ACL2023 Prompt 相关文章速通 Part 1
Accepted Papers
link: ACL2023 main conference accepted papers
文章目录
- Accepted Papers
- Prompter: Zero-shot Adaptive Prefixes for Dialogue State Tracking Domain Adaptation
- Query Refinement Prompts for Closed-Book Long-Form QA
- Prompting Language Models for Linguistic Structure
- Zero-shot Approach to Overcome Perturbation Sensitivity of Prompts
- PMAES: Prompt-mapping Contrastive Learning for Cross-prompt Automated Essay Scoring
- Exploring Lottery Prompts for Pre-trained Language Models
- Marked Personas: Using Natural Language Prompts to Measure Stereotypes in Language Models
- MultiTool-CoT: GPT-3 Can Use Multiple External Tools with Chain of Thought Prompting
- END
Prompter: Zero-shot Adaptive Prefixes for Dialogue State Tracking Domain Adaptation
将 soft prompt 以及 Hyper Prompt 架构用在了对话情景追踪(DST)任务上,详见这篇博客。
Query Refinement Prompts for Closed-Book Long-Form QA
文章链接
又是一个没见过的任务,Closed-Book Long-Form QA,字面意思就是闭卷长QA。显而易见有两个约束,一个是闭卷,也就是LLM只能基于预训练的知识做回答;另一个是长,这里指QA的A即回答比较长。这个任务的实例由作者给出:

这个任务的问题就比较笼统,答案是可以说很多的,作者就将其总结为多角度回答,具体来讲就是回答一个这样的问题分为3步:
- 将这个笼统的大问题拆分成几个不同方面的子问题;
- 回答不同的子问题;
- 将子问题的答案组织成一个连贯的长回答。
作者也是受CoT的启发,将“拆分子问题”这个过程显式地加在输出里,让LLM产生更好的输出。实际上做法很经典,用几个人工的demo做few-shot,从demo库里面按照相似度找跟当前问题最相似的demo做few-shot。
思路是CoT的,应用在了比较小众的一个问题上。
Prompting Language Models for Linguistic Structure
文章链接
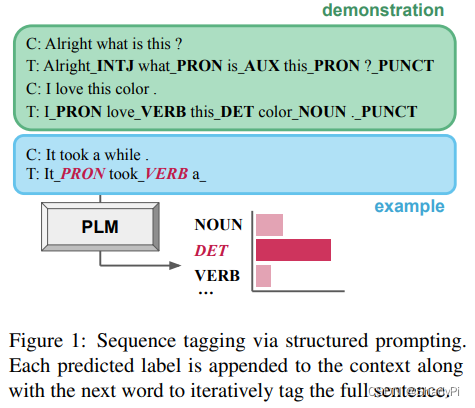
任务是给PLM样例让PLM给句子的每个单词打词性标签,从而研究PLM是否理解的语言,还是只是单纯的缝合训练数据。结论是PLM的语言能力应该是比单纯的记忆训练数据高的。
