Golang服务的请求调度
文章目录
- 1. 写在前面
- 2. SheddingHandler的实现原理
- 3. 相关方案的对比
- 4. 小结
1. 写在前面
最近在看相关的Go服务的请求调度的时候,发现在gin中默认提供的中间件中,不含有请求调度相关的逻辑中间件,去github查看了一些服务框架,发现在go-zero中,有一个SheddingHandler的中间件来帮助服务请求进行调度,防止在流量徒增的时候,服务出现滚雪球进一步恶化,导致最后服务不可用的现象出现。
SheddingHandler中间件存在的意义就是尽量保证服务可用的情况下尽可能多的处理请求,而在流量突增的时候,丢弃部分请求以确保服务可用,防止服务因为流量过大而崩溃。
2. SheddingHandler的实现原理
SheddingHandler简单来说就是维持了一套指标,在每个请求进入系统的时候,利用指标进行计算,判断当前的请求是否允许被进入系统,如果允许则请求通过中间件继续向下被服务处理,如果不被允许则在中间件层面就丢弃掉(正是这个丢弃,保证了在流量突增时服务的稳定)。
具体看源码:
// SheddingHandler returns a middleware that does load shedding.
func SheddingHandler(shedder load.Shedder, metrics *stat.Metrics) func(http.Handler) http.Handler {if shedder == nil {return func(next http.Handler) http.Handler {return next}}ensureSheddingStat() // 负责每分钟打印shedding相关的数据return func(next http.Handler) http.Handler {return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {sheddingStat.IncrementTotal()promise, err := shedder.Allow() // 判断是否允许此请求进入下一步if err != nil {metrics.AddDrop() // drop掉请求,在中间件层面就拒绝了请求sheddingStat.IncrementDrop()logx.Errorf("[http] dropped, %s - %s - %s",r.RequestURI, httpx.GetRemoteAddr(r), r.UserAgent())w.WriteHeader(http.StatusServiceUnavailable)// 返回503,提示服务不可用return}cw := response.NewWithCodeResponseWriter(w)defer func() {if cw.Code == http.StatusServiceUnavailable {promise.Fail() // 相关指标记录} else {sheddingStat.IncrementPass()promise.Pass() // 相关指标记录}}()next.ServeHTTP(cw, r)})}
}
可以看到请求是否可以继续向下,取决于Allow()这个方法,这个方法的实现如下:
// Allow implements Shedder.Allow.
func (as *adaptiveShedder) Allow() (Promise, error) {if as.shouldDrop() {// 判断是否应该丢弃as.droppedRecently.Set(true)return nil, ErrServiceOverloaded// 丢弃}as.addFlying(1) // 通过校验return &promise{start: timex.Now(),shedder: as,}, nil
}
继续看shouldDrop()方法:
func (as *adaptiveShedder) shouldDrop() bool {if as.systemOverloaded() || as.stillHot() {// 如果任一满足,这个请求都会被过载if as.highThru() {flying := atomic.LoadInt64(&as.flying)as.avgFlyingLock.Lock()avgFlying := as.avgFlyingas.avgFlyingLock.Unlock()msg := fmt.Sprintf("dropreq, cpu: %d, maxPass: %d, minRt: %.2f, hot: %t, flying: %d, avgFlying: %.2f",stat.CpuUsage(), as.maxPass(), as.minRt(), as.stillHot(), flying, avgFlying)logx.Error(msg)stat.Report(msg)return true}}return false
}func (as *adaptiveShedder) systemOverloaded() bool {if !systemOverloadChecker(as.cpuThreshold) { // 校验CPU的负载是否超出设定值return false}as.overloadTime.Set(timex.Now())// 超出设定值,记录当前的时间(这主要是为了后续流量减小,系统的恢复用)return true
}func (as *adaptiveShedder) stillHot() bool {if !as.droppedRecently.True() {// 如果这个请求之前有请求被drop这里值为true,反之为falsereturn false// 之前的请求没有被drop表示系统可能没有遇到过载的问题,返回false}overloadTime := as.overloadTime.Load()// 如果之前有请求被drop,表示存在过载if overloadTime == 0 {// 看看是否有记录过载的时间return false}if timex.Since(overloadTime) < coolOffDuration {// 如果小于冷却时间,表示系统依然是过载状态return true}as.droppedRecently.Set(false)// 表示CPU过载,上一次过载过了冷却器,这个请求可以继续执行,设置为falsereturn false
}
可以看到请求被drop的前置条件有两个:
- 系统的CPU负载超出了设定值,目前go-zero设置的默认值为90%,即系统CPU负载达到90%后,就意味着系统过载了,只要是过载,请求会被直接拒绝;否则判断第二个条件
- 因为过载可能会随着流量减小而恢复,或者丢弃的请求太多,系统CPU会慢慢的恢复正常水平(90%以下),所以需要看一下过载时间,如果超过了冷却时间,而第一个条件又表示系统CPU负载正常,此时我们会认定系统恢复了,这个请求可以处理。
满足上述任一条件,此请求就会进入最后的highThru()方法判断环节,如果满足了,此请求就会被丢弃。
从上面我们可以得到,我们判断服务是否过载,是依靠CPU的使用率去判断的,那么我们如何动态的计算CPU的使用率呢?
