Elasticsearch也能“分库分表“,rollover实现自动分索引
一、自动创建新索引的方法
MySQL的分库分表大家是非常熟悉的,在Elasticserach中有存在类似的场景需求。为了不让单个索引太过于庞大,从而引发性能变差等问题,我们常常有根据索引大小、时间等创建新索引的需求,解决方案一般有两个:
1、开发一个定时任务调用Elasticsearch索引API创建新索引,应用程序兼容新索引的命名规则;
2、使用Elasticsearch rollover功能。
第二种Elasticsearch自带的功能更加简单方便,无需定时任务。我们今天的主角就是Elasticsearch rollover功能。

二、使用rollover自动创建新索引
2.1、rollover API介绍
Elasticsearch rollover是Elasticsearch中一项用于管理索引的功能,它可以自动创建新的索引并将旧的索引移动到另一个位置,从而使历史数据不受影响,同时可以为新的索引设置不同的设置。它还可以根据特定的时间间隔(比如每天)来滚动索引,这可以有效地降低索引大小,提高搜索性能。
rollover的原理是先创建一个带别名的索引,然后设定一定的规则(例如满足一定的时间范围的条件),当满足该设定规则的时候,Elasticsearch会自动建立新的索引,别名也自动切换指向新的索引,这样相当于在物理层面自动建立了索引的分区功能,当查询数据落在特定时间内时,会到一个相对小的索引中查询,相对所有数据都存储在一个大索引的情况,可以有效提升查询效率。
rollover API会为data stream或者索引别名创建一个新的索引。(在Elasticsearch 7.9之前,一般使用索引别名的方式来管理时间序列数据,在Elasticsearch之后data stream取代了这个功能,它维护更加简单,并自动与数据层集成)。
rollover API的效果依据待滚动的索引别名的情况不同而有不同的表现:
- 如果一个索引别名对应了多个索引,其中一个一定是写索引,rollover创建出新索引的时候会设置
is_write_index为true,并且上一个被滚动的索引的is_write_index设置为false。 - 如果待滚动的索引别名对应的只有一个索引,那么在创建新的索引的同时,会删除原索引。
使用rollover API的时候如果指定新的索引的名称,并且原索引以“-”结束并且以数字结尾,那么新索引将会沿用名称并且将数字增加,例如原索引是my-index-000001那么新索引会是my-index-000002。
如果对时间序列数据使用索引别名,则可以在索引名称中使用日期来跟踪滚动日期。例如,可以创建一个别名来指向名为<my-index-{now/d}-000001>的索引,如果在2099年5月6日创建索引,则索引的名称为my-index-2099.05.06-000001。如果在2099年5月7日滚动别名,则新索引的名称为my-index-2099.05.07-000002。
rollover API的格式如下:
POST /<rollover-target>/_rollover/POST /<rollover-target>/_rollover/<target-index>
rollover API也支持Query Parameters和Request Body,其中Query parameters支持wait_for_active_shards、master_timeout、timeout和dry_run,特别说一下dry_run,如果将dry_run设置为true,那么这次请求不会真的执行,但是会检查当前索引是否满足conditions指定的条件,这对于提前进行测试非常有用。
Request Body支持aliases、mappings和settings(这三个参数只支持索引,不支持data stream)和conditions。
特别展开讲一下conditions。这是一个可选参数,如果指定了conditions,则需要在满足conditions指定的一个或者多个条件的情况下才会执行滚动,如果没有指定则无条件滚动,如果需要自动滚动,可以使用ILM Rollover。
conditions支持的属性有:
max_age
从索引建立开始算起的时间周期,支持Time Units,如7d、4h、30m、60s、1000ms、10000micros、500000nanos。max_docs
索引主分片的数量达到设定的值;max_size
所有主分片的大小之和达到了设定值,可以通过_cat indices API进行查询,其中pri.store.size的值就是目标值。max_primary_shard_size
