python中的文件操作
我们平常对文件的基本操作,大概可以分为三个步骤(简称文件操作三步走):
① 打开文件
② 读写文件
③ 关闭文件
【注意事项】
注意:可以只打开和关闭文件,不进行任何读写
文件打开
open函数:open(name, mode, encoding)
- name:是要打开的目标文件名的字符串(可以包含文件所在的具体路径)。
- mode:设置打开文件的模式(访问模式):只读、写入、追加等。
- encoding:编码格式(推荐使用UTF-8)
含义:可以打开一个已经存在的文件,如果文件不存在的话创建一个新文件
mode介绍:

demo:open用法
f=open("test.txt",'r',encoding='UTF8') #如果文件不存在,则报错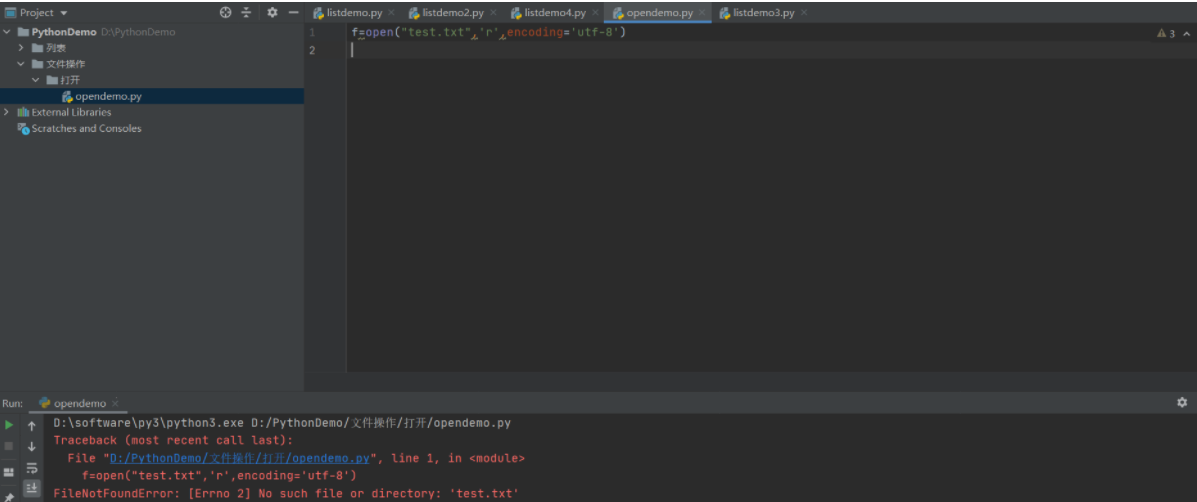
改成如下:如果文件不存在,则创建新文件
f=open("test.txt",'w',encoding='UTF8')
在test.txt中写入hello world之后再运行上面的代码,内容会被清空(覆盖写入)
改成如下形式则是在原有内容后追加:
f=open("test.txt",'a',encoding='UTF8')
with open用法:可以自动关闭文件对象
with open("test.txt") as f:print(f.read())文件读取
read函数:文件对象.read(num)
num表示要从文件中读取的数据的长度(单位是字节),如果没有传入num,那么就表示读取文件中所有的数据。
如下:
f=open("test.txt",'r',encoding='UTF8')content=f.read()
print(content)
f.close()运行结果:
hello worldreadlines()方法:
readlines可以按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行的数据为一个元素。
修改test.txt为
hello world
111
222使用readlines()方法读取demo:
f=open("test.txt",'r',encoding='UTF8')content=f.readlines()
print(content)
f.close()运行结果:
['hello world\n', '111\n', '222']
readline()方法:一次读取一行内容
f=open("test.txt",'r',encoding='UTF8')content=f.readline()
print(f'第一行:{content}')content=f.readline()
print(f'第二行:{content}')
f.close()运行结果:
第一行:hello world第二行:111也可以用for循环读取文件行:
for line in open("test.txt", "r"):print(line)运行结果:
hello world111222文件写入
demo:往test2.txt中写入一段字符test
f=open("test2.txt",'w')
f.write("hello")
f.flush()结果:test.txt文件中hello world字符变成test字符
注意:
- 直接调用write,内容并未真正写入文件,而是会积攒在程序的内存中,称之为缓冲区
- 当调用flush的时候,内容会真正写入文件
- 这样做是避免频繁的操作硬盘,导致效率下降(攒一堆,一次性写磁盘)
文件追加
f=open("test2.txt",'a')
f.write("cc")
f.flush()注意事项:
- a模式,文件不存在,会创建新文件
- a模式,文件存在,会在原有内容后面继续写入
- 可以使用”\n”来写出换行符
综合案例
需求:将文件写道test.bak文件作为备份,同时将文件内包含测试一行的数据丢弃
aaa,2022-01-01,100000,消费,正式
bbb,2022-01-02,300000,收入,正式
ccc,2022-01-03,100000,消费,测试
aaa,2022-01-01,300000,收入,正式
aaa,2022-01-02,100000,消费,测试
bbb,2022-01-03,100000,消费,正式
aaa,2022-01-04,100000,消费,测试
bbb,2022-01-05,500000,收入,正式
ccc,2022-01-01,100000,消费,正式
aaa,2022-01-02,500000,收入,正式
bbb,2022-01-03,900000,收入,测试
bbb,2022-01-01,500000,消费,正式
ddd,2022-01-02,300000,消费,测试
aaa,2022-01-03,950000,收入,正式
bbb,2022-01-01,300000,消费,测试
bbb,2022-01-02,100000,消费,正式
ccc,2022-01-03,300000,消费,正式demo:
f=open("test3.txt",'r',encoding='utf-8')
f2=open("test.bak",'w',encoding='utf-8')for line in f:content=line.split(",")[-1].strip() //去空操作strip()很重要if content=="测试":continuef2.write(line)f2.flush()f.close()
f2.close()