Flink CDC系列之:TiDB CDC 导入 Elasticsearch
Flink CDC系列之:TiDB CDC 导入 Elasticsearch
- 一、通过docker 来启动 TiDB 集群
- 二、下载 Flink 和所需要的依赖包
- 三、在TiDB数据库中创建表和准备数据
- 四、启动Flink 集群,再启动 SQL CLI
- 五、在 Flink SQL CLI 中使用 Flink DDL 创建表
- 六、Kibana查看ElasticSearch数据
- 七、在 TiDB增删改数据,观察 ElasticSearch 中的结果
一、通过docker 来启动 TiDB 集群
git clone https://github.com/pingcap/tidb-docker-compose.git
替换目录 tidb-docker-compose 里面的 docker-compose.yml 文件,内容如下所示:
version: "2.1"services:pd:image: pingcap/pd:v5.3.1ports:- "2379:2379"volumes:- ./config/pd.toml:/pd.toml- ./logs:/logscommand:- --client-urls=http://0.0.0.0:2379- --peer-urls=http://0.0.0.0:2380- --advertise-client-urls=http://pd:2379- --advertise-peer-urls=http://pd:2380- --initial-cluster=pd=http://pd:2380- --data-dir=/data/pd- --config=/pd.toml- --log-file=/logs/pd.logrestart: on-failuretikv:image: pingcap/tikv:v5.3.1ports:- "20160:20160"volumes:- ./config/tikv.toml:/tikv.toml - ./logs:/logs command:- --addr=0.0.0.0:20160- --advertise-addr=tikv:20160- --data-dir=/data/tikv- --pd=pd:2379- --config=/tikv.toml- --log-file=/logs/tikv.logdepends_on:- "pd"restart: on-failuretidb:image: pingcap/tidb:v5.3.1ports:- "4000:4000"volumes:- ./config/tidb.toml:/tidb.toml- ./logs:/logscommand:- --store=tikv- --path=pd:2379- --config=/tidb.toml- --log-file=/logs/tidb.log- --advertise-address=tidbdepends_on:- "tikv"restart: on-failureelasticsearch:image: elastic/elasticsearch:7.6.0container_name: elasticsearchenvironment:- cluster.name=docker-cluster- bootstrap.memory_lock=true- "ES_JAVA_OPTS=-Xms512m -Xmx512m"- discovery.type=single-nodeports:- "9200:9200"- "9300:9300"ulimits:memlock:soft: -1hard: -1nofile:soft: 65536hard: 65536kibana:image: elastic/kibana:7.6.0container_name: kibanaports:- "5601:5601"volumes:- /var/run/docker.sock:/var/run/docker.sock
该 Docker Compose 中包含的容器有:
- TiDB 集群: tikv、pd、tidb。
