All In One!Meta发布SeamlessM4T,支持100种语言,35种语音、开源、在线体验!
多语言识别翻译的研究一直都是学术界研究的重点。目前全球有几千种语言,在全球化背景下不同语言人群之间的交流越来越密切,然而学习一门外语的成本是非常大的。前两年的研究主要集中在一对一、一对多的研究,然而当面对这么多的语言时,既需要「考虑模型准确率,还需要考虑语种的识别」。最近,随着人工智能大型自然语言模型的发展,利用统一模型实现多语种识别翻译来实现不同语种之间交流逐渐的变成了可能。
最近「Meta刚刚发布的SeamlessM4T」,它在近「100种语言」中实现了最先进的结果,并在自动语音识别、语音转文本、语音转语音、文本转语音和文本转语音等方面实现了多任务支持——「全部集中在一个模型中」!
Paper:https://ai.meta.com/research/publications/seamless-m4t/
Code:https://github.com/facebookresearch/seamless_communication
Demo:https://huggingface.co/spaces/facebook/seamless_m4t
SeamlessM4T
构建通用语言翻译器是非常具有挑战性,因为现有的语音到语音和语音到文本系统仅涵盖世界语言的一小部分。SeamlessM4T 代表了语音到语音和语音到文本领域的重大突破,它解决了有限的语言覆盖范围和对单独系统的依赖的挑战;能够提供按需翻译,使使用不同语言的人们能够更有效地进行交流。,在英语、西班牙语和德语等资源丰富的语言上也保持着强劲的表现;除此之外,SeamlessM4T可以隐式的识别源语言,无需单独的语言识别模型。
SeamlessM4T统一多语言识别翻译模型特点总结:
-
自动语音识别近百种语言
-
近100种输入和输出语言的语音到文本翻译
-
语音翻译,支持近100种输入语言和35种(+英语)输出语言
-
近100种语言的文本到文本翻译
-
文本转语音翻译,支持近100种输入语言和35种(+英语)输出语言
目前Meta已经将模型开放出来供大家进行研究,但是必须遵循「不能商用」的许可。除此之外,他们还发布了迄今为止最大的开放多模式翻译数据集:「SeamlessAlign」,并且能够轻松使用 SONAR(一套完整的语音和文本句子编码器)和 stopes(多模式数据处理和并行数据挖掘库)对自己的单语言数据集进行挖掘。
SeamlessM4T实现方法
构建统一模型需要一个轻量级且易于与其他现代 PyTorch 生态系统库组合的序列建模工具包。Meta重新设计了fairseq,最初的序列建模工具包。凭借更高效的建模和数据加载器 API,fairseq2 有助于支持 SeamlessM4T 背后的建模。
对于模型,使用多任务UnitY模型架构,它能够直接生成翻译后的文本和语音。这种新架构还支持自动语音识别、文本到文本、文本到语音、语音到文本和语音到语音翻译,这些功能已经是普通 UnityY 模型的一部分。
多任务 UnitY 模型由三个主要的顺序组件组成。文本和语音编码器的任务是识别近100种语言的语音输入。然后,文本解码器将该含义转换为近100种文本语言,然后使用文本到单元模型将其解码为35种语音语言的离散声学单元。对自监督编码器、语音到文本、文本到文本翻译组件和文本到单元模型进行预训练,以提高模型的质量和训练稳定性。然后将解码的离散单元转换为 使用多语言 HiFi-GAN 单元声码器进行语音。
