数据在内存中的存储【上篇】
文章目录
- ⚙️1.数据类型的详细介绍
- 🔩1.1.类型的基本归类
- ⚙️2.整型在内存中的存储
- 🔩2.1.原码、反码、补码
- 🔩2.2.大小端的介绍

⚙️1.数据类型的详细介绍
🥳基本的内置类型 :
💡char ---------- 字符数据类型 ----- 1 byte(8 bit)
💡short --------- 短整型 -------------- 2 byte(16 bit)
💡 int ------------- 整型 ---------------- 4 byte(32 bit)
💡long ---------- 长整型 -------------- 4/8 byte(32/64 bit)
💡long long ---- 更长的整型 ------- 8 byte(64 bit)
💡 float ---------- 单精度浮点型 ---- 4 byte(32 bit)
💡double ------- 双精度浮点型 ---- 8 byte(64 bit)
🔩1.1.类型的基本归类
🥳整型家族:
🔔 char :
👉 unsigned char
👉 signed char🔔 short :
👉 unsigned short [int]
👉 signed short [int]🔔 int :
👉 unsigned int
👉 signed int🔔 long :
👉 unsigned long [int]
👉 signed long [int]
🔴字符存储和表示的时候本质上使用的是 ASCII 值,ASCII 值是整数,所以字符类型也归类到整型家族里
🔴 signed :有符号型 (可表示正数也可表示负数); unsigned :无符号型 (只能表示正数)
🔴char 是不是 signed char 是取决于编译器的 (一般编译器下,char 就是 signed char)如果要写无符号型就必须使用 unsigned char
⚙️2.整型在内存中的存储
🥰 一个变量的创建是要在内存中开辟空间的,空间的大小是根据不同的类型而决定的
🔴 内存中存储的都是二进制数据
🔩2.1.原码、反码、补码
📍计算机中的整数有三种二进制表示方法:原码、反码、补码
📍三种表示方法均有符号位和数值位两部分组成,符号位都是用0表示“正”,用1表示“负”
📍正数的原码、反码、补码都相同,负数则需要计算
🙌原码:把一个数按照正负直接翻译成二进制就是原码
比如5: 00000000000000000000000000000101
比如-5:10000000000000000000000000000101
最高的一位表示符号位,0表示正数,1表示负数
🙌反码:原码的符号位不变,其他位按位取反就是反码
-5 : 11111111111111111111111111111010
🙌补码:反码+1
-5 : 11111111111111111111111111111011
👇我们来看一下数据在存储和运行使用的时候,存的到底是什么码的二进制👇
👇因为正整数的原码、反码、补码都相同,所以我们要用负数来观察👇
int main()
{int a = -10;//00000000000000000000000000001010 -- 原码//11111111111111111111111111110101 -- 反码//11111111111111111111111111110110 -- 补码return 0;
}
我们进入调试,看一下内存👇
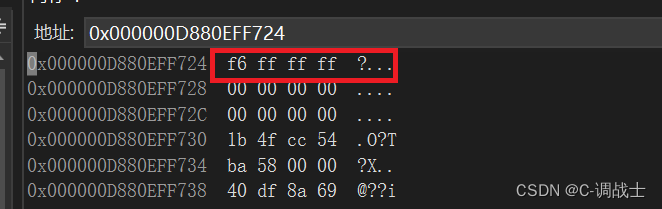

为了方便展示,内存中显示的是十六进制,实际上存的是二进制,由上图通过调试可以看出:数据存放内存中其实存放的是补码
🙌那么为什么呢?
📍在计算机系统中,数值一律用补码来表示和存储。原因在于,使用补码,可以将符号位和数值域统一处理;
📍同时,加法和减法也可以统一处理(CPU只有加法器)此外,补码与原码相互转换,其运算过程是相同的,不需要额外的硬件电路
🔩2.2.大小端的介绍
🥳数据的存储有哪些方式呢?

🥰数据的存储可以有很多种方式,可以是没有规律的,但是由于存进去之后用的时候还要拿出来,没有规律的存储就很麻烦,所以最后只保留了前两种存储方式,分别为:大端字节序存储和小端字节序存储
📀大端字节序存储:把一个数据的低位字节的数据,存放在高地址处,把高位字节的数据,存放在低地址处
📀大端字节序存储:把一个数据的低位字节的数据,存放在低地址处,把高位字节的数据,存放在高地址处

通过调试可以看到,当前机器上数据的存储方式是以小端字节序存储
为什么会有大小端模式之分呢?这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8 bit。 但是在C语言中除了8 bit的char之外,还有16 bit的short型,32 bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。
例如:一个16bit 的short 型x,在内存中的地址为 0x0010,x的值为 0x1122,那么0x11 为高字节,0x22为低字节。对于大端模式,就将 0x11 放在低地址中,即0x0010中,ox22放在高地址中,即0x0011 中。小端模式,网好相反。我们常用的x86结构是小端模式,而 KETL C51则为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。
👇来看一道笔试题👇
请简述大端字节序和小端字节序的概念,设计一个小程序来判断当前机器的字节序

看代码👇
//如果大端返回0
//如果小端返回1
int check_sys()
{int a = 1;char* p = (char*)&a; //因为要拿第一个字节,所以要强制类型转换if (*p == 1)return 1;elsereturn 0;
}
int main()
{if (check_sys() == 1)printf("小端\n");elseprintf("大端\n");return 0;
}
还可以简化一下👇
int check_sys()
{int a = 1;return *(char*)&a;
}
int main()
{if (check_sys() == 1)printf("小端\n");elseprintf("大端\n");return 0;
}
总结🥰
以上就是 数据在内存中的存储上篇 内容啦🥳🥳🥳🥳
本文章旨在【C语言知识篇】专栏,感兴趣的烙铁可以订阅本专栏哦🥳🥳🥳
欲知后事如何,请听下篇分解喽💕💕💕
小的会继续学习,继续努力带来更好的作品😊😊😊
创作写文不易,还多请各位大佬uu们多多支持哦🥰🥰🥰