在go-zero里面,采用的是直接获取linux机器上的cpu的相关文件,然后通过代码逻辑将相关的文件进行解析并计算出CPU使用率。可以参考:[cgroup_linux.go]

这里为了效率问题,并不是实时去计算的,而是在启动的时候,启动了一个goroutine每250ms进行以此CPU使用率数据的刷新。
const (// 250ms and 0.95 as beta will count the average cpu load for past 5 secondscpuRefreshInterval = time.Millisecond * 250allRefreshInterval = time.Minute// moving average beta hyperparameterbeta = 0.95
)var cpuUsage int64func init() {go func() {cpuTicker := time.NewTicker(cpuRefreshInterval)defer cpuTicker.Stop()allTicker := time.NewTicker(allRefreshInterval)defer allTicker.Stop()for {select {case <-cpuTicker.C:threading.RunSafe(func() {curUsage := internal.RefreshCpu() // 刷新CPU使用率数据prevUsage := atomic.LoadInt64(&cpuUsage)// cpu = cpuᵗ⁻¹ * beta + cpuᵗ * (1 - beta)usage := int64(float64(prevUsage)*beta + float64(curUsage)*(1-beta))atomic.StoreInt64(&cpuUsage, usage)})case <-allTicker.C:if logEnabled.True() {printUsage()}}}}()
}
最后再来看highThru()方法,这个方法相对来说比较复杂:
func (as *adaptiveShedder) addFlying(delta int64) {flying := atomic.AddInt64(&as.flying, delta)// 请求通过检验进入后会加1,请求被服务处理完后会减1if delta < 0 {as.avgFlyingLock.Lock()// 平均请求数计算为当前平均请求数*0.9 + 当前运行请求数*0.1as.avgFlying = as.avgFlying*flyingBeta + float64(flying)*(1-flyingBeta)as.avgFlyingLock.Unlock()}
}func (as *adaptiveShedder) highThru() bool {as.avgFlyingLock.Lock()avgFlying := as.avgFlying // 运行中的平均请求数as.avgFlyingLock.Unlock()maxFlight := as.maxFlight()// 运行的最大的请求数// 如果运行的平均请求数>最大的请求数且当前运行的请求数>最大的请求数,表示依旧高负载return int64(avgFlying) > maxFlight && atomic.LoadInt64(&as.flying) > maxFlight
}func (as *adaptiveShedder) maxFlight() int64 {// windows = buckets per second// maxQPS = maxPASS * windows// minRT = min average response time in milliseconds// maxQPS * minRT / milliseconds_per_second// 最大的运行数的计算为最大请求数*窗口的长度*最小的处理时间return int64(math.Max(1, float64(as.maxPass()*as.windows)*(as.minRt()/1e3)))
}
上面关于flying的计算,在SheddingHandler中有两个count统计器在统计这通过的总请求数以及请求的平均耗时。默认会在5s的时间内启动50个大小的bucket来循环滚动,即每个bucket统计100ms内的请求数。
