科大讯飞发布星火认知大模型2.0版——体验实测
8月15日,科大讯飞举行讯飞星火认知大模型V2.0升级发布会,对外展示其升级后的大模型代码能力和多模态能力,同时发布并升级搭载讯飞星火认知大模型V2.0能力的多项应用和产品。自5月6日首发以来,星火认知大模型经历V1.5版本的迭代,于8月15日如期迎来V2.0版本。发布会现场,科大讯飞董事长刘庆峰、研究院院长刘聪重磅发布了星火大模型V2.0版本代码能力和多模态能力的升级成果,搭载讯飞星火认知大模型V2.0能力的多项应用和产品亦同步亮相。

V2.0除了在代码能力突破外,在多模态能力上也很出色。
本文的主要目的是想要实地对其表现能力进行测试分析。
【诺特兰德叶黄素与纯天然蔬菜中的叶黄素有什么区别】

【如果蒸一个包子需要10分钟,那么蒸100个包子需要多久?】

【你是一位资深的旅游导游,我接下来的520想要去海南三亚读过一个为期三天的小假期,从北京出发,请为我规划一份超级详细的旅游计划,包括:餐饮文娱、住宿交通、景点打卡等必备项目,也可以为我提前介绍一下当地的风土人情为了推荐特色美食、游玩项目等,请注意这次除了我老婆以外,还有我3岁的女儿,请妥善安排相应的时间避免太赶】

接下来我们看下在代码生成方面的情况:
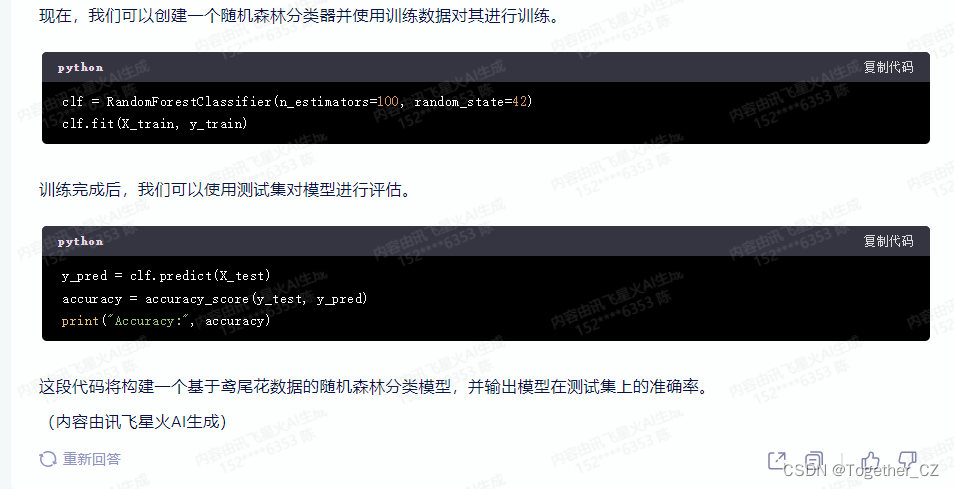
【请基于python开发构建基于鸢尾花数据的随机森林分类模型的代码】