- Elasticsearch:orders 表将和 products 表进行 join,join 的结果写入 Elasticsearch 中。
- Kibana:可视化 Elasticsearch 中的数据。
本机添加 host 映射 pd 和 tikv 映射 127.0.0.1。 在 docker-compose.yml 所在目录下运行如下命令以启动所有容器:
docker-compose up -d
mysql -h 127.0.0.1 -P 4000 -u root # Just test tidb cluster is ready,if you have install mysql local.
该命令会以 detached 模式自动启动 Docker Compose 配置中定义的所有容器。 你可以通过 docker ps 来观察上述的容器是否正常启动了。 也可以访问 http://localhost:5601/ 来查看 Kibana 是否运行正常。
另外可以通过如下命令停止并删除所有的容器:
docker-compose down
二、下载 Flink 和所需要的依赖包
下载 Flink 1.17.1 并将其解压至目录 flink-1.17.1
https://archive.apache.org/dist/flink/flink-1.17.1/flink-1.17.1-bin-scala_2.12.tgz
下载下面列出的依赖包,并将它们放到目录 flink-1.17.1/lib/ 下:
- flink-connector-tidb-cdc-2.4.1.jar
- flink-sql-connector-elasticsearch7-3.0.1-1.17.jar
三、在TiDB数据库中创建表和准备数据
创建数据库和表 products,orders,并插入数据:
-- TiDB
CREATE DATABASE mydb;
USE mydb;
CREATE TABLE products (id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY,name VARCHAR(255) NOT NULL,description VARCHAR(512)
) AUTO_INCREMENT = 101;INSERT INTO products
VALUES (default,"scooter","Small 2-wheel scooter"),(default,"car battery","12V car battery"),(default,"12-pack drill bits","12-pack of drill bits with sizes ranging from #40 to #3"),(default,"hammer","12oz carpenter's hammer"),(default,"hammer","14oz carpenter's hammer"),(default,"hammer","16oz carpenter's hammer"),(default,"rocks","box of assorted rocks"),(default,"jacket","water resistent black wind breaker"),(default,"spare tire","24 inch spare tire");CREATE TABLE orders (order_id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY,order_date DATETIME NOT NULL,customer_name VARCHAR(255) NOT NULL,price DECIMAL(10, 5) NOT NULL,product_id INTEGER NOT NULL,order_status BOOLEAN NOT NULL -- Whether order has been placed
) AUTO_INCREMENT = 10001;INSERT INTO orders
VALUES (default, '2020-07-30 10:08:22', 'Jark', 50.50, 102, false),(default, '2020-07-30 10:11:09', 'Sally', 15.00, 105, false),(default, '2020-07-30 12:00:30', 'Edward', 25.25, 106, false);四、启动Flink 集群,再启动 SQL CLI
使用下面的命令跳转至 Flink 目录下
cd flink-1.17.1
使用下面的命令启动 Flink 集群
./bin/start-cluster.sh
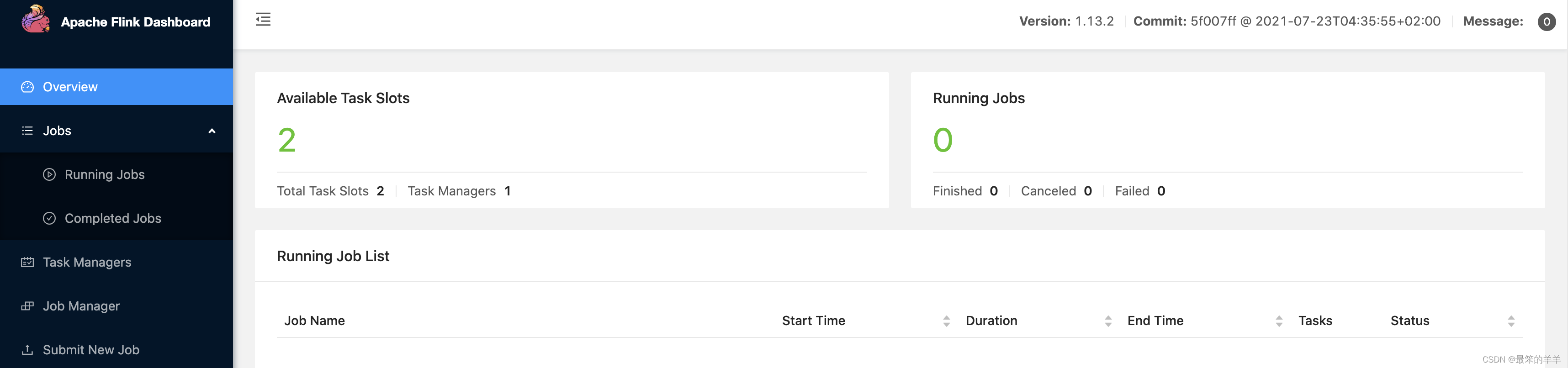
启动成功的话,可以在 http://localhost:8081/ 访问到 Flink Web UI,如下所示:
使用下面的命令启动 Flink SQL CLI
./bin/sql-client.sh
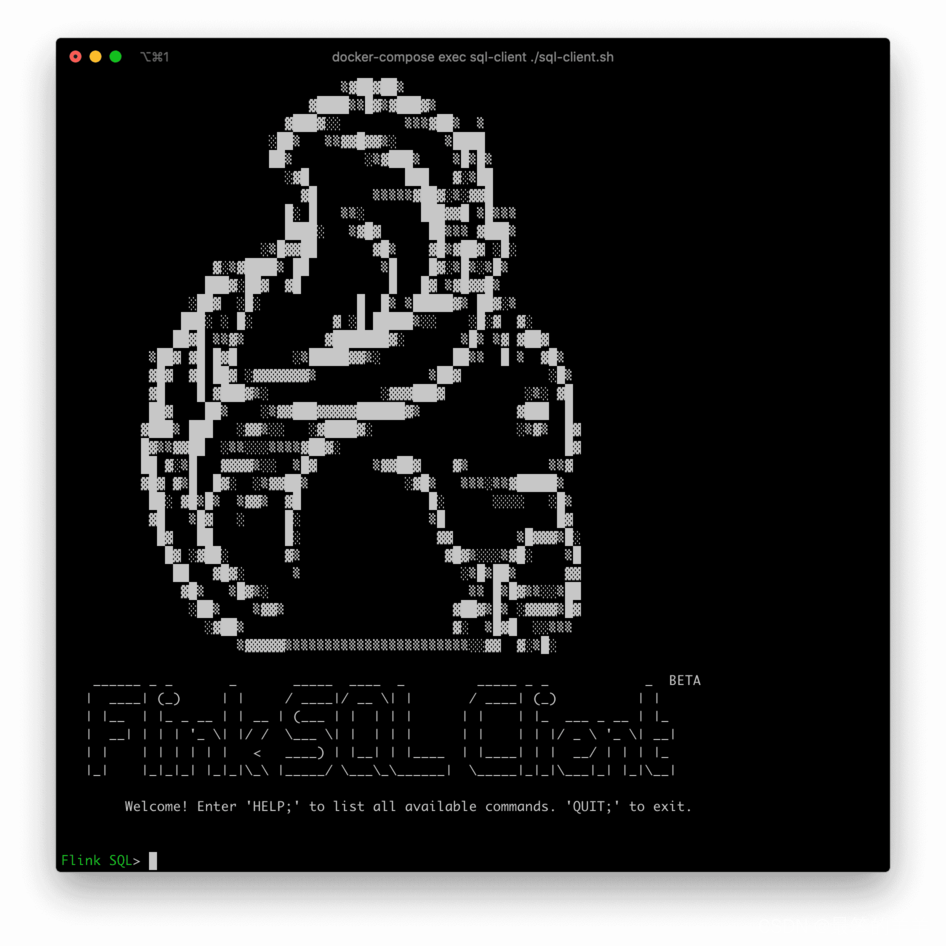
启动成功后,可以看到如下的页面:
五、在 Flink SQL CLI 中使用 Flink DDL 创建表
首先,开启 checkpoint,每隔3秒做一次 checkpoint
-- Flink SQL
Flink SQL> SET execution.checkpointing.interval = 3s;
使用 Flink SQL CLI 创建对应的表,用于同步这些底层数据库表的数据
Flink SQL> CREATE TABLE products (id INT,name STRING,description STRING,PRIMARY KEY (id) NOT ENFORCED) WITH ('connector' = 'tidb-cdc','tikv.grpc.timeout_in_ms' = '20000','pd-addresses' = '127.0.0.1:2379','database-name' = 'mydb','table-name' = 'products');Flink SQL> CREATE TABLE orders (order_id INT,order_date TIMESTAMP(3),customer_name STRING,price DECIMAL(10, 5),product_id INT,order_status BOOLEAN,PRIMARY KEY (order_id) NOT ENFORCED) WITH ('connector' = 'tidb-cdc','tikv.grpc.timeout_in_ms' = '20000','pd-addresses' = '127.0.0.1:2379','database-name' = 'mydb','table-name' = 'orders'
);Flink SQL> CREATE TABLE enriched_orders (order_id INT,order_date DATE,customer_name STRING,order_status BOOLEAN,product_name STRING,product_description STRING,PRIMARY KEY (order_id) NOT ENFORCED) WITH ('connector' = 'elasticsearch-7','hosts' = 'http://localhost:9200','index' = 'enriched_orders_1');
将关联后的数据插入到ElasticSearch
Flink SQL> INSERT INTO enriched_ordersSELECT o.order_id, o.order_date, o.customer_name, o.order_status, p.name, p.descriptionFROM orders AS oLEFT JOIN products AS p ON o.product_id = p.id;
六、Kibana查看ElasticSearch数据
检查最终的结果是否写入 ElasticSearch 中,可以在 Kibana 看到 ElasticSearch 中的数据。
首先访问 http://localhost:5601/app/kibana#/management/kibana/index_pattern 创建 index pattern enriched_orders.
