神经网络基础-神经网络补充概念-03-逻辑回归损失函数
概念
逻辑回归使用的损失函数通常是"对数损失"(也称为"交叉熵损失")或"逻辑损失"。这些损失函数在训练过程中用于衡量模型预测与实际标签之间的差异,从而帮助模型逐步调整权重参数,以更好地拟合数据
公式说明
在二分类的逻辑回归中,假设标签为0或1,对于给定的样本 ( x , y ) (x, y) (x,y),其中 x x x 是特征向量, y y y 是标签(0或1)。逻辑回归模型预测的概率为 p ( y = 1 ∣ x ) p(y=1|x) p(y=1∣x)。
逻辑回归的损失函数为对数损失(交叉熵损失),其表达式如下:
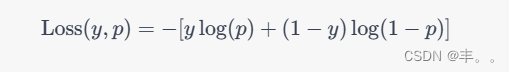
其中, y y y 是真实标签, p p p 是模型预测的概率。这个损失函数的意义在于,当真实标签为1时,模型预测的概率越接近1,损失越小;当真实标签为0时,模型预测的概率越接近0,损失越小。反之,如果模型的预测与真实标签相差较大,则损失会增大。
优化的目标是最小化所有训练样本的损失,以找到最优的权重参数,使模型的预测与真实标签尽可能吻合。
需要注意的是,很多优化算法(例如梯度下降法)都可以用于最小化这个损失函数,从而找到最优的模型参数。在实际应用中,通常使用机器学习库提供的优化函数来自动完成这个过程。
代码实现
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score# 生成示例数据
np.random.seed(42)
X = np.random.rand(100, 2) # 特征矩阵,每行表示一个数据点,每列表示一个特征
y = (X[:, 0] + X[:, 1] > 1).astype(int) # 标签,根据特征之和是否大于1进行分类# 数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 特征标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)# 创建并训练逻辑回归模型
model = LogisticRegression()
model.fit(X_train_scaled, y_train)# 在测试集上进行预测
y_pred = model.predict(X_test_scaled)# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")我们首先生成了示例数据,然后将数据集划分为训练集和测试集。接着,我们使用StandardScaler对特征进行标准化,以便逻辑回归模型能够更好地拟合。然后,我们创建了一个LogisticRegression模型,并使用训练数据进行训练。最后,我们在测试集上进行了预测,并计算了模型的准确率。