【请基于MATLAB开发快速排序算法并给出运行实例】


【使用python基于opencv模块开发实现人脸检测模型】


【将上述代码转化为等价的C++代码】


【请基于python开发实现拉丁超立方体抽样算法,并给出运行实例】


【请基于python开发实现卡尔曼滤波算法,并给出运行实例】
卡尔曼滤波算法是一种线性最优估计算法,用于估计动态系统的状态。在Python中,我们可以使用numpy库来实现这个算法。以下是实现卡尔曼滤波算法的步骤:
- 导入所需库
- 定义一个函数,输入为状态转移矩阵、观测矩阵、初始状态和初始协方差矩阵
- 在函数中,初始化状态向量和协方差矩阵
- 定义预测函数,输入为当前状态和状态转移矩阵,输出为预测后的状态向量
- 定义更新函数,输入为当前状态向量、观测向量、观测矩阵和协方差矩阵,输出为更新后的协方差矩阵和状态向量
- 定义卡尔曼滤波函数,输入为初始状态、初始协方差矩阵和观测数据流,输出为滤波后的状态向量
- 返回卡尔曼滤波函数
以下是实现卡尔曼滤波算法的Python代码:
import numpy as npdef kalman_filter(F, H, Q, x0, P0):# 初始化状态向量和协方差矩阵x = np.array(x0)P = np.array(P0)# 定义预测函数def predict(x):return F @ x# 定义更新函数def update(z, y):# 预测x_pred = predict(x)P_pred = F @ P @ F.T + Q# 计算卡尔曼增益K = P_pred @ H.T @ np.linalg.inv(H @ P_pred @ H.T + R)# 更新状态向量和协方差矩阵x = x_pred - K @ (z - H @ x_pred)P = (np.eye(len(x)) - K @ H) @ P_predreturn x, P# 定义卡尔曼滤波函数def kalman_filter_step(x, P, z):x, P = update(z, None)return x, P# 初始化状态向量和协方差矩阵x = np.array(x0)P = np.array(P0)# 对观测数据流进行滤波for z in z_data:x, P = kalman_filter_step(x, P, z)return x# 运行实例
F = np.array([[1, 1], [0, 1]]) # 状态转移矩阵
H = np.array([[1, 0]]) # 观测矩阵
Q = np.array([[0.1, 0], [0, 0.1]]) # 过程噪声协方差矩阵
x0 = [0, 0] # 初始状态
P0 = np.array([[1, 0], [0, 1]]) # 初始协方差矩阵
z_data = [np.array([1]), np.array([2]), np.array([3])] # 观测数据流filtered_state = kalman_filter(F, H, Q, x0, P0)
print("滤波后的状态向量:", filtered_state)
【请基于python开发实现一个基础的transformer模型,来完成英语翻译成中文任务】
要实现一个基础的Transformer模型来完成英语翻译成中文任务,首先需要安装相关的库,如TensorFlow和transformers。然后,可以使用预训练的英文到中文的Transformer模型(如Hugging Face的MarianMT)作为基础模型,对其进行微调以适应自己的任务。
以下是一个简单的示例:
- 安装依赖库:
pip install transformers
pip install torch
- 导入所需的库:
import torch
from transformers import MarianMTModel, MarianTokenizer
- 加载预训练的英文到中文的Transformer模型和分词器:
model_name = 'Helsinki-NLP/opus-mt-en-zh'
tokenizer = MarianTokenizer.from_pretrained(model_name)
model = MarianMTModel.from_pretrained(model_name)
- 对输入文本进行编码:
input_text = "Hello, how are you?"
input_tokens = tokenizer.encode(input_text, return_tensors='pt')
- 将编码后的文本输入到模型中,获取翻译结果:
with torch.no_grad():output = model(input_tokens)[0]translation = tokenizer.decode(output[0], skip_special_tokens=True)
print(translation)
暂时没有去核对代码执行是否正常,直观体验感觉就是生成速度比较上一代模型更快了,生成的内容相对更充实一点。
接下来我们看下V2.0所声称的多模态能力。



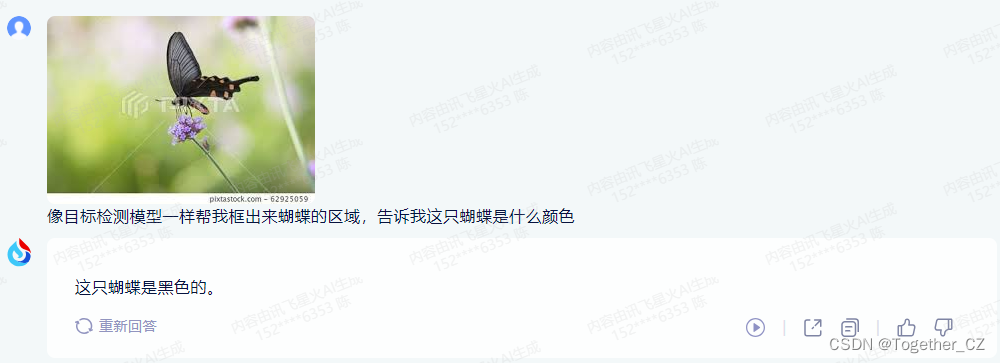
感觉这里的图像处理能力是限定在了图文理解上面了。没有办法对图像进行操作处理。


上面的回答凑合吧。下面的就差的太远了:

这个一半一半吧。

至于语音相关的我这里因为没有麦克风就没有去测试的了,感兴趣的欢迎交流下: