx')# 读取的代码:
wb = openpyxl.load_workbook('Marvel.xlsx')
sheet = wb['new title']
sheetname = wb.sheetnames
print(sheetname)
A1_cell = sheet['A1']
A1_value = A1_cell.value
print(A1_value)
运行结果:
[['美国队长', '钢铁侠', '蜘蛛侠', '雷神'], ['是', '漫威', '宇宙', '经典', '人物']]
['new title']
漫威宇宙
程序打印出来的[‘new title’]是工作表的名字;“漫威宇宙”是我们刚写入A1单元格的文字。
一行行来看这个读取Excel文件的代码:
import openpyxl
# 写入的代码:
wb = openpyxl.Workbook()
sheet = wb.active
sheet.title = 'new title'
sheet['A1'] = '漫威宇宙'
rows = [['美国队长','钢铁侠','蜘蛛侠','雷神'],['是','漫威','宇宙', '经典','人物']]
for i in rows:sheet.append(i)
print(rows)
wb.save('Marvel.xlsx')# 读取的代码:
wb = openpyxl.load_workbook('Marvel.xlsx')
sheet = wb['new title']
sheetname = wb.sheetnames
print(sheetname)
A1_cell = sheet['A1']
A1_value = A1_cell.value
print(A1_value)
第14行代码:调用openpyxl.load_workbook()函数,打开“Marvel.xlsx”文件。
第15行代码:获取“Marvel.xlsx”工作簿中名为“new title”的工作表。
第16、17行代码:sheetnames是用来获取工作簿所有工作表的名字的。如果你不知道工作簿到底有几个工作表,就可以把工作表的名字都打印出来。
第18-20行代码:把“new title”工作表中A1单元格赋值给A1_cell,再利用单元格value属性,就能打印出A1单元格的值。
学会Excel写入后,读取Excel还是比较简单的对吧?
如果你对openpyxl模块感兴趣,想要有更深入的了解的话,推荐阅读openpyxl模块的官方文档:
https://openpyxl.readthedocs.io/en/stable/
基础知识:csv写入与读取
接下来,只要我们再搞定csv文件的写入与读取,存储数据就不再是什么难事。
好。现在请你跟着我的节奏,我们一起先搞清楚如何往csv格式文件写入数据。
首先,我们要引用csv模块。因为Python自带了csv模块,所以我们不需要安装就能引用它。
你是不是会困惑,明明前面csv写入我们可以直接用open函数来写,为什么现在还要先引用csv模块?答案:直接运用别人写好的模块,比我们使用open()函数来读写,语法更简洁,功能更强大,待会你就能感受到。那么,何乐而不为?
# 引用csv模块。
import csv# 创建csv文件,我们要先调用open()函数,传入参数:文件名“demo.csv”、写入模式“w”、newline=''、encoding='utf-8'。
csv_file = open('demo.csv','w',newline='',encoding='utf-8')
然后,我们得创建一个新的csv文件,命名为“demo.csv”。
“w”就是write,即文件写入模式,它会以覆盖原内容的形式写入新添加的内容。
友情附上一张文件读写模式表。你不需要背下来,之后不知道用什么模式时查查表就可以了。

加newline=’ '参数的原因是,可以避免csv文件出现两倍的行距(就是能避免表格的行与行之间出现空白行)。加encoding=‘utf-8’,可以避免编码问题导致的报错或乱码。
创建完csv文件后,我们要借助csv.writer()函数来建立一个writer对象。
# 引用csv模块。
import csv# 调用open()函数打开csv文件,传入参数:文件名“demo.csv”、写入模式“w”、newline=''、encoding='utf-8'。
csv_file = open('demo.csv','w',newline='',encoding='utf-8')
# 用csv.writer()函数创建一个writer对象。
writer = csv.writer(csv_file)
那怎么往csv文件里写入新的内容呢?答案是——调用writer对象的writerow()方法。
# 借助writerow()函数可以在csv文件里写入一行文字 "电影"和“豆瓣评分”。
writer.writerow(['电影','豆瓣评分'])
提醒:writerow()函数里,需要放入列表参数,所以我们得把要写入的内容写成列表。就像[‘电影’,‘豆瓣评分’]。
我们试着再写入两部电影的名字和其对应的豆瓣评分,最后关闭文件,就完成csv文件的写入了。
# 引用csv模块。
import csv# 调用open()函数打开csv文件,传入参数:文件名“demo.csv”、写入模式“w”、newline=''、encoding='utf-8'。
csv_file = open('demo.csv','w',newline='',encoding='utf-8')
# 用csv.writer()函数创建一个writer对象。
writer = csv.writer(csv_file)
# 调用writer对象的writerow()方法,可以在csv文件里写入一行文字 “电影”和“豆瓣评分”。
writer.writerow(['电影','豆瓣评分'])
# 在csv文件里写入一行文字 “银河护卫队”和“8.0”。
writer.writerow(['银河护卫队','8.0'])
# 在csv文件里写入一行文字 “复仇者联盟”和“8.1”。
writer.writerow(['复仇者联盟','8.1'])