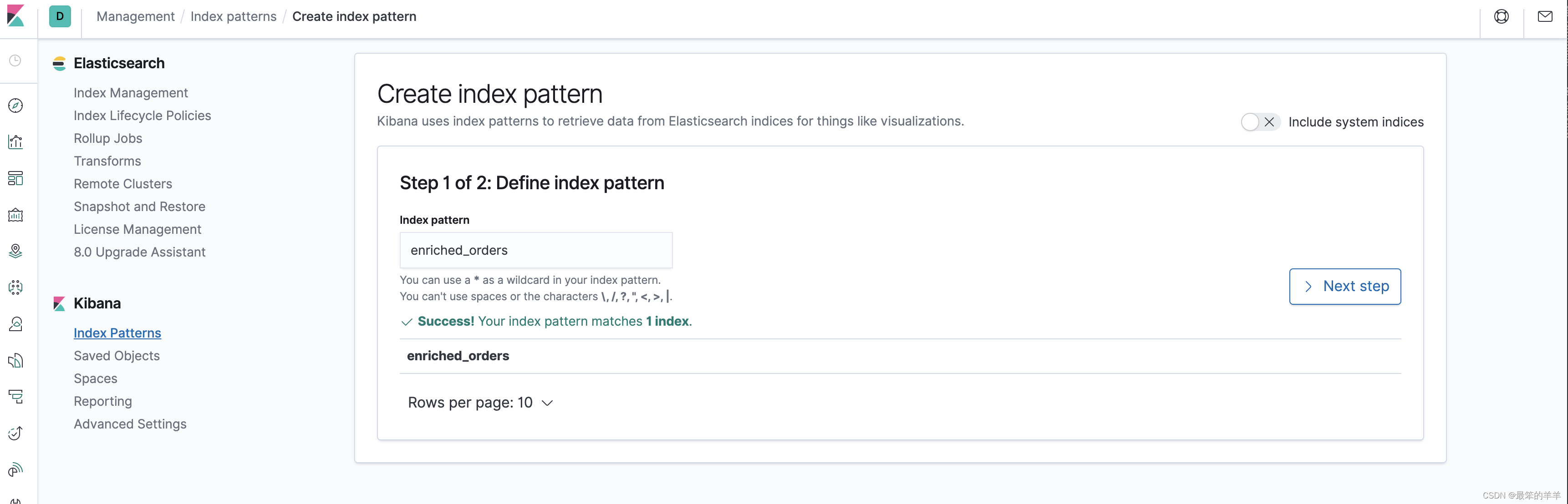
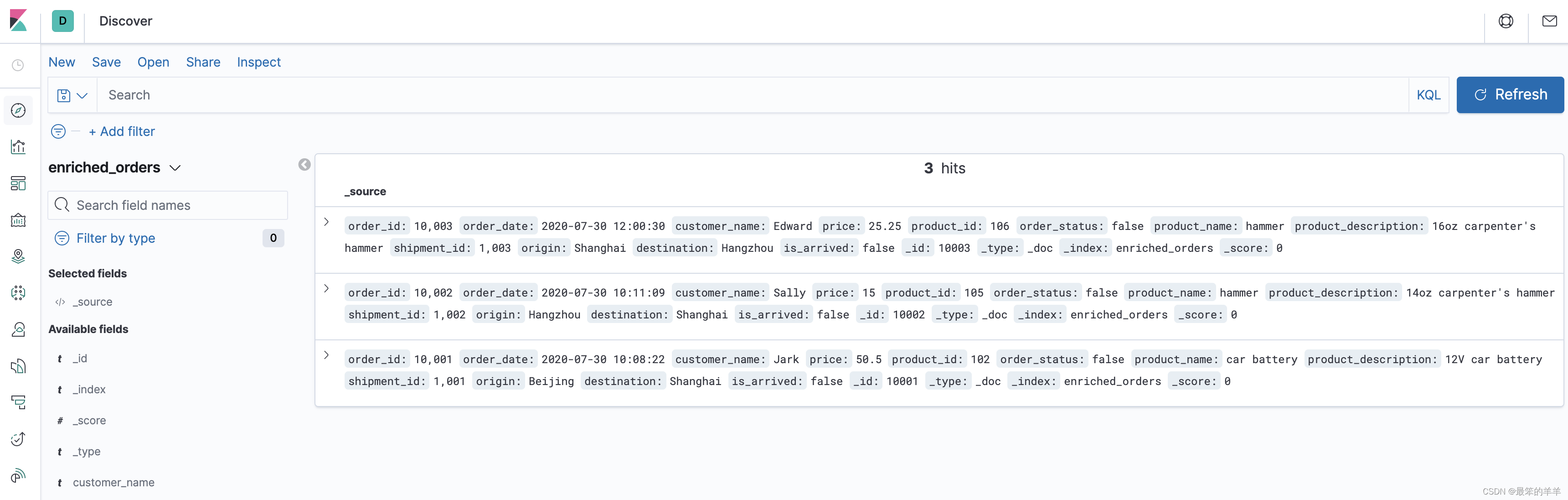
然后就可以在 http://localhost:5601/app/kibana#/discover 看到写入的数据了.
七、在 TiDB增删改数据,观察 ElasticSearch 中的结果
通过如下的 SQL 语句对 TiDB 数据库进行一些修改,然后就可以看到每执行一条 SQL 语句,Elasticsearch 中的数据都会实时更新。
INSERT INTO orders
VALUES (default, '2020-07-30 15:22:00', 'Jark', 29.71, 104, false);UPDATE orders SET order_status = true WHERE order_id = 10004;DELETE FROM orders WHERE order_id = 10004;