TiDB数据库从入门到精通系列之六:使用 TiCDC 将 TiDB 的数据同步到 Apache Kafka
TiDB数据库从入门到精通系列之六:使用 TiCDC 将 TiDB 的数据同步到 Apache Kafka
- 一、技术流程
- 二、搭建环境
- 三、创建Kafka changefeed
- 四、写入数据以产生变更日志
- 五、配置 Flink 消费 Kafka 数据
一、技术流程
- 快速搭建 TiCDC 集群、Kafka 集群和 Flink 集群
- 创建 changefeed,将 TiDB 增量数据输出至 Kafka
- 使用 go-tpc 写入数据到上游 TiDB
- 使用 Kafka console consumer 观察数据被写入到指定的 Topic
- (可选)配置 Flink 集群消费 Kafka 内数据
二、搭建环境
部署包含 TiCDC 的 TiDB 集群
在实验或测试环境中,可以使用 TiUP Playground 功能,快速部署 TiCDC,命令如下:
tiup playground --host 0.0.0.0 --db 1 --pd 1 --kv 1 --tiflash 0 --ticdc 1
# 查看集群状态
tiup status
三、创建Kafka changefeed
1.创建 changefeed 配置文件
根据 Flink 的要求和规范,每张表的增量数据需要发送到独立的 Topic 中,并且每个事件需要按照主键值分发 Partition。因此,需要创建一个名为 changefeed.conf 的配置文件,填写如下内容:
[sink]
dispatchers = [
{matcher = ['*.*'], topic = "tidb_{schema}_{table}", partition="index-value"},
]
2.创建一个 changefeed,将增量数据输出到 Kafka
tiup ctl:v<CLUSTER_VERSION> cdc changefeed
create --server="http://127.0.0.1:8300"
--sink-uri="kafka://127.0.0.1:9092/kafka-topic-name?protocol=canal-json"
--changefeed-id="kafka-changefeed"
--config="changefeed.conf"
如果命令执行成功,将会返回被创建的 changefeed 的相关信息,包含被创建的 changefeed 的 ID 以及相关信息,内容如下:
Create changefeed successfully!
ID: kafka-changefeed
Info: {... changfeed info json struct ...}
如果命令长时间没有返回,你需要检查当前执行命令所在服务器到 sink-uri 中指定的 Kafka 机器的网络可达性,保证二者之间的网络连接正常。
生产环境下 Kafka 集群通常有多个 broker 节点,你可以在 sink-uri 中配置多个 broker 的访问地址,这有助于提升 changefeed 到 Kafka 集群访问的稳定性,当部分被配置的 Kafka 节点故障的时候,changefeed 依旧可以正常工作。假设 Kafka 集群中有 3 个 broker 节点,地址分别为 127.0.0.1:9092 / 127.0.0.2:9092 / 127.0.0.3:9092,可以参考如下 sink-uri 创建 changefeed:
tiup ctl:v<CLUSTER_VERSION> cdc changefeed create
--server="http://127.0.0.1:8300"
--sink-uri="kafka://127.0.0.1:9092,127.0.0.2:9092,127.0.0.3:9092/kafka-topic-name?protocol=canal-json&partition-num=3&replication-factor=1&max-message-bytes=1048576"
--config="changefeed.conf"
3.Changefeed 创建成功后,执行如下命令,查看 changefeed 的状态