# 写入完成后,关闭文件就大功告成啦!
csv_file.close()
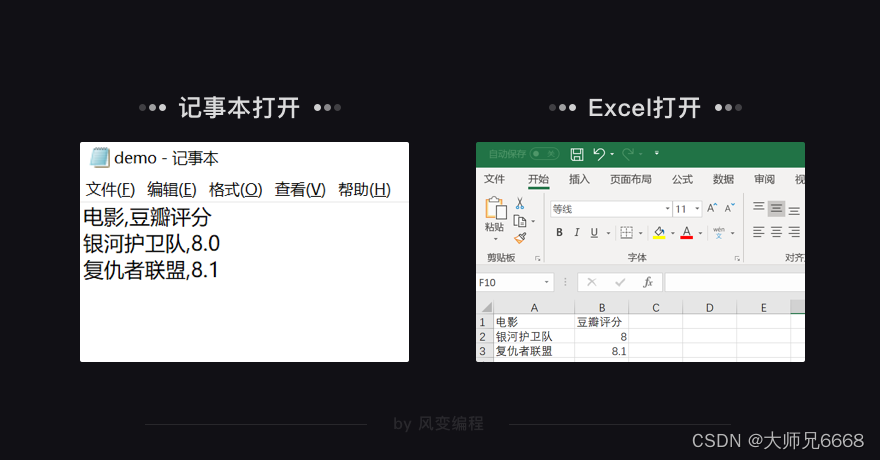
运行代码后,名为“demo.csv”的文件会被创建。用Excel或记事本打开这个文件,你就能看到——
【练习时间】请你把上面csv文件写入的代码敲一遍。毕竟代码是绝对不能光看不敲的,快,敲起来!提示:先引入csv模块,用open()函数打开csv文件,不要忘了加newline=’ '参数;然后利用csv.writer()函数创建一个writer对象,再调用writerow()方法,就可以往csv文件里写入内容。
用csv模块写入数据这一个知识点我们已经清楚。接下来我们可以继续学习怎么读取csv文件的数据。
以刚刚创建好的“demo.csv”文件为例。你可以先运行下面的代码,看看会读取出什么结果。
import csv
csv_file=open('demo.csv','r',newline='',encoding='utf-8')
reader=csv.reader(csv_file)
for row in reader:print(row)
csv_file.close()
运行结果:
['电影', '豆瓣评分']
['银河护卫队', '8.0']
['复仇者联盟', '8.1']
是不是把刚刚写入“demo.csv”文件的内容都打印出了?如果是,说明我们成功读取!
