numba 入门示例
一维向量求和: C = A + B
在有nv 近几年gpu的ubuntu 机器上,
环境预备:
conda create -name numba_cuda_python3.10 python=3.10
conda activate numba_cuda_python3.10conda install numba
conda install cudatoolkit
conda install -c nvidia cuda-pythonor $ conda install nvidia::cuda-python示例1:源代码
C[i] = A[i] + B[i]
hello_numba_cpu_01.py
import time
import numpy as np
from numba import jit
from numba import njitdef f_py(a, b, c, N):for i in range(N):c[i] = a[i] + b[i]@jit
def f_bin(a, b, c, N):for i in range(N):c[i] = a[i] + b[i]@njit
def f_pure_bin(a, b, c, N):for i in range(N):c[i] = a[i] + b[i]if __name__ == "__main__":np.random.seed(1234)N = 1024*1024*128a_h = np.random.random(N)b_h = np.random.random(N)c_h1 = np.random.random(N)c_h2 = np.random.random(N)c_h3 = np.random.random(N)f_bin(a_h, b_h, c_h1, N)print('a_h =', a_h)print('b_h =', b_h)print('c_h1 =', c_h1)#c_h = np.random.random(N)#print('c_h =', c_h)f_pure_bin(a_h, b_h, c_h2, N)print('c_h2 =', c_h2)s1 = time.time()f_py(a_h, b_h, c_h1, N)e1 = time.time()print('time py:',e1 - s1)s1 = time.time()f_bin(a_h, b_h, c_h2, N)e1 = time.time()print('time jit:',e1 - s1)s1 = time.time()f_pure_bin(a_h, b_h, c_h3, N)e1 = time.time()print('time njit:',e1 - s1)print('c_h1 =', c_h1)print('c_h2 =', c_h2)print('c_h3 =', c_h3)运行时间,纯python是26s,jit是0.23s:

示例2:源代码
C[i] = A[i] + B[i]
hello_numba_gpu_02.py
import time
import numpy as np
from numba import jit
from numba import njit
from numba import cudadef f_py(a, b, c, N):for i in range(N):c[i] = a[i] + b[i]@jit
def f_bin(a, b, c, N):for i in range(N):c[i] = a[i] + b[i]@njit
def f_pure_bin(a, b, c, N):for i in range(N):c[i] = a[i] + b[i]@cuda.jit
def f_gpu(a, b, c):# like threadIdx.x + (blockIdx.x * blockDim.x)tid = cuda.grid(1)size = len(c)if tid < size:c[tid] = a[tid] + b[tid]if __name__ == "__main__":np.random.seed(1234)
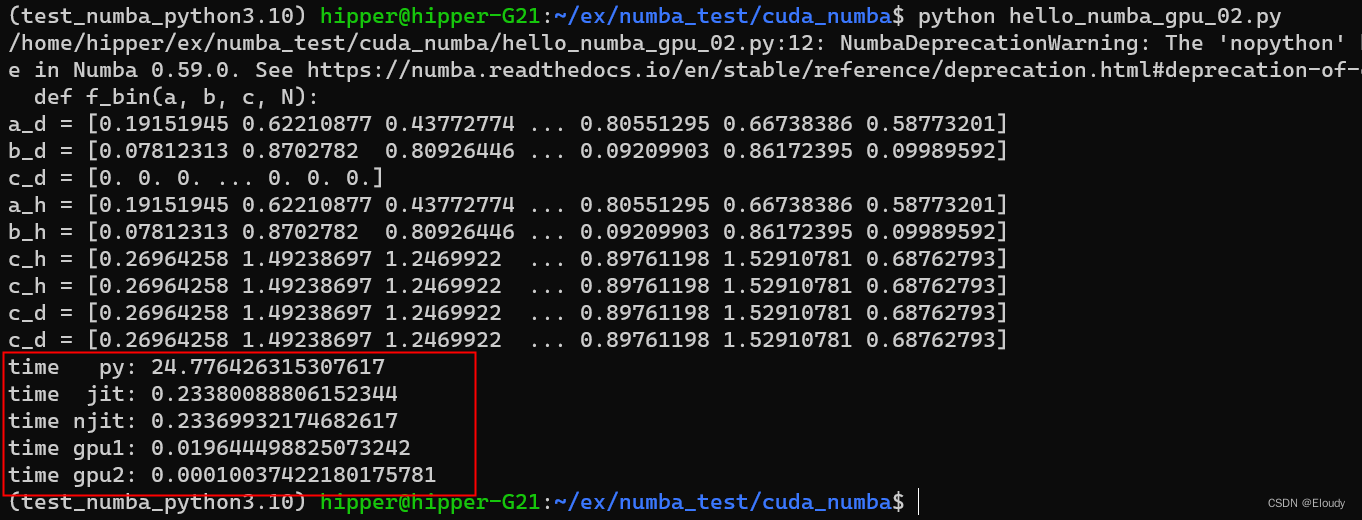
# M = np.random.random([int(4e3)] * 2)N = 1024*1024*128a_d = cuda.to_device(np.random.random(N))b_d = cuda.to_device(np.random.random(N))c_d = cuda.device_array_like(a_d)print('a_d =', a_d.copy_to_host())print('b_d =', b_d.copy_to_host())print('c_d =', c_d.copy_to_host())a_h = a_d.copy_to_host()b_h = b_d.copy_to_host()c_h = c_d.copy_to_host()f_bin(a_h, b_h, c_h, N)print('a_h =', a_h)print('b_h =', b_h)print('c_h =', c_h)c_h = np.random.random(N)#print('c_h =', c_h)f_pure_bin(a_h, b_h, c_h, N)print('c_h =', c_h)f_gpu.forall(len(a_d))(a_d, b_d, c_d)print('c_d =', c_d.copy_to_host())# Enough threads per block for several warps per blocknthreads = 256# Enough blocks to cover the entire vector depending on its lengthnblocks = (len(a_d) // nthreads) + 1f_gpu[nblocks, nthreads](a_d, b_d, c_d)print('c_d =', c_d.copy_to_host())s1 = time.time()f_py(a_h, b_h, c_h, N)e1 = time.time()print('time py:',e1 - s1)s1 = time.time()f_bin(a_h, b_h, c_h, N)e1 = time.time()print('time jit:',e1 - s1)s1 = time.time()f_pure_bin(a_h, b_h, c_h, N)e1 = time.time()print('time njit:',e1 - s1)s1 = time.time()f_gpu.forall(len(a_d))(a_d, b_d, c_d)e1 = time.time()print('time gpu1:',e1 - s1)s1 = time.time()f_gpu[nblocks, nthreads](a_d, b_d, c_d)e1 = time.time()print('time gpu2:',e1 - s1)
gpu的加速非常明显,N万倍: