[PyTorch][chapter 51][Auto-Encoder -1]
目录:
- 简介
- 损失函数
- 自动编码器的类型
一 AutoEncoder 简介:
自动编码器是一种神经网络,用于无监督学习任务.(没有标签或标记数据),
例如降维,特征提取和数据压缩.
主要任务:
1: 输入数据
2: 输入数据压缩为 低维空间(也可以高维空间,很少用)
3: 低维空间 重构 输入数据
主要组件:
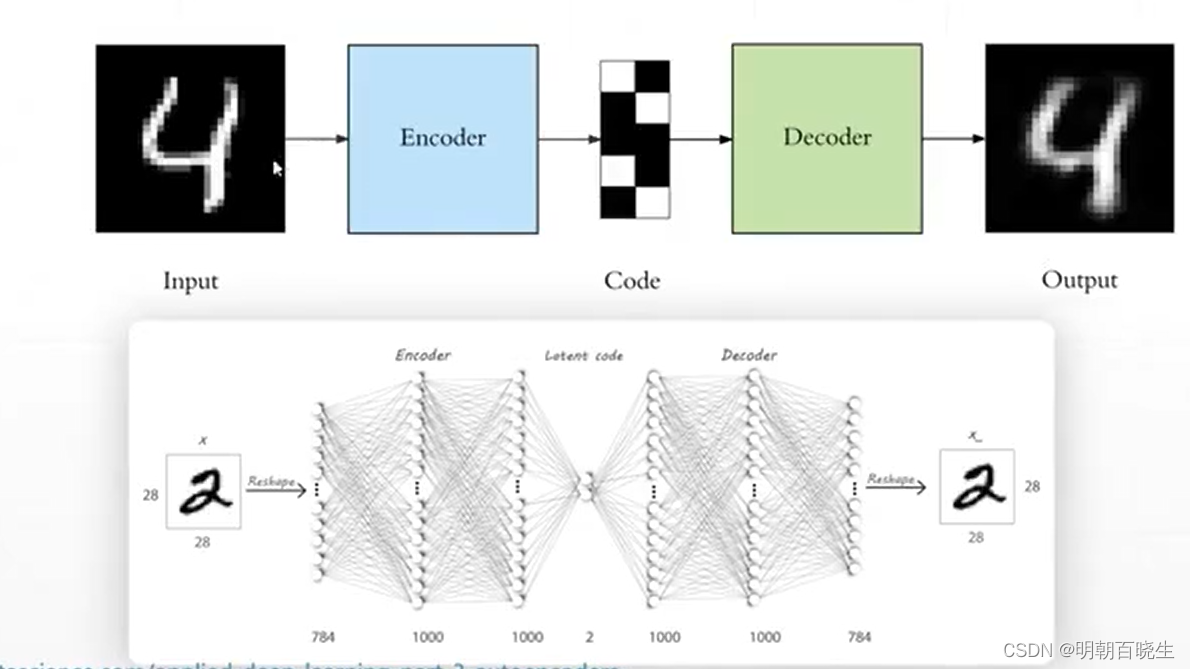
编码器(Encoder):
编码器将输入数据压缩为称为潜在空间或低维空间表示形式。这种潜在空间通常称为嵌入(Embedding),旨在保留尽可能多的信息。
如果我们将输入数据表示为x ,将编码器表示为 E,则输出低维空间s表示为s=E(x) 。
解码器(Decoder):
解码器通过接受低维空间表示s来重建原始输入数据。如果我们将解码器函数表示为D ,将检测器的输出表示为o ,那么我们可以将解码器表示为 o=D(s)
如下图: 中间的code 为低维空间
降维后的数据我们可以通过TensorBoard Projector 查看其相关性
我们也可以通过https://projector.tensorflow.org/ 在线工具查看。
二 损失函数
标签集用的是自身。
根据其数据特征常用交叉熵或者均方差作为损失函数.


三 自动编码器的类型
3.1 普通自动编码器
由编码器和解码器的一个或多个全连接层组成。
它适用于简单数据,可能难以处理复杂模式。

3.2 卷积自动编码器(CAE:Convolutional Autoencoder)
在编码器和解码器中利用卷积层,使其适用于处理图像数据。通过利用图像中的空间信息,CAE可以比普通自动编码器更有效地捕获复杂的模式和结构,并完成图像分割等任务。

3.3 降噪自动编码器(Denoising Autoencoder)
De-noising Auto-encoder
该自动编码器旨在消除损坏的输入数据中的噪声,如图6所示。在训练期间,输入数据通过添加噪声故意损坏,而目标仍然是原始的、未损坏的数据。自动编码器学习从噪声输入中重建干净的数据,使其可用于图像去噪和数据预处理任务。

应用2:
- De-noising Auto-encoder是 Auto-encoder的常见变型之一。给原来要输入进去的图片加入噪声后,试图还原原来的图片(加入噪声前的)
- 设计DAE的初衷就是在自动编码器的基础之上,为了防止过拟合问题而对输入层的输入数据加入噪音,使学习得到的编码器具有鲁棒性,是Bengio在08年论文《Extracting and composing robust features with denoising autoencoders》提出的。

3.4 稀疏自动编码器(Sparse Autoencoder)
Dropout 权重系数部分参数为0
这种类型的自动编码器通过向损失函数添加稀疏性约束来强制潜在空间表示的稀疏性(如图 7 所示)。此约束鼓励自动编码器使用潜在空间中的少量活动神经元来表示输入数据,从而实现更高效、更稳健的特征提取

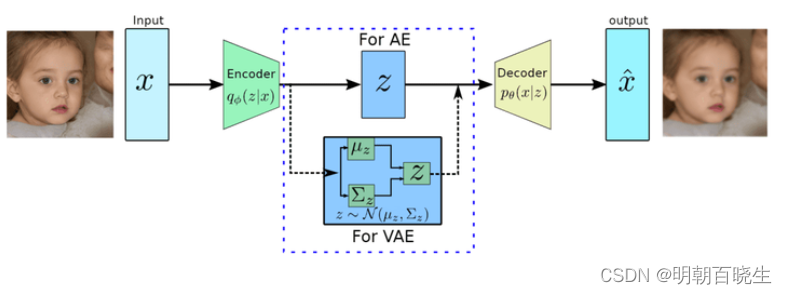
3.5 变分自动编码器(VAE:Variational Autoencoder)
该模型在潜在空间中引入了概率层,允许对新数据进行采样和生成。VAE可以从学习到的潜在分布中生成新的样本,使其成为图像生成和风格迁移任务的理想选择。
3.6 序列间自动编码器(Sequence-to-Sequence Autoencoder)
这种类型的自动编码器也称为循环自动编码器,在图 9 所示的编码器和解码器中利用循环神经网络 (RNN) 层(例如,长短期记忆 (LSTM) 或门控循环单元 (GRU))。此体系结构非常适合处理顺序数据(例如,时间序列或自然语言处理任务)。

3.7 Feature Disentanglement(特征分离)
特征分离技术可以做到,在训练的同时,将vector中不同内容的特征分开(可以知道哪些维度代表哪些特征)。如下图所示,可以做到将content和speaker两种信息分离。

- Feature Disentangle一个比较常见的应用就是:Voice Conversion(音色转换)
- 在过去,要想转换两个speaker的音色,他们必须将相同的话各自都读一遍,但这几乎不能实现(实现起来很困难);而现在,在Feature Disentangle的帮助下,两个speaker不需要读相同的内容,就能完成音色的转换。
- 由于Feature Disentangle可以做到将content和speaker两种信息分离,所以就可以完成下面的例子,也就是Voice Conversion。用一个人的声音读出另一个人的话。
课时108 无监督学习_哔哩哔哩_bilibili
Auto-encoder (李宏毅笔记) - 知乎
自动编码器(AutoEncoder)简介 - 知乎