现在,我们一行行来看刚刚读取“demo.csv”文件的代码,注释要认真阅读。
import csv
csv_file = open('demo.csv','r',newline='',encoding='utf-8')
reader = csv.reader(csv_file)
for row in reader:print(row)
第1、2行代码:导入csv模块。用open()打开“demo.csv”文件,‘r’是read读取模式,newline=’'是避免出现两倍行距。encoding='utf-8’能避免编码问题导致的报错或乱码。
第3行代码:用csv.reader()函数创建一个reader对象。
第4、5行代码:用for循环遍历reader对象的每一行。打印row,就能读取出“demo.csv”文件里的内容。
来,把上面读取“demo.csv”文件的代码敲一遍,不要偷懒。
怎么样,搞定了吧!
真棒,csv格式文件的写入和读取都被我们搞定了!
补充一点:csv模块本身还有很多函数和方法,附上csv模块官方文档链接:
https://yiyibooks.cn/xx/python_352/library/csv.html#module-csv
这些函数和方法我们不需要全部都记下来,只要在需要用到的时候,学会查询就行。
存储数据的基础知识我们就讲完了。接着我们进入实操项目——存储周杰伦的歌曲信息。
首先,我们要先选择存储数据的方式。由于篇幅有限,在这里我们只选取用openpyxl模块存储成Excel文件的方式做演示。
项目:存储周杰伦的歌曲信息
上一关我们已经爬到了周杰伦歌曲信息的数据,所以只要在上一关代码的基础上,再加入存储数据的代码,【获取数据→解析数据→提取数据→存储数据】这整个爬虫的过程我们就都完成了!
上一关的代码如下:
import requestsurl = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp'
for x in range(5):# 将参数封装为字典params = {'ct': '24','qqmusic_ver': '1298','new_json': '1','remoteplace': 'txt.yqq.song','searchid':'59091538798969282','t': '0','aggr': '1','cr': '1','catZhida': '1','lossless': '0','flag_qc': '0','p': str(x + 1),'n': '20','w': '周杰伦','g_tk': '5381','loginUin': '0','hostUin': '0','format': 'json','inCharset': 'utf8','outCharset': 'utf-8','notice': '0','platform': 'yqq.json','needNewCode': '0'}# 调用get方法,下载这个列表res_music = requests.get(url, params=params)# 使用json()方法,将response对象,转为列表/字典json_music = res_music.json()# 一层一层地取字典,获取歌单列表list_music = json_music['data']['song']['list']# list_music是一个列表,music是它里面的元素for music in list_music:# 以name为键,查找歌曲名print(music['name'])# 查找专辑名print('所属专辑:' + music['album']['name'])# 查找播放时长print('播放时长:' + str(music['interval']) + '秒')# 查找播放链接print('播放链接:https://y.qq.com/n/yqq/song/' + music['mid'] + '.html\n\n')
