基于MFCC特征提取和GMM训练的语音信号识别matlab仿真
目录
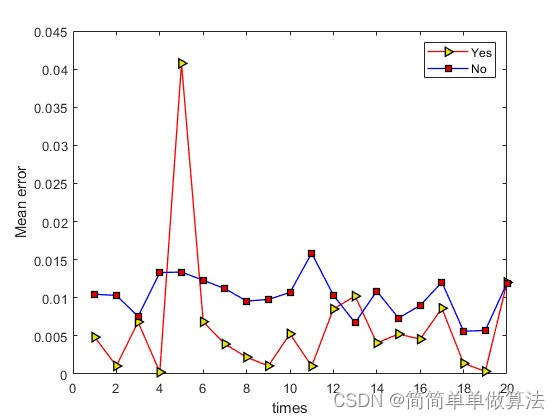
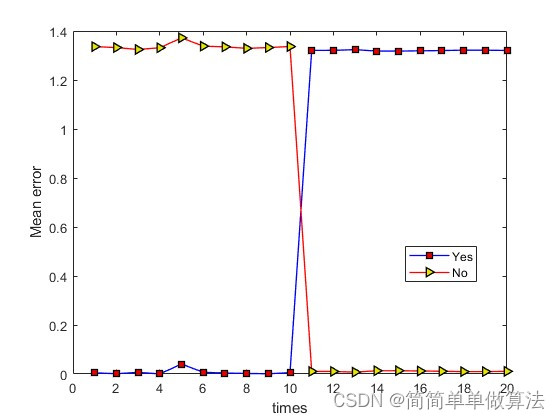
1.算法运行效果图预览
2.算法运行软件版本
3.部分核心程序
4.算法理论概述
4.1 MFCC特征提取
4.2 Gaussian Mixture Model(GMM)
4.3. 实现过程
4.4 应用领域
5.算法完整程序工程
1.算法运行效果图预览
2.算法运行软件版本
matlab2022a
3.部分核心程序
...........................................................................
Num_Gauss = 64;
%读取训练数据
[Speech_Train10,Fs] = audioread('Train_Samples\yes_no\yes3.wav');
[Speech_Train20,Fs] = audioread('Train_Samples\yes_no\no3.wav');
%endpoint
Index_use = func_cut(Speech_Train10,Fs,0);
Speech_Train1 = Speech_Train10(Index_use(1):Index_use(2));
Index_use = func_cut(Speech_Train20,Fs,0);
Speech_Train2 = Speech_Train20(Index_use(1):Index_use(2));
%预加重
%Step 1: pre-emphasis
Speech_Train1 = filter([1, -0.95], 1, Speech_Train1);
%Step 1: pre-emphasis
Speech_Train2 = filter([1, -0.95], 1, Speech_Train2);%MFCC提取
global Show_Wind;
Show_Wind = 0;
global Show_FFT;
Show_FFT = 0;Train_features1=melcepst(Speech_Train1,Fs);
Train_features2=melcepst(Speech_Train2,Fs);%GMM训练
[mu_train1,sigma_train1,c_train1]=fun_GMM_EM(Train_features1',Num_Gauss);
[mu_train2,sigma_train2,c_train2]=fun_GMM_EM(Train_features2',Num_Gauss);mu_train{1} = mu_train1;
mu_train{2} = mu_train2;
sigma_train{1} = sigma_train1;
sigma_train{2} = sigma_train2;
c_train{1} = c_train1;
c_train{2} = c_train2;save GMM_MFCC3.mat mu_train sigma_train c_train Train_features1 Train_features2
03_009m4.算法理论概述
语音信号识别是将输入的语音信号映射到对应的文本或语音标签的过程。基于MFCC(Mel-Frequency Cepstral Coefficients)特征提取和GMM(Gaussian Mixture Model)训练的方法在语音识别领域取得了显著的成果。
4.1 MFCC特征提取
MFCC是一种广泛用于语音信号处理的特征提取方法,它模拟了人类听觉系统对声音的感知。其主要步骤如下:
预加重: 原始语音信号经过预加重以平衡频谱。

分帧: 将信号分成短帧,通常为20-40毫秒。将预加重的语音信号分割成短帧,并对每帧应用窗函数,通常使用汉明窗或汉宁窗等。
加窗: 对每帧应用窗函数,以减少频谱泄漏。
快速傅里叶变换(FFT): 计算每帧的频谱。

Mel滤波器组: 将线性频谱转换为Mel频率刻度,以模拟人耳的感知。梅尔频率与实际频率的关系如下:
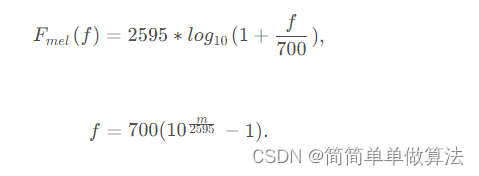
离散余弦变换(DCT): 将Mel频谱转换为倒谱系数,保留重要信息。

最终,得到的MFCC系数可以被视为每个帧的特征向量,用于进一步的语音信号分析、识别等任务。请注意,上述公式仅为MFCC特征提取的基本步骤,实际实现中可能会有一些微调和优化。
4.2 Gaussian Mixture Model(GMM)
GMM是一种用于建模概率分布的方法,常用于对语音特征进行建模。在语音信号识别中,每个语音类别(音素、词汇等)都可以由一个GMM来表示。GMM由多个高斯分布组成,用于描述特征空间中的数据分布。训练GMM的过程涉及以下步骤:
初始化: 随机初始化各个高斯分布的参数,如均值和协方差矩阵。
期望最大化(EM)算法: 迭代优化步骤,包括E步(计算后验概率)和M步(更新高斯分布参数)。
模型选择: 通过交叉验证等方法选择适当数量的高斯分布,以避免过拟合。
4.3. 实现过程
基于MFCC特征提取和GMM训练的语音信号识别过程包括以下步骤:
数据准备: 收集并整理语音数据集,其中包含录制的语音样本和相应的标签。
MFCC特征提取: 对每个语音样本应用MFCC特征提取过程,得到MFCC系数。
GMM训练: 对每个语音类别(音素、词汇等)分别训练一个GMM模型,使用EM算法优化模型参数。
解码: 给定一个未知语音样本,计算其MFCC特征并与各个GMM模型进行比较,选择概率最高的模型作为预测结果。
4.4 应用领域
基于MFCC特征提取和GMM训练的语音信号识别方法在以下领域得到应用:语音识别系统: 用于将说话人的语音转换为文本,支持语音助手、语音搜索等应用。说话人识别: 用于辨别不同说话人的声音,有助于语音安全认证和个性化服务。情感分析: 通过分析声音的特征,识别语音中蕴含的情感信息,如愉悦、紧张等。
5.算法完整程序工程
OOOOO
OOO
O