npm和yarn的区别?
文章目录
- 前言
- npm和yarn的作用和特点
- npm和yarn的安装的机制
- npm安装机制
- yarn安装机制
- 检测包
- 解析包
- 获取包
- 链接包
- 构建包
- 总结
- 后言
前言
这一期给大家讲解npm和yarn的一些区别
npm和yarn的作用和特点
-
包管理:npm 和 yarn 可以用于安装、更新和删除 JavaScript 包。它们提供了一个集中的仓库,开发者可以从该仓库中获取并安装他们需要的包。这些包可以是第三方的开源库,也可以是自行编写的模块。
-
版本管理:npm 和 yarn 允许开发者指定所需包的版本。通过在项目的 package.json 文件中记录所使用的包及其版本号,确保团队成员或不同环境下代码的一致性。也可以快速升级包的版本,或者恢复到之前的版本。
-
依赖解决:当安装一个包时,该包可能会依赖其他包。npm 和 yarn 可以自动解决这些依赖关系,确保所有需要的包都能正确安装,并处理依赖包之间的冲突。
-
脚本管理:npm 和 yarn 允许在项目中定义一些脚本,用于执行常见的任务,如构建、测试等。可以使用预定义的脚本命令,或者自定义一些特定需求的脚本。
-
性能和稳定性:yarn 在性能和稳定性方面做了一些优化,例如并行安装依赖、缓存等。这使得它在速度和可靠性方面有一些优势。
npm和yarn的安装的机制
npm安装机制

npm install执行之后, 首先会检查和获取 npm的配置,这里的优先级为:
项目级的.npmrc文件 > 用户级的 .npmrc文件 > 全局级的 .npmrc > npm内置的 .npmrc 文件
然后检查项目中是否有 package-lock.json文件
-
如果有, 检查 package-lock.json和 package.json声明的依赖是否一致:
- 一致, 直接使用package-lock.json中的信息,从网络或者缓存中加载依赖
- 不一致, 根据上述流程中的不同版本进行处理
-
如果没有, 那么会根据package.json递归构建依赖树,然后就会根据构建好的依赖去下载完整的依赖资源,在下载的时候,会检查有没有相关的资源缓存:
- 存在, 直接解压到node_modules文件中
- 不存在, 从npm远端仓库下载包,校验包的完整性,同时添加到缓存中,解压到 node_modules中
最后, 生成 package-lock.json 文件
其实, 在我们实际的项目开发中,使用npm作为团队的最佳实践: 同一个项目团队,应该保持npm 版本的一致性。
yarn安装机制

检测包
这一步,最主要的目的就是检测我们的项目中是否存在npm相关的文件,比如package-lock.json等;如果有,就会有相关的提示用户注意:这些文件可能会存在冲突。在这一步骤中 也会检测系统OS, CPU等信息。
解析包
这一步会解析依赖树中的每一个包的信息:
首先呢,获取到首层依赖: 也就是我们当前所处的项目中的package.json定义的dependencies、devDependencies、optionalDependencies的内容。
紧接着会采用遍历首层依赖的方式来获取包的依赖信息,以及递归查找每个依赖下嵌套依赖的版本信息,并将解析过的包和正在进行解析包呢用Set数据结构进行存储,这样就可以保证同一版本范围内的包不会进行重复的解析

获取包
这一步首先我们会检查缓存中是否有当前依赖的包,同时呢将缓存中不存在的包下载到缓存的目录中。但是这里有一个小问题需要大家思考一下:
比如: 如何去判断缓存中有当前的依赖包呢?
其实呢,在Yarn中会根据 cacheFolder+slug+node_modules+pkg.name 生成一个路径;判断系统中是否存在该path,如果存在证明已经有缓存,不用重新下载。这个path也就是依赖包缓存的具体路径。
那么对于没有命中的缓存包呢?在 Yarn 中存在一个Fetch队列,按照具体的规则进行网络请求。如果下载的包是一个file协议,或者是相对路径,就说明指向一个本地目录,此时会调用Fetch From Local从离线缓存中获取包;否则调用 Fetch From External 获取包,最终获取的结果使用 fs.createWriteStream 写入到缓存目录。

链接包
我们上一步已经把依赖放到了缓存目录,那么下一步,我们应该要做什么事情呢?是不是应该把项目中的依赖复制到node_modules目录下呢,没错;只不过此时需要遵循一个扁平化的原则。复制依赖之前, Yarn会先解析 peerDepdencies,如果找不到符合要求的peerDepdencies的包,会有 warning提示,并最终拷贝依赖到项目中。
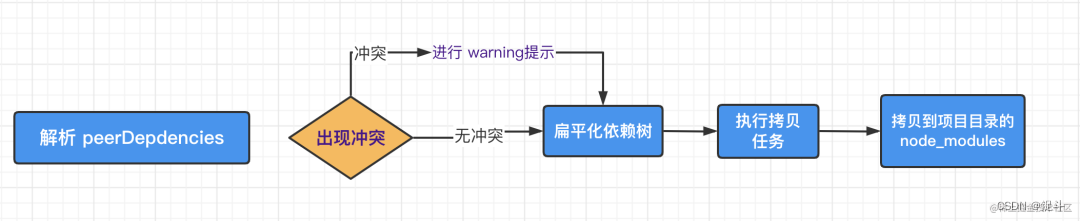
构建包
如果依赖包中存在二进制包需要进行编译,那么会在这一步进行。
千呼万唤始出来,这里要插一句话,感谢大家的捧场。为伊消得人憔悴,最近想的事情比较多,一直拖着实在是不好意思。那我们大家继续来一起整理:
其实, 从大家的评论中我去认真讨论和学到了一些新的东西pnmp和Lerna;之后如果时间充裕的话,我也会去研究研究和大伙一起讨论的,感谢大家伙的支持 💗。
总结
总体而言,npm 和 yarn 在功能上非常相似,都可以满足大部分的包管理需求。选择使用哪个工具主要取决于个人偏好、项目需求和团队的约定。如果你正在从一个工具迁移到另一个工具,建议在迁移之前进行充分的测试和验证。
后言
创作不易 如果本文章对您有帮助那么,请帮助作者三连一下!感谢观看