Hi-TRS:骨架点视频序列的层级式建模及层级式自监督学习
论文题目:Hierarchically Self-Supervised Transformer for Human Skeleton Representation Learning
论文下载地址:https://www.ecva.net/papers/eccv_2022/papers_ECCV/papers/136860181.pdf
代码地址:https://github.com/yuxiaochen1103/Hi-TRS/tree/main
层级式建模
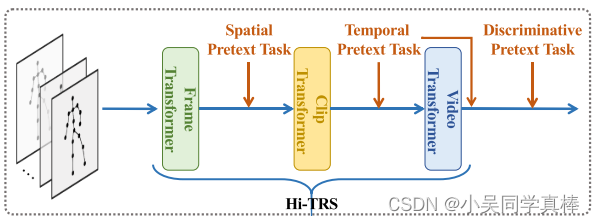
整个建模骨架点视频序列的网络架构由三个 Transformer 组成:
- 对关节点建模空间信息的 Frame-level Transformer (F-TRS)
- 对序列片段建模短期时序信息的 Clip-leve Transformer (C-TRS)
- 对整段骨架点视频序列建模长期时序信息的 Video-leve Transformer (V-TRS)
数据在其中是串行流动,即 F-TRS 的输出作为 C-TRS 的输入,以此类推。
Frame-level Transformer (F-TRS)
大家可能更加熟悉对图片进行建模的 Transformer:以 patch 为单位进行 Attention。
在这里,每个 joint 就相当于一个 patch,所以该 Transformer 做的是 joint 和 joint 之间的 Attention。
同时,该 Transformer 还为每个 joint 加上了可学习的位置编码(1D learnable positional embedding)。
Clip-leve Transformer (C-TRS)
在这个 Transformer 里,clip 里的每一帧的每个 joint 都相当于一个 patch。注意和上面的区别,这里 clip 里第 1 帧的左手节点和第 2 帧的左手节点会被认为是不同的 patch。
所以,该 Transformer 的可学习位置编码是二维的(2D learnable positional embedding)。
同时,作者为每个 clip 加上一个 [CLS] token,该 token 就汇聚了 clip 里所有帧里所有节点的信息。这个 token 也就作为该 clip 的 embedding。
Video-leve Transformer (V-TRS)
在这个 Transformer 里,每个 clip 相当于一个 patch,所以该 Transformer 做的是 clip 和 clip 之间的 Attention。
同样,该 Transformer 为每个 clip 加上了可学习的位置编码(1D learnable positional embedding)。
同时,作者为每个 video 加上一个 [CLS] token,该 token 就汇聚了 video 里所有 clips 的信息。这个 token 也就作为该 video 的 embedding。
层级式自监督学习
可以从上图可知,论文针对不同层级 Transformer 的输出做了不同代理任务的设计。

Spatial Pretext task
- 作用于 Frame-level Transformer 的输出 embeddings。
- 任务类似于 MAE,用不同的策略掩盖掉 15% 的关节点 embeddings。再接上一个全连接层,回归预测出被掩盖掉关节点的坐标。
- 该任务使用 L1-Loss 去约束预测值与真实值之间的差距。
Temporal Pretext task
- 分别作用于 Clip-leve Transformer 和 Video-leve Transformer 的输出 embeddings。
- 简单的二分类任务,判断时序正确与否。当作用于 Clip-leve Transformer 时,可能打乱 clip 中任意两帧 embeddings,也有可能不打乱,再接上一个全连接层,让其判断打乱与否;当作用于 Video-leve Transformer 时,可能打乱任意两个 clip embeddings 的顺序,也有可能不打乱,再接上一个全连接层,让其判断打乱与否;
- 用交叉熵损失函数约束任务的进行。
Discriminative Pretext task
- 作用于 Video-level Transformer 的输出 embeddings。
- 该任务是生成式任务,结合前几个 clip 的 embeddings 去预测最后一个 clip 的 embedding。同样通过接上一个全连接层,让其回归出最后一个 clip 的 embedding。
- 使用 InfoNCE Loss 来约束任务的进行。正样本对为最后一个 clip 的预测 embedding 和真实 embedding;负样本为同一个 batch 里其他 skeleton sequences 最后一个 clip 的真实 embedding
如果觉得有帮到你的话,可以点击右下方的“打赏”按钮~您的支持是我创作的最大动力呀~