pytest数据驱动

文章目录
- 一、数据驱动概念
- 二、数据驱动yaml
- 1、yaml的基本语法:
- 2、yaml支持的数据格式:
- 3、安装
- 4、使用
- 5、读取方法
- a、目录结构
- b、yaml文件
- c、测试方法
- d、测试用例
- e、测试结果
- 三、数据驱动excel
- 1、安装导入
- 2、操作
- 3、读取方法
- a、目录结构
- b、excel文件
- c、测试方法
- d、测试用例
- e、测试结果
- 四、数据驱动csv
- 1、读取数据
- 2、方法
- a、目录结构
- b、csv文件
- c、测试方法
- d、测试用例
- e、测试结果
- 五、数据驱动json
- 1、json格式:
- 2、读取json文件
- a、目录结构
- b、json文件
- c、测试方法
- d、测试用例
- e、测试结果
一、数据驱动概念
数据驱动就是数据的改变从而驱动自动化测试的执行,最终引起测试结果的改变。简单来说,就是参数化的应用。数据量小的测试用例可以使用代码的参数化来实现数据驱动,数据量大的情况下建议大家使用一种结构化的文件(例如yaml,json,csv、excel等)来对数据进行存储,然后在测试用例中读取这些数据。
二、数据驱动yaml
yaml是一种数据序列化格式,用于人类的可读性和与脚本语言的交互,一种被认为超越XML、json的配置文件。
1、yaml的基本语法:
大小写敏感
使用缩进标识层级关系
缩进时不允许使用tab键,只允许使用空格
缩进的空格数目不重要,只要相同层级的元素左侧对齐即可
#表示注释,从这个字符一直到行尾,都会被解析器忽略
2、yaml支持的数据格式:
对象(字典):键值对的集合,用冒号“:”表示
数组(列表):一组按次序排列的值,前加“-”
纯量:单个的、不可再分的值
字符串
布尔值
整数
浮点数
Null
时间
日期
3、安装
pip install pyyaml
4、使用
datas:测试数据
func:测试方法
testcases:测试用例
5、读取方法
yaml.safe_load(file)
a、目录结构

b、yaml文件
# [[1,1,2],[3,6,9],[100,200,300]]
-- 1- 1- 3
-- 3- 6- 9
-- 100- 200- 300
c、测试方法
#被测方法,相加功能
def my_add3(x, y):result = x + yreturn result
d、测试用例
文件或者目录不可以创建为yaml关键字
import pytest
from testing_data.func.operation_yaml import my_add#用到yaml文件中的数据时,就需要读取出来# pip install pyyaml
#todo 文件或者目录不可以创建为yaml关键字
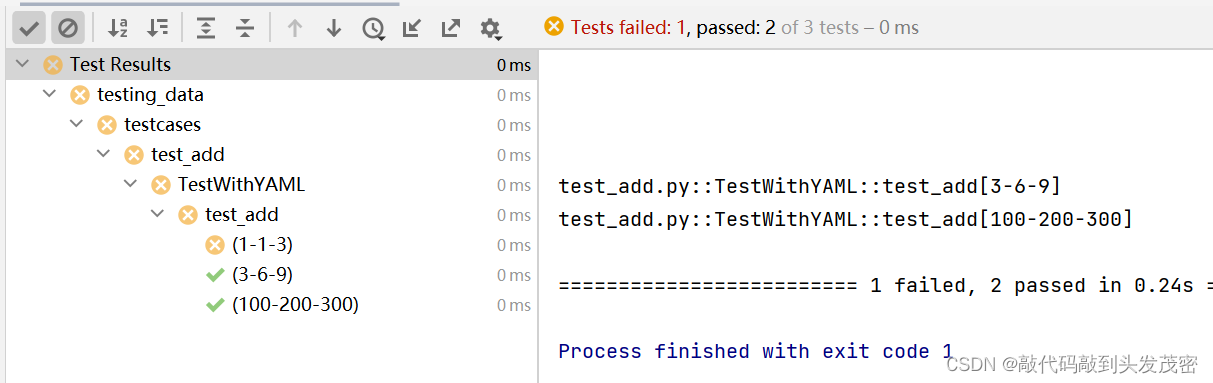
import yamldef get_data():#如果yaml文件有中文,必须加上excoding='utf-8'with open('../datas/data.yaml',encoding='utf-8') as f:data=yaml.safe_load(f)return dataclass TestWithYAML:@pytest.mark.parametrize('x,y,expected',get_data())def test_add(self, x, y, expected):assert my_add(int(x), int(y)) == int(expected)
e、测试结果
三、数据驱动excel
1、安装导入
pip install openpyxl
import openpyxl
2、操作
读取工作簿
读取工作表
读取单元格
3、读取方法
book=openpyxl.load_workbook(‘文件路径’) :读取工作簿
sheet=book.active :读取工作表
cells=sheet[‘A1’:‘C3’]
cell.value :读取数据
a、目录结构
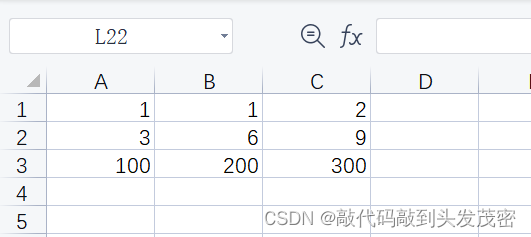
b、excel文件
c、测试方法
#被测方法,相加功能
def my_add1(x, y):result = x + yreturn result
d、测试用例
import openpyxl
import pytest
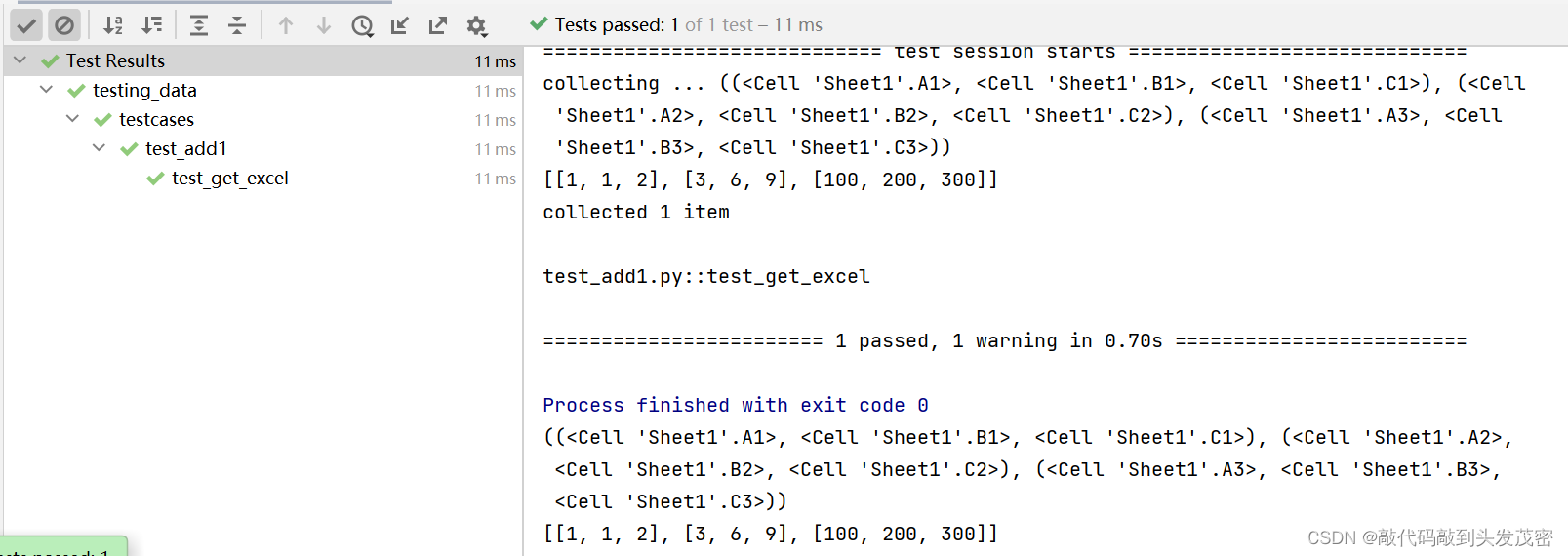
from testing_data.func.operation_excel import my_add1#用到excel文件中的数据时,就需要读取出来def test_get_excel():"""解析Excel数据:return: [[1,1,2],[3,6,9],[100,200,300]]"""#获取工作簿book=openpyxl.load_workbook('../datas/data.xlsx')#获取工作表sheet1sheet=book.active#读取数据cells=sheet['A1':'C3']print(cells)values=[]for row in cells:data=[]for cell in row:data.append(cell.value)values.append(data)print(values)return valuesclass TestWithEXCEL:@pytest.mark.parametrize('x,y,expected',test_get_excel(),ids=[1,2,3])def test_add1(self, x, y, expected):assert my_add1(int(x), int(y)) == int(expected)
e、测试结果
四、数据驱动csv
格式:逗号分隔值
以纯文本形式存储数字和文本
文件由任意数目的记录组成
每行记录由多个字段组成
1、读取数据
内置模块:import csv
2、方法
raw=csv.reader(iterable)
参数:iterable是一个可迭代对象;返回迭代器,每次迭代会返回一行数据
csv文件

读取csv文件
import csvdef get_csv():with open('demo.csv','r',encoding='utf-8') as file:raw=csv.reader(file)for line in raw:print(line)if __name__ == '__main__':get_csv()
读取结果:
['富强', '明主', '文明', '和谐']
['自由', '平等', '公正', '法制']
['爱国', '诚信', '敬业', '友善']
a、目录结构
b、csv文件
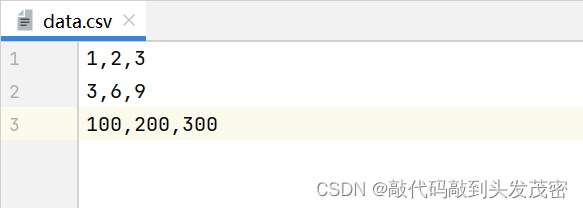
c、测试方法
#被测方法,相加功能
def my_add2(x, y):result = x + yreturn resultd、测试用例
import csvimport pytest
from testing_data.func.operation_csv import my_add2#用到csv文件中的数据时,就需要读取出来
def get_csv():"""读取csv文件中的数据:return: 格式:[[1,2,3],[3,6,9]]"""with open('../datas/data.csv','r',encoding='utf-8') as file:raw=csv.reader(file)data=[]for line in raw:data.append(line)print(data)return dataclass TestWithCSV:@pytest.mark.parametrize('x,y,expected',get_csv())def test_add2(self, x, y, expected):assert my_add2(int(x), int(y)) == int(expected)
e、测试结果
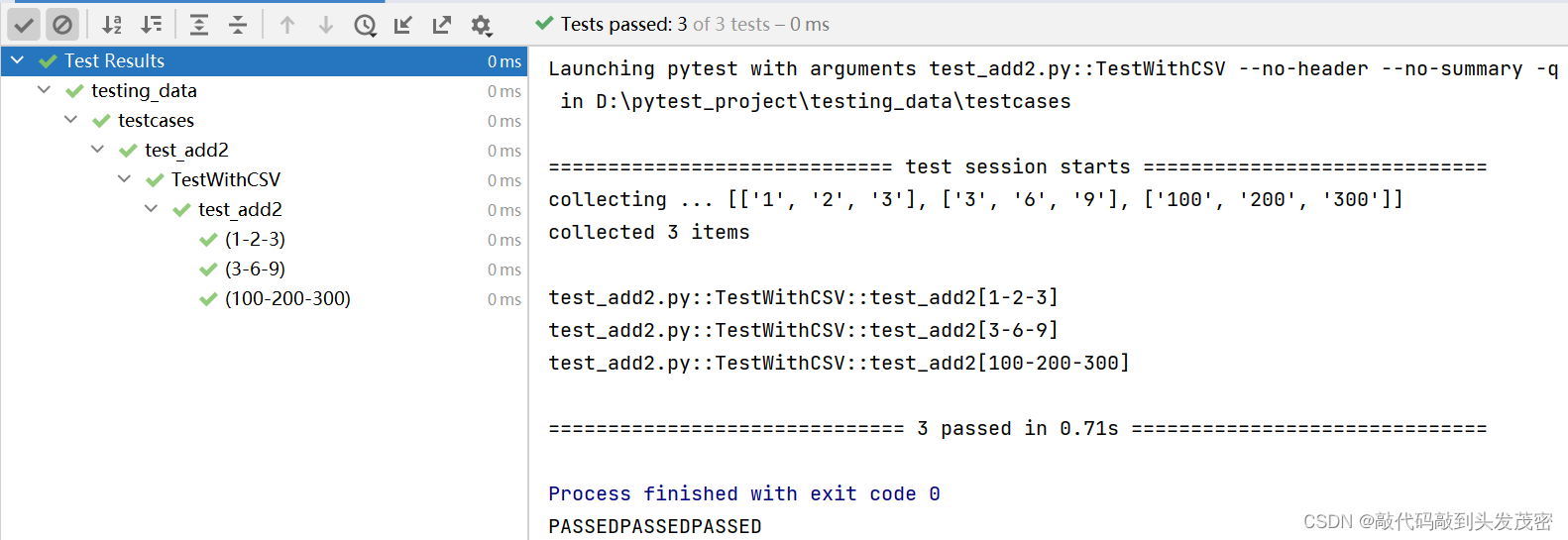
五、数据驱动json
1、json格式:
是一种轻量级的数据交换格式
以键值对的格式存储数据,多个键值用逗号分割
支持嵌套
支持数组(列表)