按照Excel文件写入的步骤,我们可以先在上一关的代码上,添加导入openpyxl模块、创建工作簿和获取工作表的代码。
# 在上一关的代码上再导入openpyxl模块。
import requests,openpyxl
# 创建工作簿
wb = openpyxl.Workbook()
# 获取工作簿的活动表
sheet = wb.active
# 工作表重命名为song。
sheet.title = 'song'
既然我们要存储成Excel文件的话,我们得先添加表头,比如我们现在想存储歌曲名、所属专辑、播放时长和播放链接,那就可以先分别在A1、B1、C1、D1单元格中写入“歌曲名”、“所属专辑”、“播放时长”和“播放链接”。
sheet['A1'] ='歌曲名'
sheet['B1'] ='所属专辑'
sheet['C1'] ='播放时长'
sheet['D1'] ='播放链接'
接下来,把所有歌曲名、所属专辑、播放时长和播放链接用append()函数,一一写入Excel文件。
最后,保存这个文件,数据就会被我们都存储下来。
完整的代码如下(请重点关注加了注释的代码):
import requests,openpyxl
# 创建工作簿
wb=openpyxl.Workbook()
# 获取工作簿的活动表
sheet=wb.active
# 工作表重命名
sheet.title='lyrics' sheet['A1'] ='歌曲名' # 加表头,给A1单元格赋值
sheet['B1'] ='所属专辑' # 加表头,给B1单元格赋值
sheet['C1'] ='播放时长' # 加表头,给C1单元格赋值
sheet['D1'] ='播放链接' # 加表头,给D1单元格赋值url = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp'
for x in range(5):params = {'ct': '24','qqmusic_ver': '1298','new_json': '1','remoteplace': 'txt.yqq.song','searchid':'59091538798969282','t': '0','aggr': '1','cr': '1','catZhida': '1','lossless': '0','flag_qc': '0','p': str(x + 1),'n': '20','w': '周杰伦','g_tk': '5381','loginUin': '0','hostUin': '0','format': 'json','inCharset': 'utf8','outCharset': 'utf-8','notice': '0','platform': 'yqq.json','needNewCode': '0'}res_music = requests.get(url, params=params)json_music = res_music.json()list_music = json_music['data']['song']['list']for music in list_music:# 以name为键,查找歌曲名,把歌曲名赋值给namename = music['name']# 查找专辑名,把专辑名赋给albumalbum = music['album']['name']# 查找播放时长,把时长赋值给timetime = music['interval']# 查找播放链接,把链接赋值给linklink = 