tiup ctl:v<CLUSTER_VERSION> cdc changefeed list --server="http://127.0.0.1:8300"
四、写入数据以产生变更日志
完成以上步骤后,TiCDC 会将上游 TiDB 的增量数据变更日志发送到 Kafka,下面对 TiDB 写入数据,以产生增量数据变更日志。
1.模拟业务负载
在测试实验环境下,可以使用 go-tpc 向上游 TiDB 集群写入数据,以让 TiDB 产生事件变更数据。如下命令,首先在上游 TiDB 创建名为 tpcc 的数据库,然后使用 TiUP bench 写入数据到这个数据库中。
tiup bench tpcc -H 127.0.0.1 -P 4000 -D tpcc --warehouses 4 prepare
tiup bench tpcc -H 127.0.0.1 -P 4000 -D tpcc --warehouses 4 run --time 300s
2.消费 Kafka Topic 中的数据
changefeed 正常运行时,会向 Kafka Topic 写入数据,你可以通过由 Kafka 提供的 kafka-console-consumer.sh,观测到数据成功被写入到 Kafka Topic 中:
./bin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --from-beginning --topic `${topic-name}`
至此,TiDB 的增量数据变更日志就实时地复制到了 Kafka。下一步,你可以使用 Flink 消费 Kafka 数据。当然,你也可以自行开发适用于业务场景的 Kafka 消费端。
五、配置 Flink 消费 Kafka 数据
1.安装 Flink Kafka Connector
在 Flink 生态中,Flink Kafka Connector 用于消费 Kafka 中的数据并输出到 Flink 中。Flink Kafka Connector 并不是内建的,因此在 Flink 安装完毕后,还需要将 Flink Kafka Connector 及其依赖项添加到 Flink 安装目录中。下载下列 jar 文件至 Flink 安装目录下的 lib 目录中,如果你已经运行了 Flink 集群,请重启集群以加载新的插件。
- flink-connector-kafka-1.17.1.jar
- flink-sql-connector-kafka-1.17.1.jar
- kafka-clients-3.5.1.jar
2.创建一个表
可以在 Flink 的安装目录执行如下命令,启动 Flink SQL 交互式客户端:
[root@flink flink-1.15.0]# ./bin/sql-client.sh
随后,执行如下语句创建一个名为 tpcc_orders 的表:
CREATE TABLE tpcc_orders (o_id INTEGER,o_d_id INTEGER,o_w_id INTEGER,o_c_id INTEGER,o_entry_d STRING,o_carrier_id INTEGER,o_ol_cnt INTEGER,o_all_local INTEGER
) WITH (
'connector' = 'kafka',
'topic' = 'tidb_tpcc_orders',
'properties.bootstrap.servers' = '127.0.0.1:9092',
'properties.group.id' = 'testGroup',
'format' = 'canal-json',
'scan.startup.mode' = 'earliest-offset',
'properties.auto.offset.reset' = 'earliest'
)
请将 topic 和 properties.bootstrap.servers 参数替换为环境中的实际值。
3.查询表内容
执行如下命令,查询 tpcc_orders 表中的数据:
SELECT * FROM tpcc_orders;
执行成功后,可以观察到有数据输出,如下图
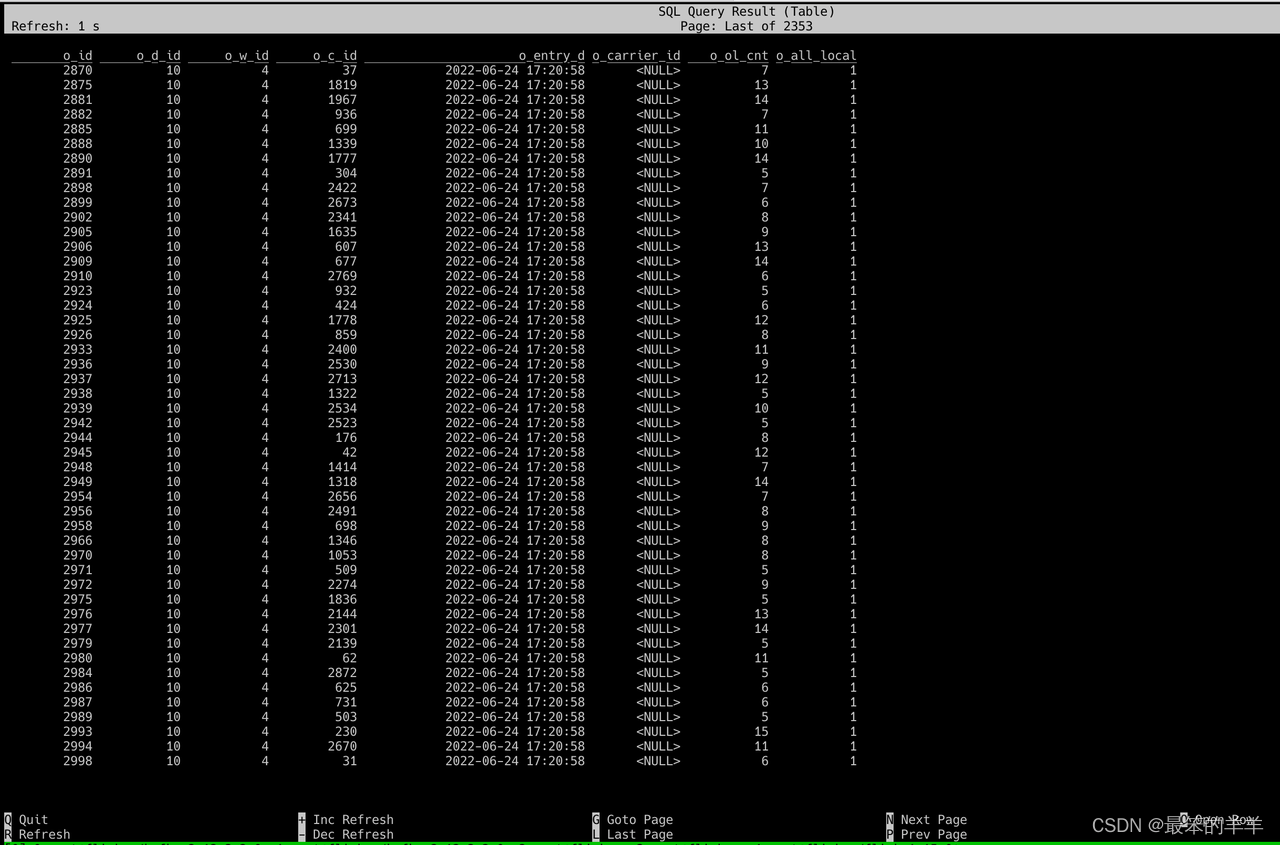
至此,就完成了 TiDB 与 Flink 的数据集成。