这里利用窗口统计请求数大小的判断主要是为了规避在负载的情况下,丢弃了太多的请求导致系统实际运行的请求数减少的太多,所以加了这一层判断,这个可以保证在系统高负载丢弃了大量的请求的情况下,系统尽可能多的处理更多的请求,而不是负载一高就直接丢弃。
func (as *adaptiveShedder) maxPass() int64 {var result float64 = 1as.passCounter.Reduce(func(b *collection.Bucket) {if b.Sum > result {result = b.Sum}})return int64(result)
}func (as *adaptiveShedder) minRt() float64 {result := defaultMinRtas.rtCounter.Reduce(func(b *collection.Bucket) {if b.Count <= 0 {return}avg := math.Round(b.Sum / float64(b.Count))if avg < result {result = avg}})return result
}
3. 相关方案的对比
在调度请求这一块,go-zero的方案确实很棒,结合了CPU使用率和过载冷缺以及请求数大小因素,不仅保证了系统高负载下服务的正常,还确保了系统能够尽可能多的处理请求。
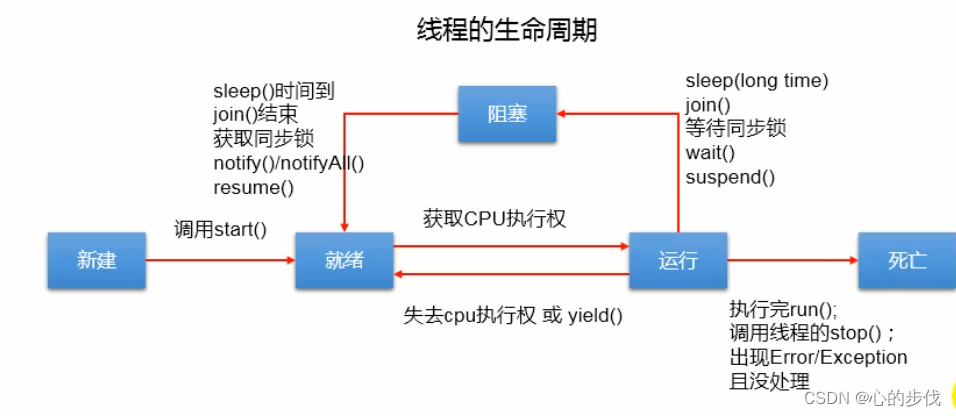
但从我们目前的调度模式以及执行单元的状态角度出发,我们会发现服务接收到一个请求后会解析请求读取请求的内容,然后调度此请求给到执行单元,这个执行单元可能是一个线程或者一个Goroutine,从执行单元的角度来看,以线程为例,线程的生命周期会有如下图所示的几个阶段:
- 新建
- 就绪
- 运行
- 阻塞
- 死亡
我们再从系统服务的限制方面考虑,一般系统的限制包括I/O限制和CPU限制,I/O限制指代I/O密集型的应用程序的限制,而CPU限制则是CPU密集型应用程序的限制:
- I/O密集型:表示服务需要进行大量的I/O操作,如磁盘读写、网络传输等,这类服务不需要进行大量的计算,但需要等待I/O操作完成,所以一般CPU占用率很低。
- CPU密集型:表示服务需要进行大量的CPU操作,如数据处理、图像处理、加密解密等,这类服务需要进行大量的计算,但不需要进行太多I/O相关的操作,所以I/O等待时间短,CPU占用率高。
在目前的服务应用中,绝大部分的应用程序是CPU密集型。
而CPU密集型服务,要想最大限度的利用CPU,最理想的情况所有的执行单元都处于运行和等待的状态,但等待和运行之间有个就绪的中间态,这也就意味着,如果想让所有的执行单元都处于运行和代码状态,我们就需要最小化就绪的执行单元数量。而就绪单元一旦获取到CPU资源(时间片)就会进入Running状态。
如果处于就绪的单元不断增多,在某种意义上意味着程序的CPU资源不足,即CPU过负载。从这个角度出发,我们可以利用执行单元处于就绪态的数量来判断服务是否过载。
在Golang的GMP模型中,P的数量是一定的,M的数量最多不超过10000个,而Goroutine的数量几乎是不定的。从上面利用就绪态(在Golang中是GRunnable状态)的数量来判断系统过载,也给我们提供了一个新的方案:判断系统所有P上(本地队列)的Goroutine处于GRunnable的数量,如果数量超过一个界定值,表示CPU资源不足,即过载。
4. 小结
在刚开始接触到服务的请求调度的时候,就想着看看是否有开源的方案来解决这个问题,果不其然,你能够想到的,大家曾经都想到过并付诸了时间和精力去给出了具体的方案设计,无论是SheddingHandler的设计,还是利用Goroutine的状态来判断系统是否过载,它们都有各自的理论为依托,但从精确度来说go-zero的SheddingHandler的设计相对来说更为准确,因为从CPU的真实数据出发,得到具体的CPU是否负载是最为可靠直观的。
判断Goroutine的就绪态数量这个方案,在最开始的接触中,自己是不太理解的,但从具体理论出发,包括后续自己也进行了相关的压测,以及Golang的trace.out文件的分析,在某种程度上,这种方案也是可行的,不禁感叹自己还是太弱了,还是要多学习,加油!