YOLOv5、YOLOv8改进:SOCA注意力机制
目录
简介
2.YOLOv5使用SOCA注意力机制
2.1增加以下SOCA.yaml文件
2.2common.py配置
2.3yolo.py配置
简介
注意力机制(Attention Mechanism)源于对人类视觉的研究。在认知科学中,由于信息处理的瓶颈,人类会选择性地关注所有信息的一部分,同时忽略其他可见的信息。为了合理利用有限的视觉信息处理资源,人类需要选择视觉区域中的特定部分,然后集中关注它。例如,人们在阅读时,通常只有少量要被读取的词会被关注和处理。综上,注意力机制主要有两个方面:决定需要关注输入的哪部分;分配有限的信息处理资源给重要的部分。这几年有关attention的论文与日俱增,下图就显示了在包括CVPR、ICCV、ECCV、NeurIPS、ICML和ICLR在内的顶级会议中,与attention相关的论文数量的增加量。下面我将会分享Yolov5 v6.1如何添加注意力机制;
今天介绍一篇CPVR19的Oral文章,用二阶注意力网络来进行单图像超分辨率。作者来自清华深研院,鹏城实验室,香港理工大学以及阿里巴巴达摩院。
文章地址
github code
文章的出发点:现存的基于CNN的模型仍然面临一些限制:
- 大多数基于CNN的SR方法没有充分利用原始LR图像的信息,导致相当低的性能
- 大多数CNN-based models主要专注于设计更深或是更宽的网络,以学习更有判别力的高层特征,却很少发掘层间特征的内在相关性,从而妨碍了CNN的表达能
文章的大体思路:提出了一个深的二阶注意力网络SAN,以获得更好的特征表达和特征相关性学习。特别地,提出了一个二阶通道注意力机制SOCA来进行相关性学习。同时,提出了一个non-locally增强残差组NLRG来捕获长距离空间内容信息。
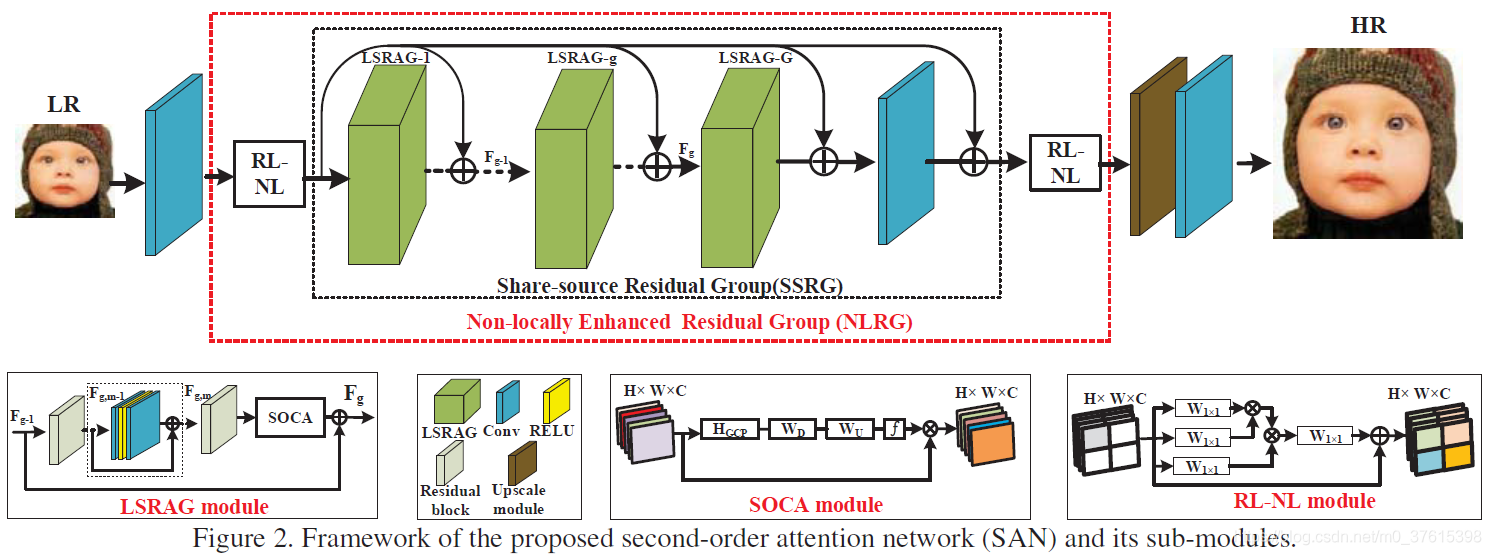
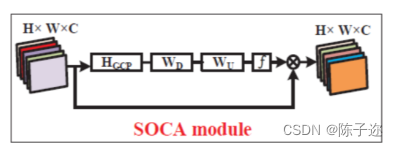
在LSRAG的末端,有一个SOCA模块,即二阶通道注意力机制。
相比于SENet里面的通道attention使用的是一阶统计信息(通过全局平均池化),本SOCA探索了二阶特征统计的attention
2.YOLOv5使用SOCA注意力机制
2.1增加以下SOCA.yaml文件
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[-1, 1, SOCA, [1024]],[[17, 20, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]2.2common.py配置
./models/common.py文件增加以下模块
import numpy as np
import torch
from torch import nn
from torch.nn import initfrom torch.autograd import Functionclass Covpool(Function):@staticmethoddef forward(ctx, input):x = inputbatchSize = x.data.shape[0]dim = x.data.shape[1]h = x.data.shape[2]w = x.data.shape[3]M = h*wx = x.reshape(batchSize,dim,M)I_hat = (-1./M/M)*torch.ones(M,M,device = x.device) + (1./M)*torch.eye(M,M,device = x.device)I_hat = I_hat.view(1,M,M).repeat(batchSize,1,1).type(x.dtype)y = x.bmm(I_hat).bmm(x.transpose(1,2))ctx.save_for_backward(input,I_hat)return y@staticmethoddef backward(ctx, grad_output):input,I_hat = ctx.saved_tensorsx = inputbatchSize = x.data.shape[0]dim = x.data.shape[1]h = x.data.shape[2]w = x.data.shape[3]M = h*wx = x.reshape(batchSize,dim,M)grad_input = grad_output + grad_output.transpose(1,2)grad_input = grad_input.bmm(x).bmm(I_hat)grad_input = grad_input.reshape(batchSize,dim,h,w)return grad_inputclass Sqrtm(Function):@staticmethoddef forward(ctx, input, iterN):x = inputbatchSize = x.data.shape[0]dim = x.data.shape[1]dtype = x.dtypeI3 = 3.0*torch.eye(dim,dim,device = x.device).view(1, dim, dim).repeat(batchSize,1,1).type(dtype)normA = (1.0/3.0)*x.mul(I3).sum(dim=1).sum(dim=1)A = x.div(normA.view(batchSize,1,1).expand_as(x))Y = torch.zeros(batchSize, iterN, dim, dim, requires_grad = False, device = x.device)Z = torch.eye(dim,dim,device = x.device).view(1,dim,dim).repeat(batchSize,iterN,1,1)if iterN < 2:ZY = 0.5*(I3 - A)Y[:,0,:,:] = A.bmm(ZY)else:ZY = 0.5*(I3 - A)Y[:,0,:,:] = A.bmm(ZY)Z[:,0,:,:] = ZYfor i in range(1, iterN-1):ZY = 0.5*(I3 - Z[:,i-1,:,:].bmm(Y[:,i-1,:,:]))Y[:,i,:,:] = Y[:,i-1,:,:].bmm(ZY)Z[:,i,:,:] = ZY.bmm(Z[:,i-1,:,:])ZY = 0.5*Y[:,iterN-2,:,:].bmm(I3 - Z[:,iterN-2,:,:].bmm(Y[:,iterN-2,:,:]))y = ZY*torch.sqrt(normA).view(batchSize, 1, 1).expand_as(x)ctx.save_for_backward(input, A, ZY, normA, Y, Z)ctx.iterN = iterNreturn y@staticmethoddef backward(ctx, grad_output):input, A, ZY, normA, Y, Z = ctx.saved_tensorsiterN = ctx.iterNx = inputbatchSize = x.data.shape[0]dim = x.data.shape[1]dtype = x.dtypeder_postCom = grad_output*torch.sqrt(normA).view(batchSize, 1, 1).expand_as(x)der_postComAux = (grad_output*ZY).sum(dim=1).sum(dim=1).div(2*torch.sqrt(normA))I3 = 3.0*torch.eye(dim,dim,device = x.device).view(1, dim, dim).repeat(batchSize,1,1).type(dtype)if iterN < 2:der_NSiter = 0.5*(der_postCom.bmm(I3 - A) - A.bmm(der_sacleTrace))else:dldY = 0.5*(der_postCom.bmm(I3 - Y[:,iterN-2,:,:].bmm(Z[:,iterN-2,:,:])) -Z[:,iterN-2,:,:].bmm(Y[:,iterN-2,:,:]).bmm(der_postCom))dldZ = -0.5*Y[:,iterN-2,:,:].bmm(der_postCom).bmm(Y[:,iterN-2,:,:])for i in range(iterN-3, -1, -1):YZ = I3 - Y[:,i,:,:].bmm(Z[:,i,:,:])ZY = Z[:,i,:,:].bmm(Y[:,i,:,:])dldY_ = 0.5*(dldY.bmm(YZ) - Z[:,i,:,:].bmm(dldZ).bmm(Z[:,i,:,:]) - ZY.bmm(dldY))dldZ_ = 0.5*(YZ.bmm(dldZ) - Y[:,i,:,:].bmm(dldY).bmm(Y[:,i,:,:]) -dldZ.bmm(ZY))dldY = dldY_dldZ = dldZ_der_NSiter = 0.5*(dldY.bmm(I3 - A) - dldZ - A.bmm(dldY))grad_input = der_NSiter.div(normA.view(batchSize,1,1).expand_as(x))grad_aux = der_NSiter.mul(x).sum(dim=1).sum(dim=1)for i in range(batchSize):grad_input[i,:,:] += (der_postComAux[i] \- grad_aux[i] / (normA[i] * normA[i])) \*torch.ones(dim,device = x.device).diag()return grad_input, Nonedef CovpoolLayer(var):return Covpool.apply(var)def SqrtmLayer(var, iterN):return Sqrtm.apply(var, iterN)class SOCA(nn.Module):# second-order Channel attentiondef __init__(self, channel, reduction=8):super(SOCA, self).__init__()self.max_pool = nn.MaxPool2d(kernel_size=2)self.conv_du = nn.Sequential(nn.Conv2d(channel, channel // reduction, 1, padding=0, bias=True),nn.ReLU(inplace=True),nn.Conv2d(channel // reduction, channel, 1, padding=0, bias=True),nn.Sigmoid())def forward(self, x):batch_size, C, h, w = x.shape # x: NxCxHxWN = int(h * w)min_h = min(h, w)h1 = 1000w1 = 1000if h < h1 and w < w1:x_sub = xelif h < h1 and w > w1:W = (w - w1) // 2x_sub = x[:, :, :, W:(W + w1)]elif w < w1 and h > h1:H = (h - h1) // 2x_sub = x[:, :, H:H + h1, :]else:H = (h - h1) // 2W = (w - w1) // 2x_sub = x[:, :, H:(H + h1), W:(W + w1)]cov_mat = CovpoolLayer(x_sub) # Global Covariance pooling layercov_mat_sqrt = SqrtmLayer(cov_mat,5) # Matrix square root layer( including pre-norm,Newton-Schulz iter. and post-com. with 5 iteration)cov_mat_sum = torch.mean(cov_mat_sqrt,1)cov_mat_sum = cov_mat_sum.view(batch_size,C,1,1)y_cov = self.conv_du(cov_mat_sum)return y_cov*x2.3yolo.py配置
在 models/yolo.py文件夹下
- 定位到parse_model函数中
- 对应位置 下方只需要新增以下代码
elif m is SOCA:c1, c2 = ch[f], args[0]if c2 != no:c2 = make_divisible(c2 * gw, 8)args = [c1, *args[1:]]
修改完成
如有遇到不清楚的地方欢迎评论区留言