{"name:": "study ","detail": {"course": "python","city": "北京"},"remark": [1000,666,888]
}
2、读取json文件
内置库:
import json
内置方法
json.loads()
json.dumps()
import jsondef get_json():with open('demo.json','r',encoding='utf-8') as file:data=json.loads(file.read())print(data,type(data))data1=json.dumps(data, ensure_ascii=False)print(data1,type(data1))if __name__ == '__main__':get_json()
读取结果
{'name:': 'study ', 'detail': {'course': 'python', 'city': '北京'}, 'remark': [1000, 666, 888]} <class 'dict'>
{"name:": "study ", "detail": {"course": "python", "city": "北京"}, "remark": [1000, 666, 888]} <class 'str'>
a、目录结构
b、json文件
{"case1": [1, 1, 2],"case2": [3, 6, 9],"case3": [100, 200, 300]
}
c、测试方法
#被测方法,相加功能
def my_add3(x, y):result = x + yreturn resultd、测试用例
import json
import pytest
from testing_data.func.operation_json import my_add3#用到json文件中的数据时,就需要读取出来
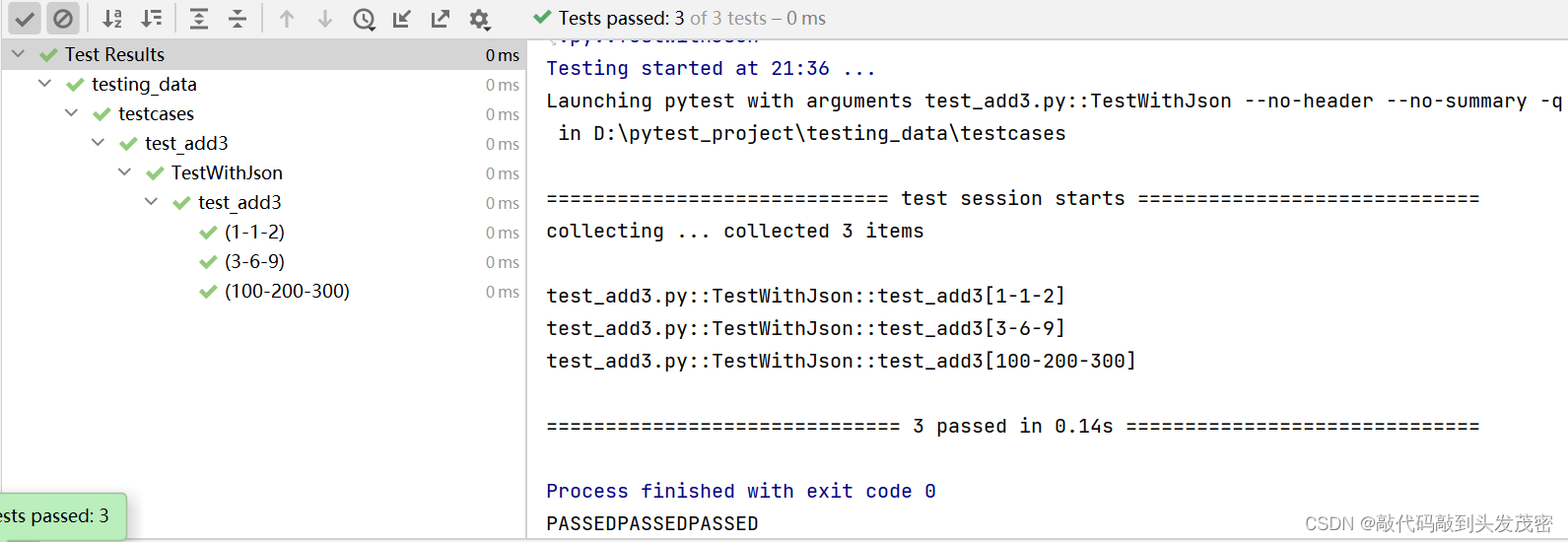
def get_json():"""读取json文件中的数据:return: 格式:[[1,2,3],[3,6,9]]"""with open('../datas/data.json','r',encoding='utf-8') as file:data=json.loads(file.read())data_values=data.values()return list(data_values)class TestWithJson:@pytest.mark.parametrize('x,y,expected',get_json())def test_add3(self, x, y, expected):assert my_add3(int(x), int(y)) == int(expected)
e、测试结果