deepspeed多机多卡并行训练指南
文章目录
- 前言
- 离线配置训练环境
- 共享文件系统
- 多台服务器之间配置互相免密登录
- pdsh
- 多卡训练可能会碰到的问题
- 注意
- 总结
前言
我的配置:
7机14卡,每台服务器两张A800
问:为啥每台机只挂两张卡?
答:给我的就这样的,我倒希望单机8卡,不过这些服务器是云厂商提供的,据说都是PCIE连接,且单机最多只能挂四张卡。
服务器只允许内网访问,不能连接外网
因此,你需要先搞定如何离线配置训练环境
离线配置训练环境
具体可以参考:Anaconda 环境克隆、迁移
按照上面文章打包环境时,有可能碰到如下报错:
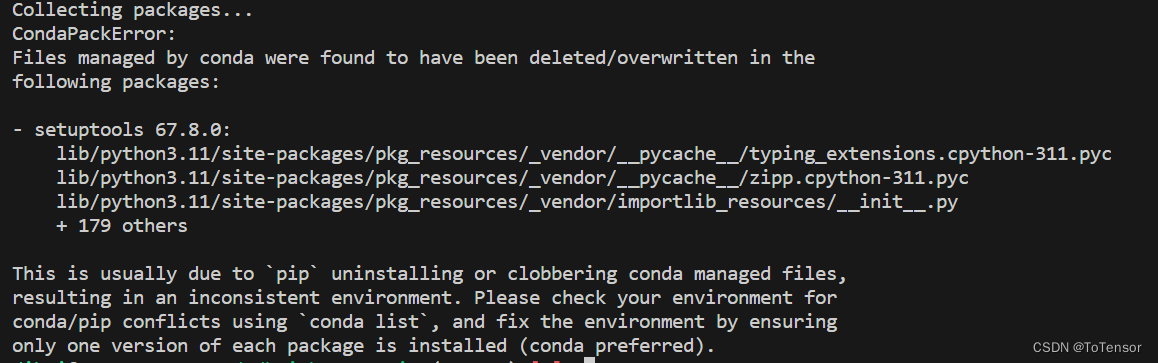
可通过增加参数--ignore-missing-files解决
如:conda pack -n 环境名 -o 新的环境名.tar.gz --ignore-missing-files
共享文件系统
正常来说,多机多卡训练,配置个共享文件系统是有很多好处的,比如数据集和模型你只需要存一份,更重要的是,在模型保存时,将模型保存到共享文件系统下,就不用保存多份模型,如果没有共享文件系统,你需要在每台服务器上都保存一份模型参数。
当你想要断点重训时,你需要手动合并每台机器上的优化器参数,非常麻烦。
如果真的没有共享文件系统,那怎么办?
解决办法:
方式1、在deepspeed里配置checkpoint参数的use_node_local_storage,如下:
"checkpoint": {"use_node_local_storage": true
}
怕大家不明白怎么加,这里给出一个deepspeed stage2的配置样例:
{"bfloat16": {"enabled": false},"fp16": {"enabled": "auto","loss_scale": 0,"loss_scale_window": 1000,"initial_scale_power": 16,"hysteresis": 2,"min_loss_scale": 1},"optimizer": {"type": "AdamW","params": {"lr": "auto","betas": "auto","eps": "auto","weight_decay": "auto"}},"zero_optimization": {"stage": 2,"allgather_partitions": true,"allgather_bucket_size": 2e8,"overlap_comm": true,"reduce_scatter": true,"reduce_bucket_size": "auto","contiguous_gradients": true},"gradient_accumulation_steps": "auto","gradient_clipping": "auto","steps_per_print": 1e5,"train_batch_size": "auto","train_micro_batch_size_per_gpu": "auto","wall_clock_breakdown": false,"checkpoint": {"use_node_local_storage": true}
}
参数解释

原始文档:https://www.deepspeed.ai/docs/config-json/
