DataWhale 机器学习夏令营第三期
DataWhale 机器学习夏令营第二期
- 学习记录一 (2023.08.18)
- 1.赛题理解
- 2.缺失值分析
- 3. 简单特征提取
- 4. 数据可视化
- 离散变量
- 离散变量分布分析
DataWhale 机器学习夏令营第三期
——用户新增预测挑战赛
学习记录一 (2023.08.18)
已跑通baseline,换为lightgbm基线,不加任何特征线上得分0.52214;
添加baseline特征,线上得分0.78176;
暴力衍生特征并微调模型参数,线上得分0.86068
1.赛题理解
赛题数据由约62万条训练集、20万条测试集数据组成,共包含13个字段。
- 其中uuid为样本唯一标识,
- eid为访问行为ID,
- udmap为行为属性,其中的key1到key9表示不同的行为属性,如项目名、项目id等相关字段,
- common_ts为应用访问记录发生时间(毫秒时间戳),
- 其余字段x1至x8为用户相关的属性,为匿名处理字段。
- target字段为预测目标,即是否为新增用户。
2.缺失值分析
print('-----Missing Values-----')
print(train_data.isnull().sum())print('\n')
print('-----Classes-------')
display(pd.merge(train_data.target.value_counts().rename('count'),train_data.target.value_counts(True).rename('%').mul(100),left_index=True,right_index=True
))
分析:数据无缺失值, 533155(85.943394%)负样本, 87201(14.056606%)正样本
数据分布不均的处理:
- 阈值迁移
- 设置样本权重
weight_0 = 1.0 # 多数类样本的权重
weight_1 = 8.0 # 少数类样本的权重
dtrain = lgb.Dataset(X_train, label=y_train, weight=y_train.map({0: weight_0, 1: weight_1}))
dval = lgb.Dataset(X_val, label=y_val, weight=y_val.map({0: weight_0, 1: weight_1}))
3. 简单特征提取
行为相关特征:eid和udmap相关特征提取
- udmap中value特征提取:baseline中已经给出
- udmap中key特征提取
import jsondef extract_keys_as_string(row):if row == 'unknown':return Noneelse:parsed_data = json.loads(row)keys = list(parsed_data.keys())keys_string = '_'.join(keys) # 用下划线连接 keyreturn keys_stringtrain_df['udmap_key'] = train_df['udmap'].apply(extract_keys_as_string)
train_df['udmap_key'].value_counts()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PkbowYDJ-1692365546794)(C:\Users\ZYM\AppData\Roaming\Typora\typora-user-images\image-20230818195454065.png)]](https://img-blog.csdnimg.cn/37cfbfe15fa94d4aacc424487216af78.png)
观察eid和udmap_key 对应关系
train_df.groupby('eid')['udmap_key'].unique()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9zqnrzDe-1692365546795)(C:\Users\ZYM\AppData\Roaming\Typora\typora-user-images\image-20230818195553955.png)]](https://img-blog.csdnimg.cn/4e9d85d5b31b449f88a73604b1aa5d44.png)
分析:可以看到eid和key是强相关甚至是一一对应的,后续可以围绕着eid、key、value构造行为相关特征。
4. 数据可视化
离散变量
查看各个特征情况:
for i in train_data.columns:if train_data[i].nunique() < 10:print(f'{i}, {train_data[i].nunique()}: {train_data[i].unique()}')else:print(f'{i}, {train_data[i].nunique()}: {train_data[i].unique()[:10]}')
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sPwmt4rl-1692365546795)(C:\Users\ZYM\AppData\Roaming\Typora\typora-user-images\image-20230818200557544.png)]](https://img-blog.csdnimg.cn/744e4773a01448e3b4c6f8212d3561db.png)
分析:
-
[‘eid’, ‘x3’, ‘x4’, ‘x5’] 为取值较多的类别特征想
-
[‘x1’, ‘x2’, ‘x6’,'x7, ‘x8’]为取值较少的类别特征, x8 基本确定为性别特征
离散变量分布分析
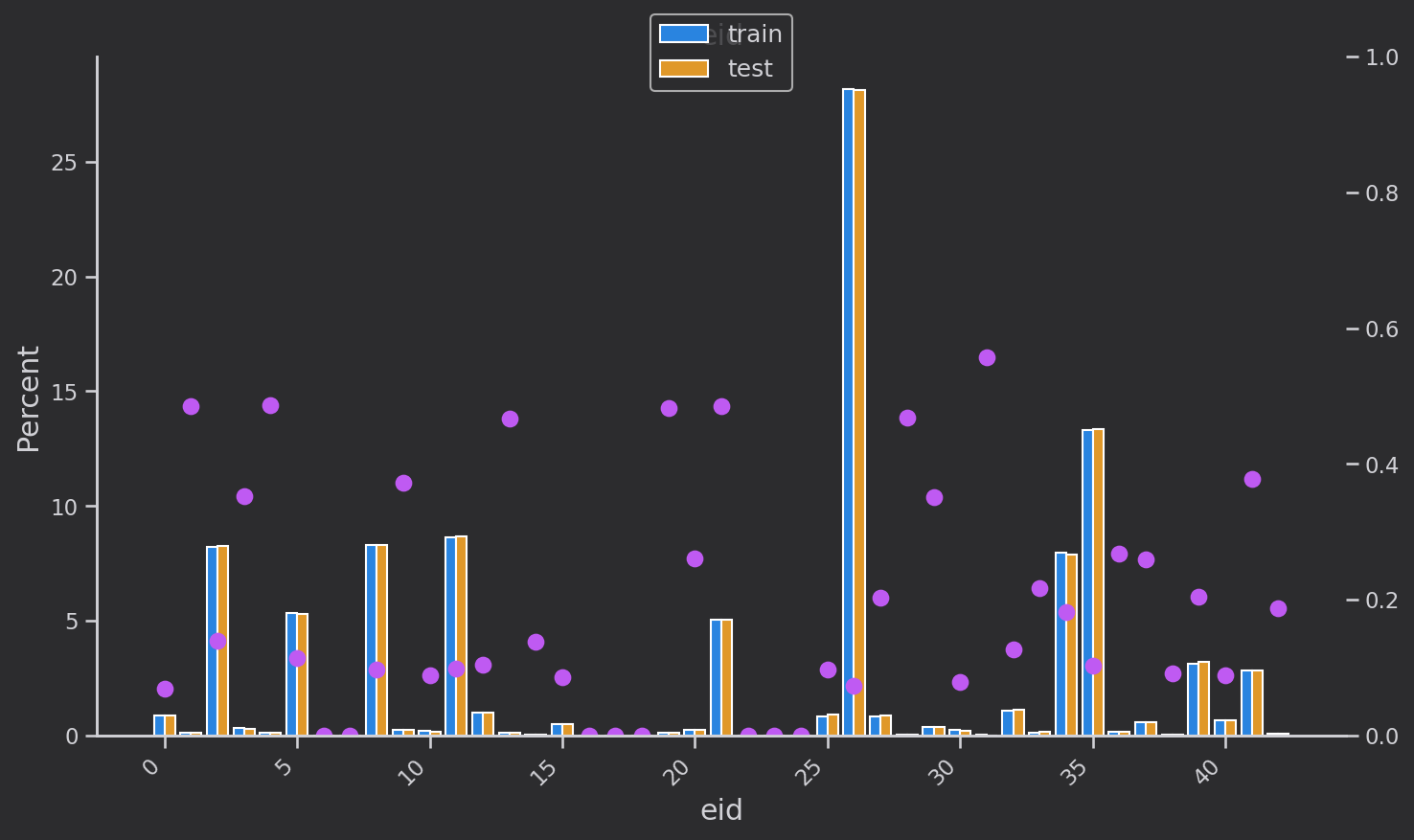
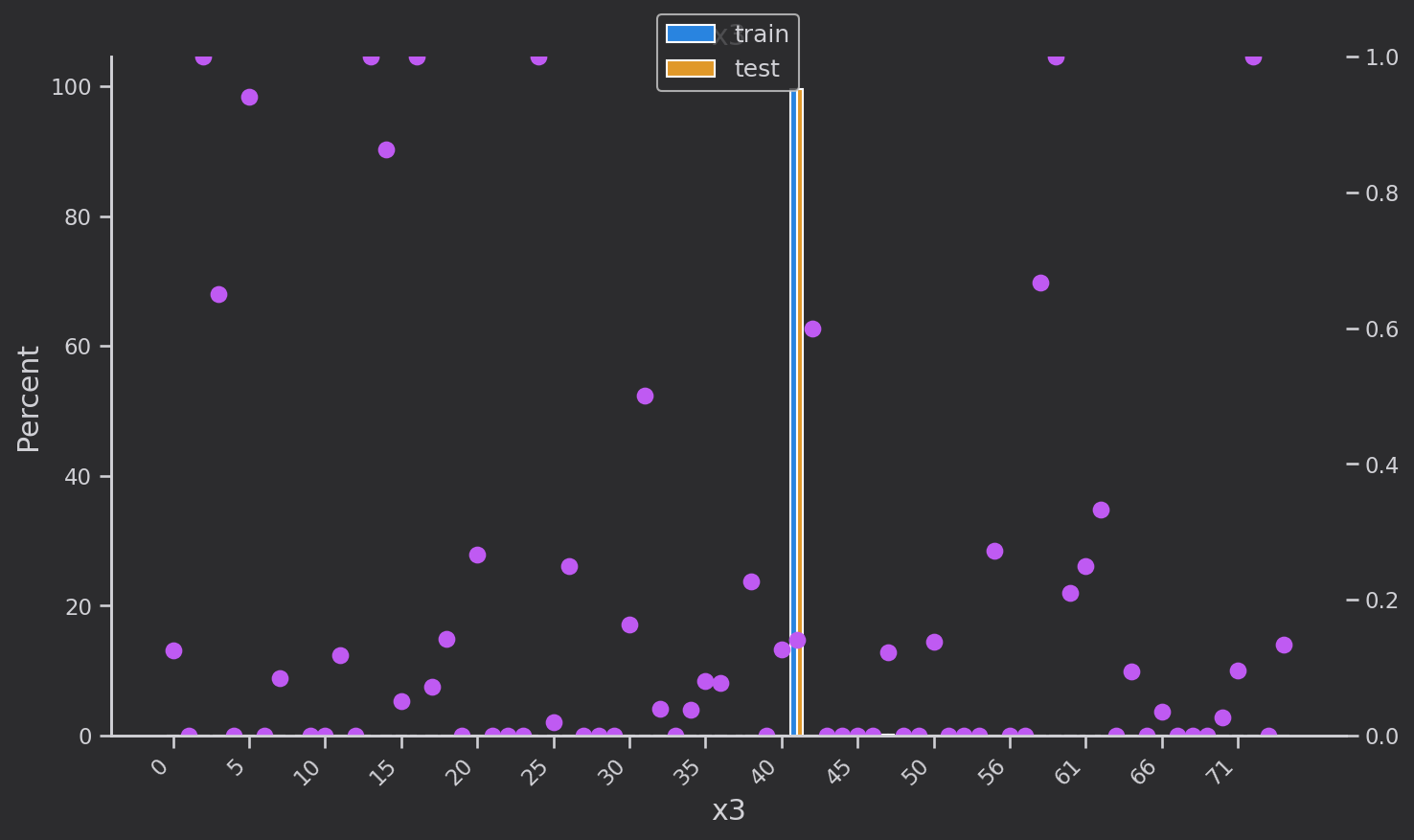
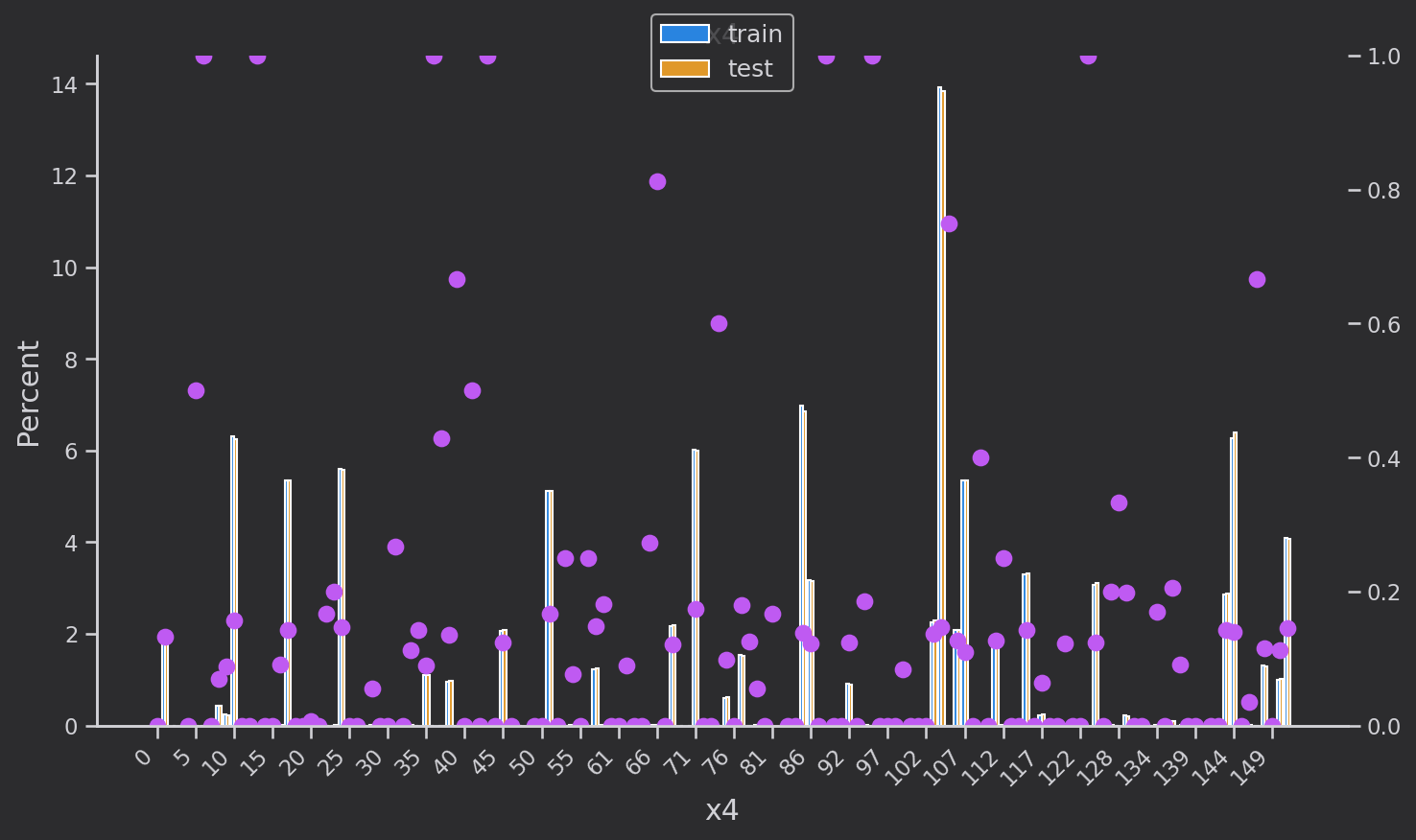
研究离散变量['eid', 'x3', 'x4', 'x5‘,'x1', 'x2', 'x6','x7', 'x8'']的分布,蓝色是训练集,黄色是验证集,分布基本一致