Zero-shot Approach to Overcome Perturbation Sensitivity of Prompts
文章链接
给一个base prompt,该工作生成一个更好的prompt,同时保证zero-shot,即不使用验证集来评估生成的prompt的好坏,而是用new metric来选出更好的prompt。这个setting还是挺好的,确实很多prompt generate的工作需要验证集来评估生成的prompt的好坏从而筛选。
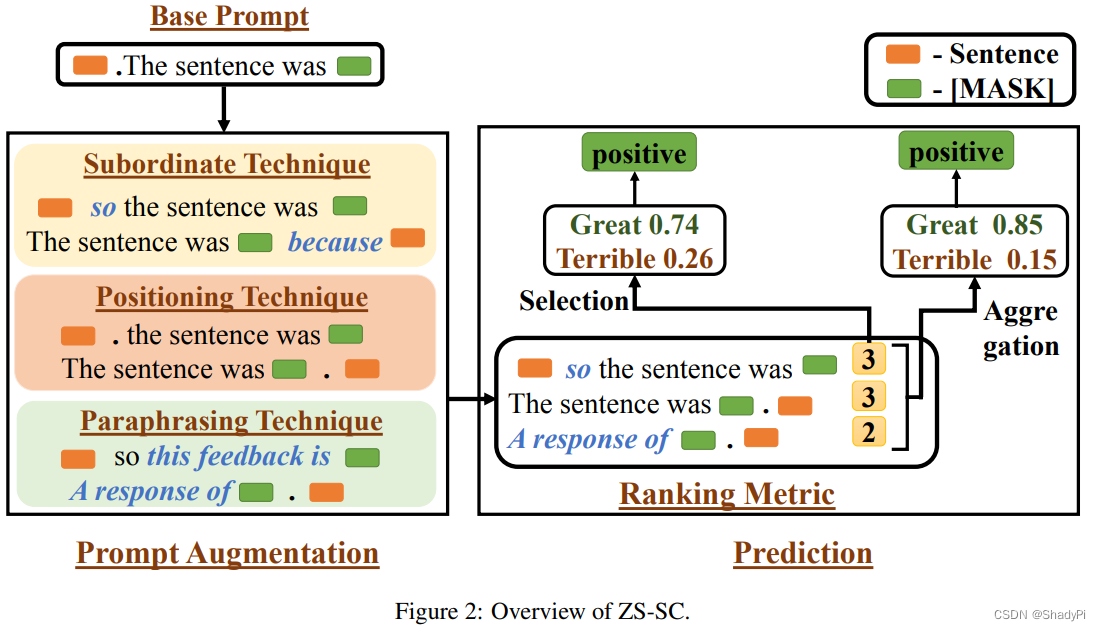
然而细细观之,作者的做法比较复古,作者说主要是针对低资源场景的,因此模型也只用了BERT,任务也仅考虑了情感分析任务。
首先生成Prompt的方式是类似GrIPS的操作,在单词层面对base prompt进行修改,分为换位置(prompt放在input前面/后面)、加连词(prompt在前面时用because连接,放在后面时用so连接)以及用BERT paraphrase某个token。
打分是重头戏的部分,作者的打分基于一个假设:好的prompt应该对一些“关键词”敏感,比如说“This film is great.”的情感是positive, 那在这个“great”变成反义词,如“terrible”的时候,情感就该反转变成negative。类似地,变成同义词这个情感就该不变。由此,作者就通过prompt对关键词的敏感程度来评判prompt的好坏,而不需要知道真正的label是什么。
看下来感觉这个操作类似于数据增强,作者的这个想法还是很有意思的,但应用范围目前还只局限于二分类任务。同时我认为带有“关键词”的输入本身就比较简单,都能找到关键词了那么其实离正确答案也不远了。但作者的立意比较新,而且基于BERT,主打low resource。
PMAES: Prompt-mapping Contrastive Learning for Cross-prompt Automated Essay Scoring
文章链接
这篇好像跟prompt engineer的prompt不是一个意思啊,是为文章进行打分的,不知道essay的prompt是个什么东东?
Exploring Lottery Prompts for Pre-trained Language Models
文章链接,简洁但有效的搜索并集成prompt的方法,详见这篇博客
Marked Personas: Using Natural Language Prompts to Measure Stereotypes in Language Models
文章链接
看名字就知道是偏人文的,主要考察LLM对人类群体的刻板印象,大体上的思路是让LLM生成对某个种族或者别的群体的描述,分析其中的情感,就不细说了。
MultiTool-CoT: GPT-3 Can Use Multiple External Tools with Chain of Thought Prompting
文章链接
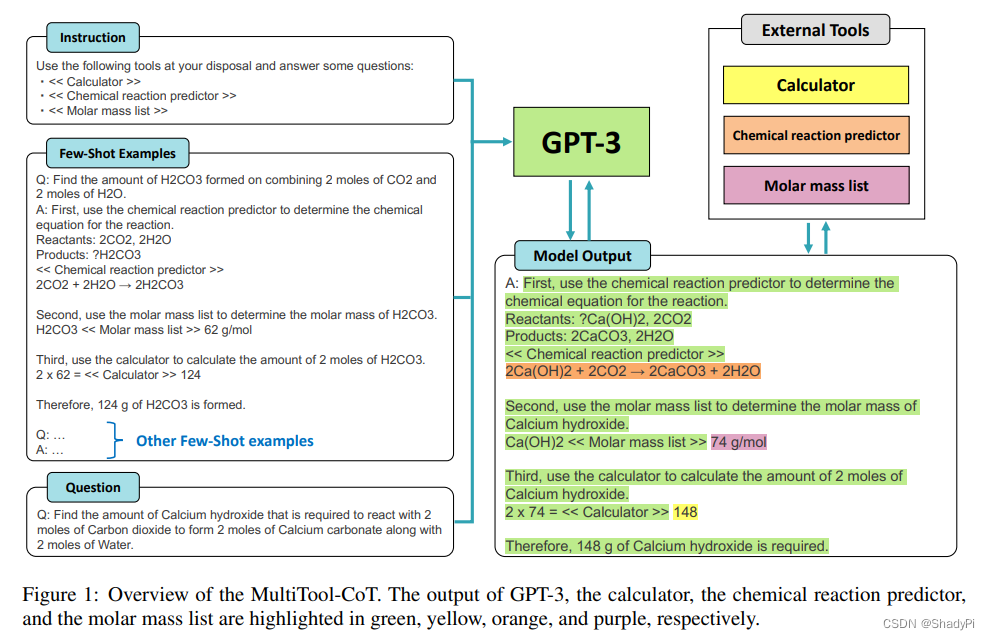
用Few-shot-CoT的方式教会LLM使用外部工具,样例中有一些特别的token,在LLM输出这些token的时候就会调用外部工具,比如计算器和化学反应工具,弥补LLM的专业技能。方法不复杂,作者称他们是SOTA。
END
暂时先更到这里,剩下的文章以后再看。