方式2、增加在TrainingArguments中配置参数--save_on_each_node即可
其实,huggingface中的deepspeed插件文档已经对没有共享文件系统的情况做了说明,确实比较难找,位置:https://huggingface.co/docs/transformers/main/en/main_classes/deepspeed#use-of-nonshared-filesystem

以上两种方式,都可以解决没有共享文件系统导致无法断点重训的问题。
假如你已经使用了上面的配置,还有可能会的出现一个问题就是,当你使用resume路径去恢复训练时,你有可能卡在下图的位置:
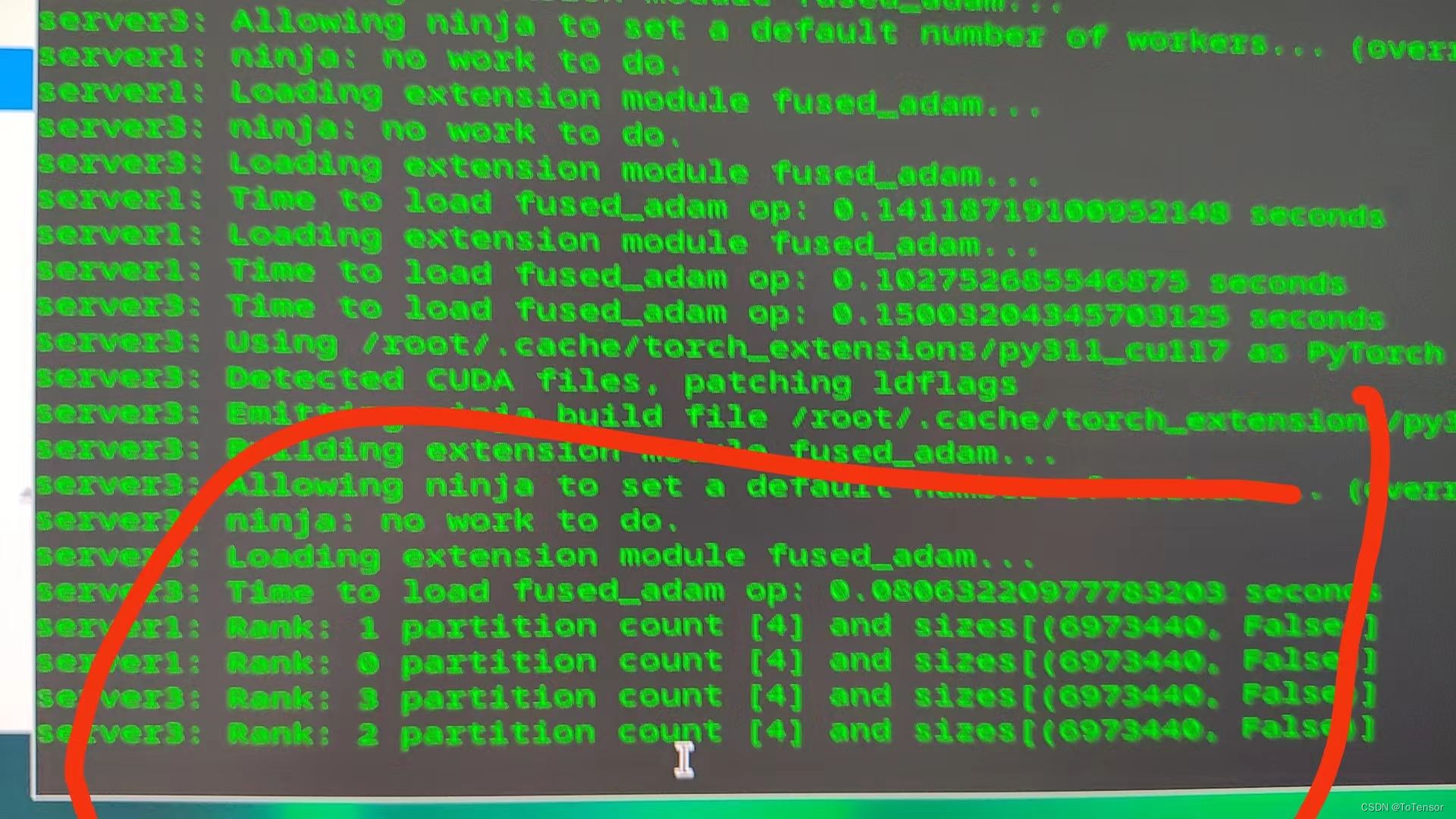
代码一直卡在这,GPU有占用,GPU利用率也有显示,此时,你应该检查你的device_map是否为auto,如果不是,那肯定会卡在这
如果device_map="auto",但代码还是卡在这,可能的解决办法:
这段图片参考自:deepspeed多机多卡训练踏过的坑
多台服务器之间配置互相免密登录
参考SSH远程登录:两台或多台服务器之间免密登录设置
这个是必须要做的,最好在一开始就做好,能节省很多时间。
pdsh
给每台服务器都安装pdsh,安装方法:
#下载解压
wget https://storage.googleapis.com/google-code-archive-downloads/v2/code.google.com/pdsh/pdsh-2.29.tar.bz2 && tar -xf pdsh-2.29.tar.bz2 -C /root/pdsh
#编译安装
cd pdsh-2.29 && ./configure --with-ssh --enable-static-modules --prefix=/usr/local && make && make install
#测试
pdsh -V
把路径换成你自己的就行,若是离线服务器,你就先在有网的服务器下载好pdsh,再复制到离线的服务器去安装
多卡训练可能会碰到的问题
问题1:ninja已经安装,deepspeed 多机多卡RuntimeError: Ninja is required to load C++ extensions
答案1:
在训练代码的开头加入:
/root/anaconda3/envs/baichuan/bin:是服务器的conda虚拟环境的bin目录
local_env = os.environ.copy()
local_env["PATH"]= "/root/anaconda3/envs/baichuan/bin:" + local_env["PATH"]
os.environ.update(local_env)
问题2:libcudart.so.12.2: cannot open shared object file: No such file or directory
答案2:
1、检查文件libcudart.so.12.2是否存在(正常来说都是存在的),不存在该文件的话,需要重装cuda
2、在命令行执行 sudo ldconfig /usr/local/cuda-12.2/lib64
注意
执行训练的代码,每台机器上要有完全一致的一份,且存储的路径都要一致(包括软件的安装路径等),以免出现奇奇怪怪的报错,真的让人头秃
总结
真正跑过多机多卡训练的同学,应该能明白,这篇文章是有多细节了!毫不夸张地说,干货满满!希望各位可以点赞+收藏。