所有主分片中存在主分片的大小达到了设定值,可以通过_cat shards API查看分片的大小,store值代表每个分片的大小,prirep代表了分片是primary分片还是replica分片。max_primary_shard_docs
所有主分片中存在主分片的文档大小达到了设定值,可以通过_cat shards API查询,其中的docs字段代表了分片上文档数量的大小。
2.2、rollover一个索引
- 首先创建一个索引并且设置为write index。
# PUT <my-index-{now/d}-000001>
curl -X PUT "localhost:9200/%3Cmy-index-%7Bnow%2Fd%7D-000001%3E?pretty" -H 'Content-Type: application/json' -d'
{"aliases": {"my-alias": {"is_write_index": true}}
}
'
-
执行rollover API
如下所示,代表间隔7天、文档数量最多达到100000、主分片大小达到50gb、主分片最大文档数量达到20000,这些条件中哪个先匹配则都会自动切换到新索引。
curl -X POST "localhost:9200/my-alias/_rollover?pretty" -H 'Content-Type: application/json' -d'
{"conditions": {"max_age": "7d","max_docs": 100000,"max_primary_shard_size": "50gb","max_primary_shard_docs": "20000"}
}
'
如果别名的索引名称使用日期数学表达式,并且按定期间隔滚动索引,则可以使用日期数学表达式来缩小搜索范围。例如,下面的搜索目标是最近三天内创建的索引。
# GET /<my-index-{now/d}-*>,<my-index-{now/d-1d}-*>,<my-index-{now/d-2d}-*>/_search
curl -X GET "localhost:9200/%3Cmy-index-%7Bnow%2Fd%7D-*%3E%2C%3Cmy-index-%7Bnow%2Fd-1d%7D-*%3E%2C%3Cmy-index-%7Bnow%2Fd-2d%7D-*%3E/_search?pretty"
2.3、rollover data stream
rollover不仅可以针对index,也可以针对data stream。data stream是 Elastic Stack 7.9 的一个新的功能。Data stream 使你可以跨多个索引存储只追加数据的时间序列数据,同时为请求提供唯一的一个命名资源,搜索请求提交给data stream以后,data stream会自动将请求路由到其后备的索引中。
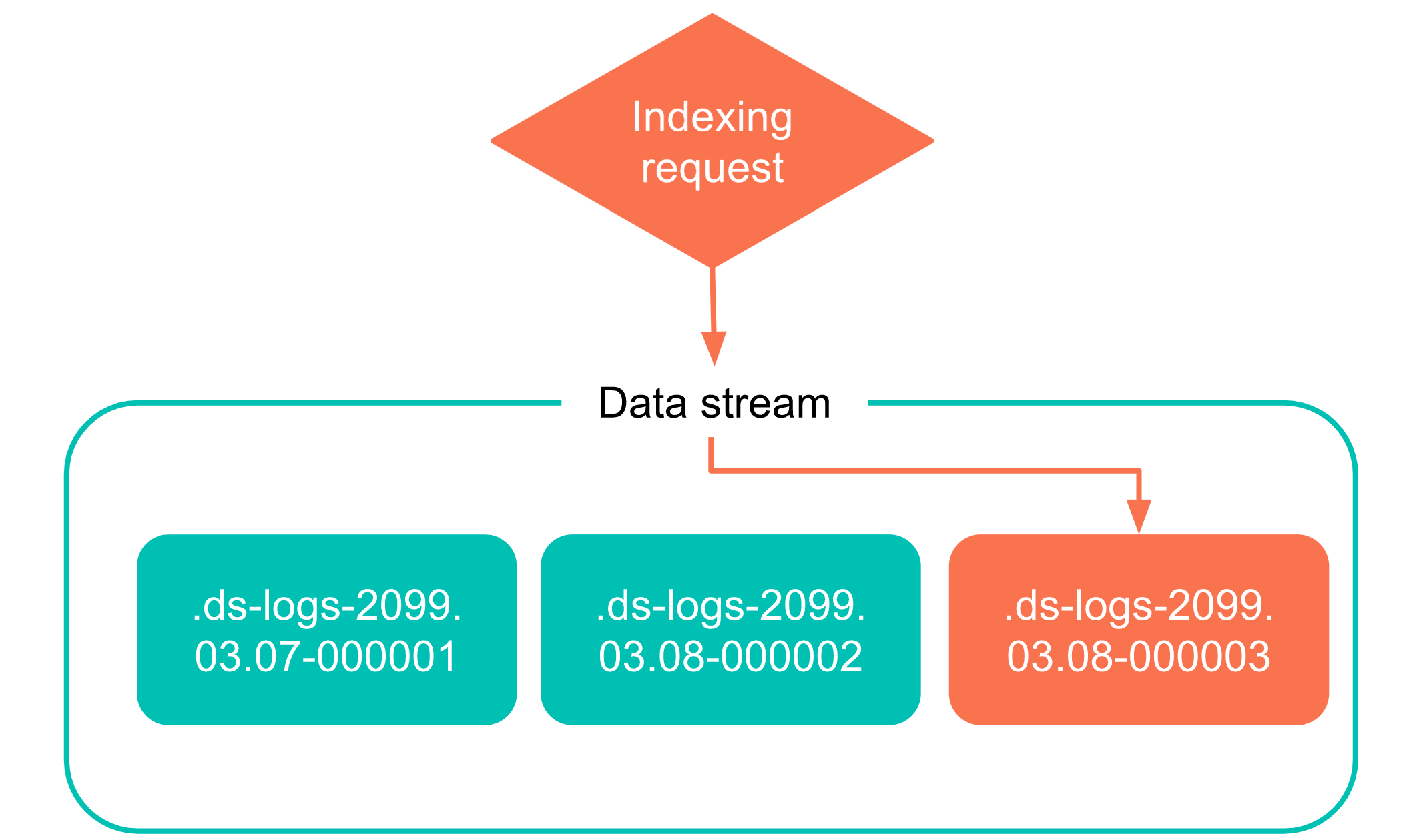
rollover data stream与index类似,如下:
curl -X POST "localhost:9200/my-data-stream/_rollover?pretty" -H 'Content-Type: application/json' -d'
{"conditions": {"max_age": "7d","max_docs": 100000,"max_primary_shard_size": "50gb","max_primary_shard_docs": "20000"}
}
'
响应信息如下,当max_docs数量达到了100000,自动会创建一个new_index,命令为".ds-my-data-stream-2099.05.07-000002"。
{"acknowledged": true,"shards_acknowledged": true,"old_index": ".ds-my-data-stream-2099.05.06-000001","new_index": ".ds-my-data-stream-2099.05.07-000002","rolled_over": true,"dry_run": false,"conditions": {"[max_age: 7d]": false,"[max_docs: 100000]": true,"[max_primary_shard_size: 50gb]": false,"[max_primary_shard_docs: 2000]": false}
}
rollover是一个非常实用的功能,特别是对于随着时间推移,索引数据量会快速增长的场景。不过也需要注意conditions要设置合理,否则容易产生太多的小索引,Elasticsearch集群对于索引的维护成本也是比较高的,太多的小索引会严重影响集群的性能。
你所在团队是否有遇到过需要自动分索引的场景,又是如何处理的呢?欢迎和我分享交流。