粉色的点是训练集下每个类别每种取值的target的均值,也就是target=1的占比
绘制代码:
def plot_cate_large(col):data_to_plot = (all_df.groupby('set')[col].value_counts(True)*100)fig, ax = plt.subplots(figsize=(10, 6))sns.barplot(data=data_to_plot.rename('Percent').reset_index(),hue='set', x=col, y='Percent', ax=ax,orient='v',hue_order=['train', 'test'])x_ticklabels = [x.get_text() for x in ax.get_xticklabels()]# Secondary axis to show mean of targetax2 = ax.twinx()scatter_data = all_df.groupby(col)['target'].mean()scatter_data.index = scatter_data.index.astype(str)ax2.plot(x_ticklabels,scatter_data.loc[x_ticklabels],linestyle='', marker='.', color=colors[4],markersize=15)ax2.set_ylim([0, 1])# Set x-axis tick labels every 5th valuex_ticks_indices = range(0, len(x_ticklabels), 5)ax.set_xticks(x_ticks_indices)ax.set_xticklabels(x_ticklabels[::5], rotation=45, ha='right')# titlesax.set_title(f'{col}')ax.set_ylabel('Percent')ax.set_xlabel(col)# remove axes to show only one at the endhandles = []labels = []if ax.get_legend() is not None:handles += ax.get_legend().legendHandleslabels += [x.get_text() for x in ax.get_legend().get_texts()]else:handles += ax.get_legend_handles_labels()[0]labels += ax.get_legend_handles_labels()[1]ax.legend().remove()plt.legend(handles, labels, loc='upper center', bbox_to_anchor=(0.5, 1.08), fontsize=12)plt.tight_layout()plt.show()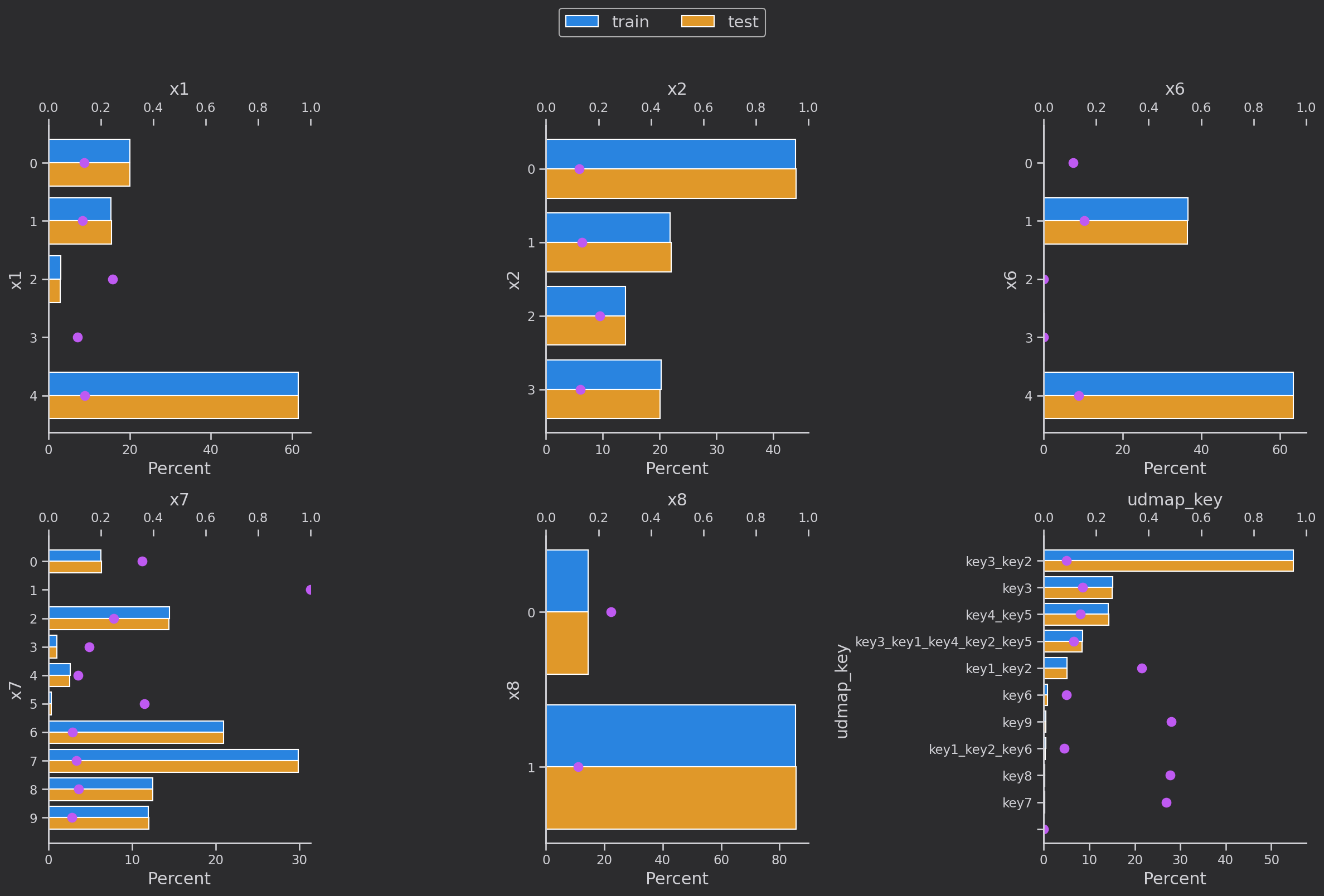
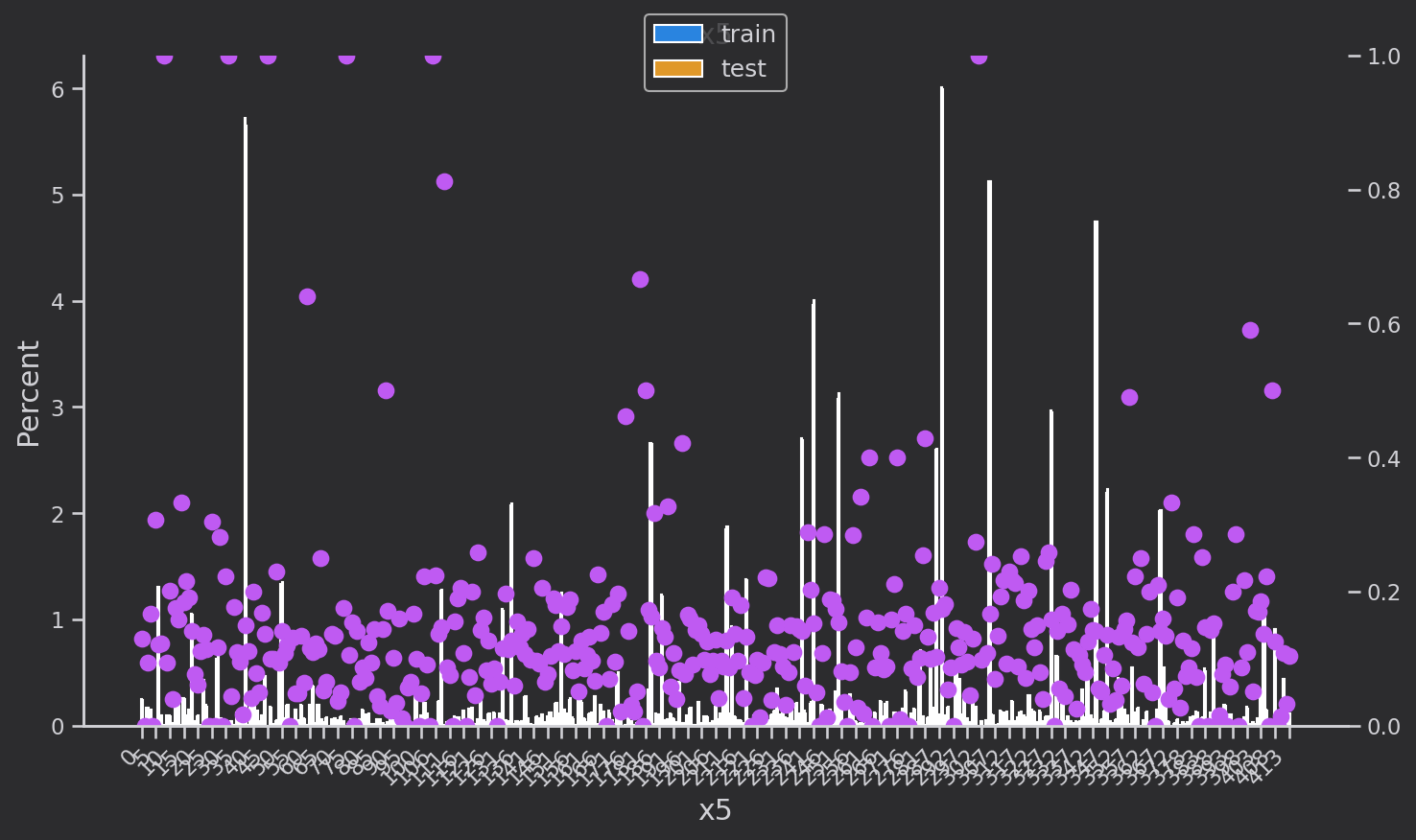
下一步,分析数据,构建特征。