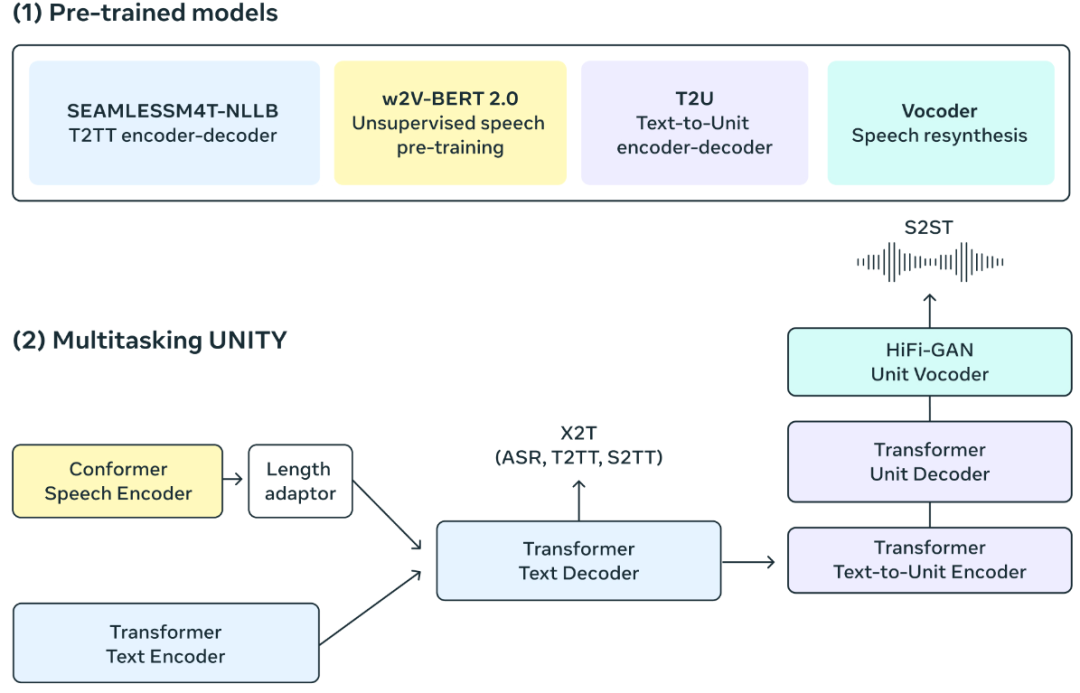
语音编码器
自监督语音编码器w2v-BERT 2.0是w2v-BERT的改进版本,提高了训练稳定性和表示质量,通过分析数百万小时的多语言语音来学习查找语音中的结构和含义。编码器获取音频信号,将其分解为更小的部分,并构建所说内容的内部表示。由于口语单词是由许多声音和字符组成的,因此我们使用长度适配器将它们粗略地映射到实际单词。
文本编码器
同样,我们有一个基于 NLLB 模型的文本编码器。它经过训练可以理解近 100 种语言的文本并生成对翻译有用的表示。
文本解码器
文本解码器经过训练可以采用编码的语音表示或文本表示。这可以应用于同一语言的任务,例如自动语音识别、多语言翻译任务。例如,某人可以用法语说出“bonjour”一词,并期望斯瓦希里语的翻译文本为“habari”。通过多任务训练,我们利用强大的文本到文本翻译模型(NLLB)的优势,通过标记级知识蒸馏来指导我们的语音到文本翻译模型。
语音解码器
使用声学单位来表示目标侧的语音。UnitY 模型中的文本到单元 (T2U) 组件根据文本输出生成这些离散语音单元,并在 UnityY 微调之前根据 ASR 数据进行预训练。然后使用多语言 HiFi-GAN 单元声码器将这些离散单元转换为音频波形。
最庞大的语料库
&emspSeamlessM4T模型受益于大量高质量的端到端数据,即语音到文本、语音到语音数据。仅依靠人工转录和翻译的语音无法应对100种语言的语音翻译任务。Meta基于在联合嵌入空间中使用相似性度量的文本到文本挖掘的开创性工作以及语音挖掘的初步工作来创建额外的资源来训练 SeamlessM4T 模型。
首先,为200种语言构建了一个新的大规模多语言和模态文本嵌入空间,名为 SONAR(句子级模态和语言无关表示),它在多语言相似性搜索方面大大优于LASER3或LaBSE等现有方法。然后,应用师生方法将此嵌入空间扩展到语音模态,目前涵盖35种语言。挖掘是在来自公开可用的网络数据存储库(数百亿个句子)和语音存储库(400 万小时)的数据中进行的。
总的来说,我们能够自动将超过443,000小时的语音与文本进行对齐,并创建约 29,000 小时的语音到语音对齐。该语料库被称为 SeamlessAlign,它是迄今为止就总容量和语言覆盖范围而言最大的开放语音/语音和语音/文本并行语料库。
实验结果
SeamlessM4T在近100种语言中实现了最先进的结果,并在自动语音识别、语音转文本、语音转语音、文本转语音和文本转语音等方面实现了多任务支持——全部集中在一个模型中。还显着提高了所支持的中低资源语言的性能,并保持了高资源语言的强劲性能。
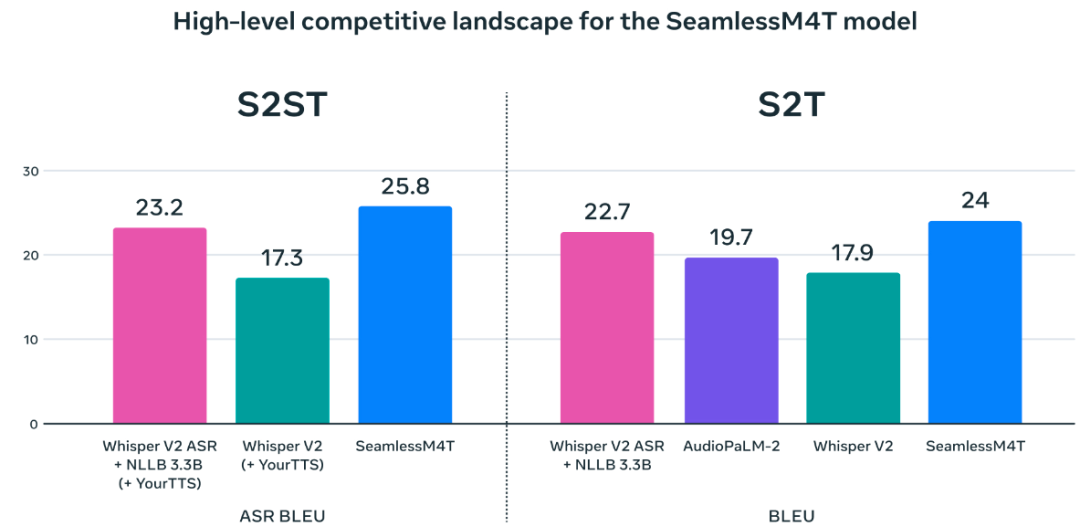
为了在不依赖基于文本的指标的情况下更准确地评估系统,将无文本指标扩展到BLASER 2.0,现在可以跨语音和文本单元进行评估,其准确性与其前身相似。在进行鲁棒性测试时,与当前最先进的模型相比,系统在语音转文本任务中针对背景噪声和说话人变化的表现更好(平均分别提高了37%和48%)。