Linux:shell脚本:基础使用(4)《正则表达式-grep工具》
正则表达式定义:
使用单个字符串来描述,匹配一系列符合某个句法规则的字符串
正则表达式的组成:
普通字符串: 大小写字母,数字,标点符号及一些其他符号
元字符:在正则表达式中具有特殊意义的专用字符
正则表达式不能单独使用,需要配合一些命令 如 grep sed 等命令
正则表达式
我们先创建一个文件用于测试
he was short and fat.
He was wearing a blue polo shirt with black pants.
The home of Football on BBC Sport online.
the tongue is boneless but it breaks bones.12!
google is the best tools for search keyword.
The year ahead will test our political establishment to the li
PI=3.141592653589793238462643383249901429
a wood cross!
Actions speak louder than words#woood #
#woooooood #
AxyzxyzxyzxyzC
I bet this place is really spooky late at night!
Misfortunes never come alone/single.
I shouldn't have lett so tast.以上字符是我准备的一个文件的内容,等会我们用grep命令使用正则表达式去检索内容
文件名称无所谓,我的叫tarro.txt

grep
我们使用grep查询里面某一个指定的字符串 the
grep 'the' tarro.txt
里面每行带有the字符串的就出来了

如果想知道我们查找的字符串在第几行
grep -n 'the' tarro.txt
前面的数字就是在文件里的行,也就是这段在文件中的几行几行

如果想知道在文件中第几行,并且不区分大小写,也就是我们指定的字符串无论大小写都展示出来
grep -in 'the' tarro.txt
这样我们查找出来的就不区分大小写了,即使我们查的是小写the,加了-i 那么大写小写都会有

如果正好相反我们不想查包含指定字符串的行
grep -nv 'the' tarro.txt
-v就是反向查找,我们后面指定的字符串就反过来,就查找不带他们的行,反向查找不包含the的行

利用中括号[]来查找集合字符
[] ---里面无论有几个字符,都仅代表一个字符,为‘或’关系
[^] --- 括号里面的‘^’是取反的意思
查找包含shirt 或short的行
grep -n 'sh[io]rt' tarro.txt
可以看到他们中级的字符不一样,我们使用了查找 以sh 开通 rt结尾,中间o或者i 两个就全出来了

查找重复单个字符‘oo’的行
grep -n 'oo' test.txt
里面只要是两个oo相连的字符串就被查询出来了

查找‘oo’前不是‘w’的行
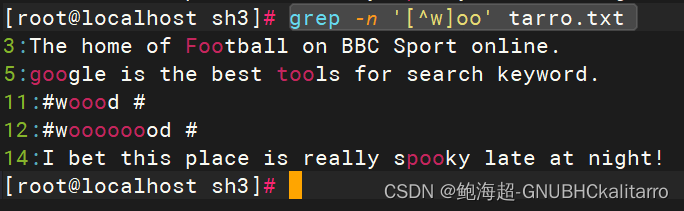
grep -n '[^w]oo' tarro.txt
去掉了w开头的,那为什么#woood # 和 #woooooood # 没被去掉,因为他们相连的字符串是以#开头的,你可以和上一个比对一下
查找‘oo’前不是小写字母的行
grep -n '[^a-z]oo' tarro.txt
现在前面小写的a-z开通的都被去掉了,F是大写的所以还在

查找‘oo’前不是大写字母的行
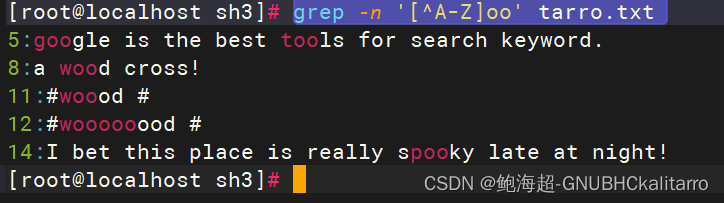
grep -n '[^A-Z]oo' tarro.txt
刚刚那个F开头的就没了,就剩下一些小写开头的行了
查找包含数字的行
grep -n '[0-9]' tarro.txt
上图只要是行内带有数字的行就被查出来了

查找行首^与行尾字符$
小数点‘.’在正则表达式中为元字符,需要使用转义字符‘\’将其转化为普通字符
查找以小数点‘.’结尾的行。
grep -n '\.$' tarro.txt

查找空行
grep -n '^$' test.txt
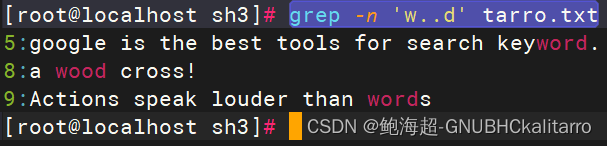
查找以‘w’开头,‘d’结尾共4个字符的行
grep -n 'w..d' tarro.txt
查询至少包含两个o以上的字符串
grep -n 'ooo*' tarro.txt
查找以‘w’开头,中间至少包含一个‘o'的,‘d’结尾的行
grep -n 'woo*d' tarro.txt
查找以‘w’开头,‘d’结尾 中间字符可有可无 的行
grep -n 'w.*d' test.txt
查询任意数字的行
grep -n '[0-9][0-9]*' test.txt
查找连续字符范围{}
使用'.' 和'*'可以设置零个或无限多个重复的字符
如果要限制一个范围则使用‘{}’
查看2个o的字符
grep -n 'o\{2\}' test.txt
查看w开头,d结尾,中间为2-5个o的字符串
grep -n 'wo\{2,5\}d' test.txt
查看w开头,d结尾,中间为2以上o的字符串
grep -n 'wo\{2,\}d' test.txt
基础正则表达式的常见元字符
\b 单词的开头或结尾,只匹配一个位置,不匹配分隔标点符号和空格 \bHello\b
\d 一个数字,等价于 [0-9] 0\d\d-\d{8} 固定电话
* 数量,它前面的内容以连续使用的任意次数以达到整个表达式匹配,可以是0次匹配 .*
+ 和* 类似,但至少匹配1次, 匹配一个或多个 \d+
? 和上面两个类似,重复0次或一次
. 匹配除了换行符以外任意字符
\s 匹配任意的空白符、制表符、换行符、中文全角空格等
\w 匹配字母、数字、汉字或者下划线
^ 用来查找的字符串的开头 ^\d{5,12}$ 5~12位的QQ
$ 用来查找的字符串的结尾
{n} 前面必须连续重复匹配n次,\d{8} \bw{6}\b 刚好6个字符的单词
{n,m} 前面必须连续重复匹配n~m次,
{n,} 前面必须连续重复匹配n~更多次,
\ 如果需要查找元字符,需要转义
[] 里面的字符可以不用转义,用来定义匹配集合 [?.*()]3.扩展正则表达式----egrep、awk命令支持
3.1 扩展正则表达式的常见元字符
+ 重复一个或者一个以上的前一个字符? 零个或者一个的前一个字符
| 使用或者(or)的方式找出多个字符
() 查找“组”字符串
()+ 辨别多个重复的组