'https://y.qq.com/n/yqq/song/' + str(music['mid']) + '.html\n\n'# 把name、album、time和link写成列表,用append函数多行写入Excelsheet.append([name,album,time,link]) print('歌曲名:' + name + '\n' + '所属专辑:' + album +'\n' + '播放时长:' + str(time) + '\n' + '播放链接:'+ link)# 最后保存并命名这个Excel文件
wb.save('Jay.xlsx')
运行代码,“Jay.xlsx”文件就会被创建。打开这个文件就可以看到存储的数据。
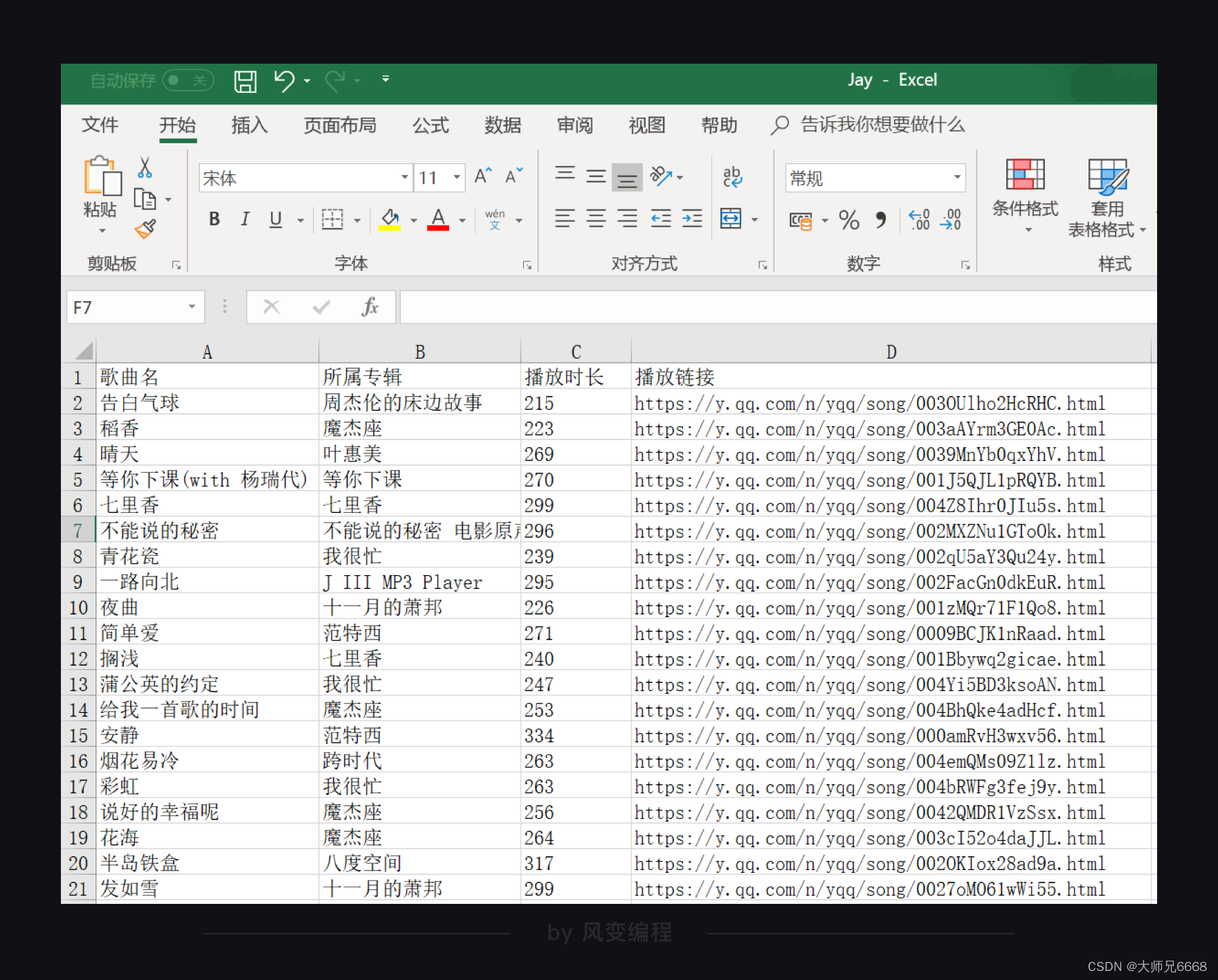
【练习时间】已经演示了一遍怎么存储周杰伦歌曲信息的数据,现在到你实操的时候啦。请你在上一关代码的基础上,把歌曲名、所属专辑、播放时长和播放链接做赋值操作,以及添加存储数据的代码。
怎么样,搞定了吧!
鼓掌ヾ(∀)ノ 我们这一关的内容完美结束!
复习
接下来是简单的复习(刚才选择跳过csv模块的同学,也可以看看csv模块的复习内容,毕竟温故而知新)。

# csv写入的代码:import csv
csv_file = open('demo.csv','w',newline='')
writer = csv.writer(csv_file)
writer.writerow(['电影','豆瓣评分'])
csv_file.close()

# csv读取的代码:import csv
csv_file = open('demo.csv','r',newline='')
reader=csv.reader(csv_file)
for row in reader:print(row)

# Excel写入的代码:import openpyxl
wb = openpyxl.Workbook()
sheet = wb.active
sheet.title ='new title'
sheet['A1'] = '漫威宇宙'
rows = [['美国队长','钢铁侠','蜘蛛侠','雷神'],['是','漫威','宇宙', '经典','人物']]
for i in rows:sheet.append(i)
print(rows)
wb.save('Marvel.xlsx')

# Excel读取的代码:import openpyxl
wb = openpyxl.load_workbook('Marvel.xlsx')
sheet = wb['new title']
sheetname = wb.sheetnames
print(sheetname)
A1_value = sheet['A1'].value
print(A1_value)
这一关,我们引用了csv模块和openpyxl模块。这两个都是前人编写好的模块,我们拿来就能实现存储数据的操作。
正是有了前人编写好的模块,我们才不用费心费力,再去编写一个全新的能实现存储功能的代码。
这种前人创造的知识沉淀,以无私的方式分享给我们使用的精神,叫开源精神。在编程世界里,这种精神就是最宝贵的财富。
也是因为开源,我们才得以领略和获得到前人的精神财富。比如,借助openpyxl模块的其他函数和方法,我们甚至可以实现自动化办公(自动处理数据繁杂的Excel文件等),解放我们的双手。
当然,这需要学习关于这个模块更多的知识。不过这不是本课程的重点,我会有专门的其他文章专门介绍这几个模块。
说这些的目的,是想让你了解开源精神的伟大,以及更深层的意义——彻底减少重复性工作,提高效率。
最后,希望我们既能是开源精神的受益者,也可以成为开源精神的倡导者和实践者。
我们下一关见。