数据结构——B-树、B+树、B*树
一、B-树
1. B-树概念
B树是一种适合外查找的、平衡的多叉树。一棵m阶(m>2)的B树,是一棵平衡的M路平衡搜索树,它可以是空树或满足以下性质:
(1)根节点至少有两个孩子。
(2)每个分支节点都包含k-1个关键字和k个孩子,其中ceil(m/2)<= k <= m。(ceil表示向上取整)
(3)每个叶子节点都包含k-1个关键字,其中ceil(m/2)<= k <= m。
(4)所有叶子节点都在同一层。
(5)每个节点中的关键字从小到大排列,节点中k-1个元素正好是k个孩子包含的元素的值域划分。
(6)每个节点的结构为:(n, A0, K1, A1, K2, A2……, Kn, An),其中Ki(1<=i<=n)为关键字,且ki<ki + 1(1<=i<=n)。Ai(0<=i<=n)为指向子树根节点的指针,且Ai所指子树所有节点中的关键字均小于Ki+1。n为节点中关键字的个数,满足ceil(m/2)-1 <=n <= m-1。
2. B树的插入
采用m为3的一棵三叉B树的插入过程进行演示。根据B树性质可知,m为3,则每个节点最多有三个孩子(m-1个),每个节点包含k-1个关键字,2<=k<=3。注意:插入只能插入到叶子节点。
(1)首先插入两个值20,30

(2)插入第三个值25,由于每个节点最多有2个关键字,所以此时会进行分裂来维持B树平衡。
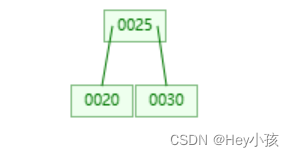
2.1 B树分裂规则
创建一个兄弟节点,拷贝当前节点内右半区间的数据到兄弟节点中,保留当前节点中左半区间的数据,将该节点内的中位数提到父节点中(若没有父节点,则创建新的父节点)。
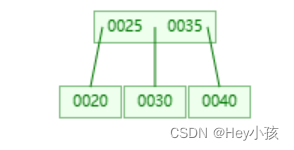
(3)插入35

(4) 插入40
此时根节点的右侧孩子内数据超过2个,则按照B树分裂规则分裂后如下:
(5)插入33
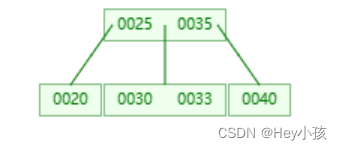
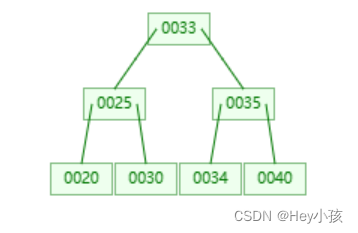
(6)插入34
此时根节点的中间孩子内数据超过2两个,进行分裂,当提取33到父节点后,根节点内数据也超过了2个,则根节点也会进行分裂,此时没有父节点,则会创建新的父节点,结构如下:
三、B+树
1. B+树概念
B+树是B树的变形,它是在B树基础上进行优化的多路平衡搜索树,B+树的规则和B树基本类似,但在其基础上进行了以下优化:
(1)分支节点的子树指针与关键字个数相同;
(2)分支节点的子树指针p[i]指向关键字值大小在[k[i], k[i+1]]之间;
(3)所有叶子节点增加一个链接指针链接在一起;
(4)所有关键字及其映射数据都在叶子节点出现。
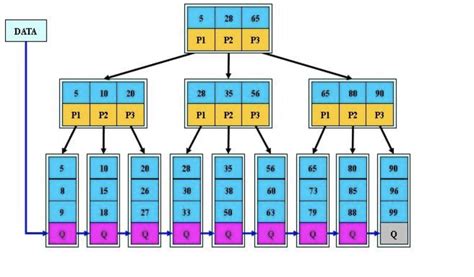
优点:
(1)简化了B树孩子币关键字多一个的规则,由多一个变成相等。
(2)所有值都在叶子节点中,且叶子节点通过指针链接起来,方便遍历。
2. B+树的插入
B+树的插入过程与B树基本类似,区别在于:
(1)第一次插入两层节点,一层做分支,一层做根;
(2)B+树在分裂时,是将左半部分的数据保留,右半部分的数据放入新建兄弟节点中,并将新建节点中的最小值更新到父节点中。
三、B*树
1. B*树概念
B*树又是B+树的变形,做了以下改动:
(1)在B+树的非根和非叶子节点再增加指向兄弟节点的指针。
(2)节点在分裂时,保证每个节点中值的数量至少为2/3 * M,最多为M个,也就是从1/2提高到了2/3,提高空间利用率。
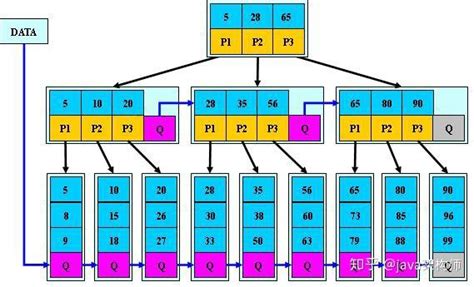
2. B*树的插入
B*树的插入与B+树基本类似,区别主要在于分裂规则,B*树的分裂规则:
如果它的下一个兄弟节点未满,则将一部分数据移到兄弟节点中,再在原节点中插入关键字,最后修改父节点中兄弟节点的关键字(因为兄弟节点的关键字范围发生了变化);
如果兄弟节点也满了,则在原节点与兄弟节点之间添加新节点,并各复制1/3的数据到新节点中,最后在父节点中添加新节点的指针。
四、B树系列的优缺点
1. 优点
(1)高效的查找操作:B树系列的数据结构通过将数据分布在多层节点上,使用索引快速导航到目标元素所在的叶子节点,从而实现了高效的查找操作。其时间复杂度通常为O()
(2)适应大规模数据集:B树系列的数据结构能够充分利用磁盘块的大小,减少磁盘I/O操作的次数,提高存储和访问效率。它们被广泛应用于数据库索引、文件系统等需要处理大规模数据集的场景。
(3)自平衡特性:B树系列的数据结构通过节点的分裂和合并来自动保持树的平衡,保证了各个节点的高度相对较小,从而维持了高效的操作性能。
(4)支持范围查询:由于B树系列的数据结构中数据是按照键的大小顺序进行排序,因此可以很方便地进行范围查询操作。
2. 缺点
(1)空间利用率低,消耗高。
(2)插入删除数据、分裂合并节点,都必然存在数据挪动。
(3)虽然B树系列的高度更低,但是在内存中和哈希、平衡搜索树的查找效率处于同一量级。