PyTorch学习笔记(十三)——现有网络模型的使用及修改

以分类模型的VGG为例



vgg16_false = torchvision.models.vgg16(weights=False)
vgg16_true = torchvision.models.vgg16(weights=True)- 设置为 False 的情况,相当于网络模型中的参数都是初始化的、默认的
- 设置为 True 时,网络模型中的参数在数据集上是训练好的,能达到比较好的效果
print(vgg16_true)VGG((features): Sequential(
# 输入图片先经过卷积,输入是3通道的、输出是64通道的,卷积核大小是3×3的(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# 非线性(1): ReLU(inplace=True)
# 卷积、非线性、池化...(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(3): ReLU(inplace=True)(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(6): ReLU(inplace=True)(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(8): ReLU(inplace=True)(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(11): ReLU(inplace=True)(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(13): ReLU(inplace=True)(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(15): ReLU(inplace=True)(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(18): ReLU(inplace=True)(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(20): ReLU(inplace=True)(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(22): ReLU(inplace=True)(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(25): ReLU(inplace=True)(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(27): ReLU(inplace=True)(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(29): ReLU(inplace=True)(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))(classifier): Sequential((0): Linear(in_features=25088, out_features=4096, bias=True)(1): ReLU(inplace=True)(2): Dropout(p=0.5, inplace=False)(3): Linear(in_features=4096, out_features=4096, bias=True)(4): ReLU(inplace=True)(5): Dropout(p=0.5, inplace=False)
# 最后线性层输出为1000(vgg16也是一个分类模型,能分出1000个类别)(6): Linear(in_features=4096, out_features=1000, bias=True))
)CIFAR10 把数据分成了10类,而 vgg16 模型把数据分成了 1000 类,如何应用这个网络模型呢?
- 方法1:把最后线性层的 out_features 从1000改为10
- 方法2:在最后的线性层下面再加一层,in_features为1000,out_features为10
利用现有网络去改动它的结构,避免写 vgg16。很多框架会把 vgg16 当做前置的网络结构,提取一些特殊的特征,再在后面加一些网络结构,实现功能。
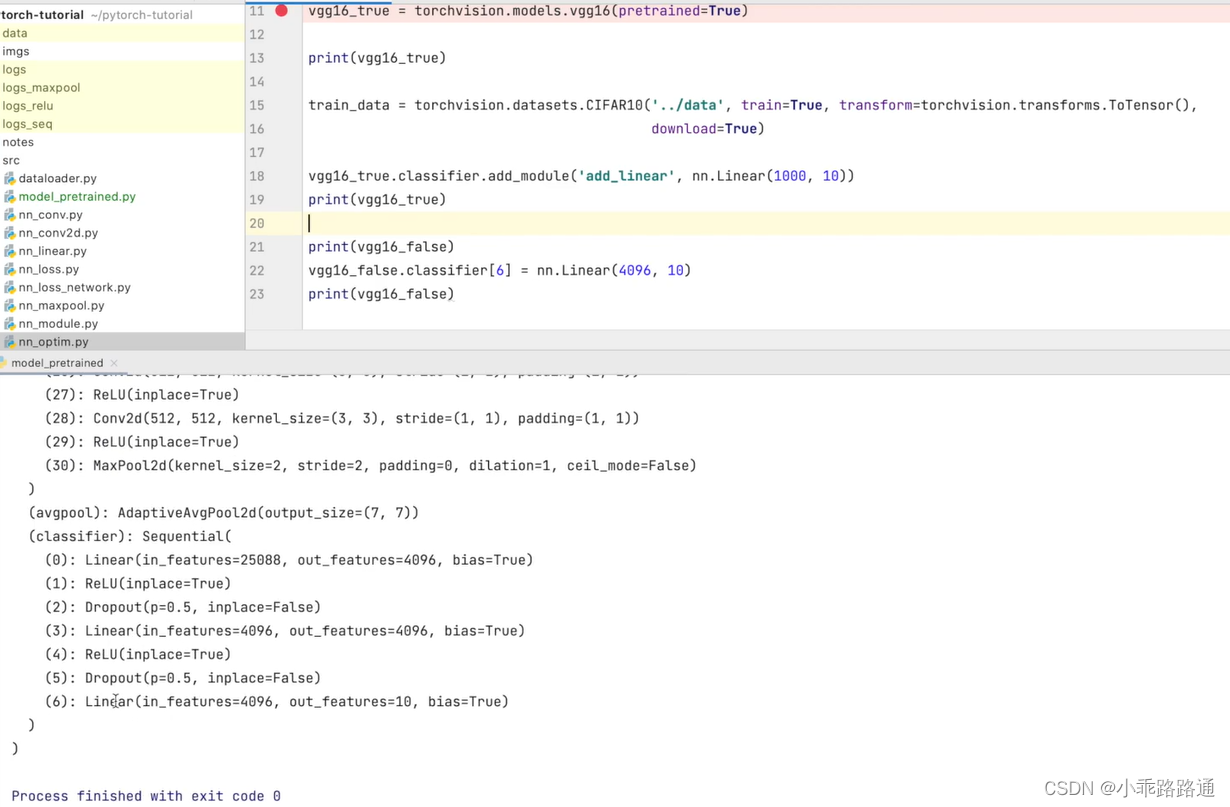
方法2:添加
vgg16_true.classifier.add_module("add_linear",nn.Linear(1000,10))
print(vgg16_true)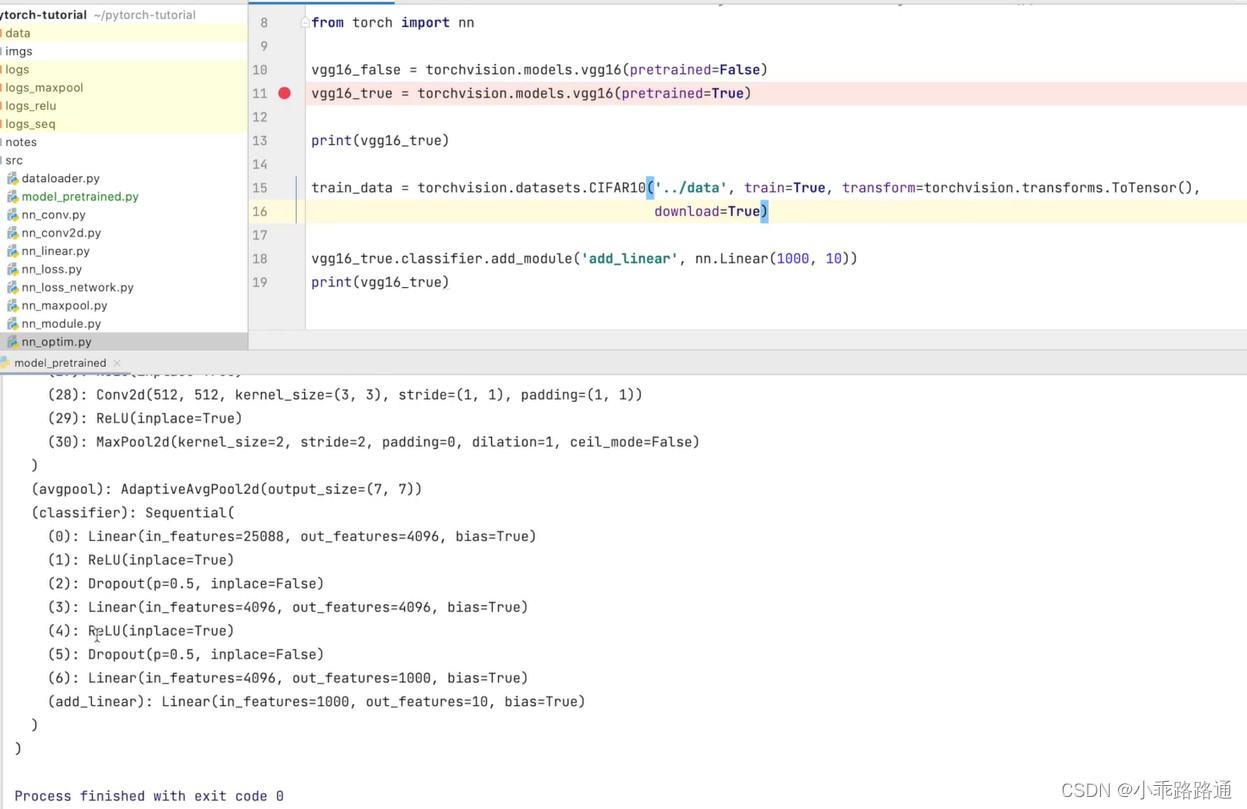
方法1:修改
vgg16_false.classifier[6] = nn.Linear(4096,10)
print(vgg16_false)