知识图谱基本工具Neo4j使用笔记 四 :使用csv文件批量导入图谱数据
文章目录
- 一、系统说明
- 二、说明
- 三、简单介绍
- 1. 相关代码以及参数
- 2. 简单示例
- 四、实际数据实践
- 1. 前期准备
- (1) 创建一个用于测试的neo4j数据库
- (2)启动neo4j 查看数据库
- 2. 实践
- (1) OK 上面完成后,准备数据
- 1. 示例实体数据
- 2. 示例 关系数据
- 3. 示例 存放位置
- (2) 数据准备好开始存储
- 1. 注意事项
- 2. 存储代码 编写
- 3. 打开终端 在终端 键入上面命令 注意路径
- 4. 查看效果
一、系统说明
neo4j 版本:neo4j-community-4.4.23
系统:win11
二、说明
一般我们进行小规模数据,如几百几千数据使用 py2neo 脚本,存储。并不会觉得速度慢或者快。但是当数据量达到几万甚至几百万时候,用脚本就相当耗费时间。解决方法很多,这里一起讨论一个相对简单的方法,利用csv文件进行存储。
这里说一下:有的版本 import 文件是在bin文件夹下,但是使用的版本不在。
三、简单介绍
1. 相关代码以及参数
以下是 neo4j-admin import 命令的语法:
neo4j-admin import \--database=<database> \[--mode=<import-mode>] \[--nodes=<node-file> [--nodes=<node-file> ...]] \[--relationships=<relationship-file> [--relationships=<relationship-file> ...]] \[--delimiter=<delimiter>] \[--array-delimiter=<array-delimiter>] \[--ignore-missing-nodes=<true/false>] \[--skip-duplicate-nodes=<true/false>] \[--ignore-duplicate-relationships=<true/false>] \[--additional-config=<config-file>]
现在我们来解释每个字段的含义并举例说明:
--database: 指定要导入的数据库名称。
--mode: 指定导入模式,有两种可选值:csv 和 database。默认为 csv 模式,表示从 CSV 文件导入数据。
--nodes: 指定包含节点数据的 CSV 文件路径。可以指定多个节点文件。
--relationships: 指定包含关系数据的 CSV 文件路径。可以指定多个关系文件。
--delimiter: 指定 CSV 文件中字段之间的分隔符,默认为逗号 ,。
--array-delimiter: 指定 CSV 文件中数组类型字段中元素之间的分隔符,默认为 ;。
--ignore-missing-nodes: 如果关系中的节点不存在是否忽略,默认为 false。
--skip-duplicate-nodes: 是否跳过重复的节点,默认为 false。
--ignore-duplicate-relationships: 是否忽略重复的关系,默认为 false。
--additional-config: 指定一个配置文件来设置其他导入选项。
2. 简单示例
neo4j-admin import \--database=my-database \--nodes=nodes.csv \--relationships=relationships.csv \--delimiter=,
在这个示例中,我们将从名为 nodes.csv 的文件导入节点,并从名为 relationships.csv 的文件导入关系。CSV 文件中的字段将使用逗号作为分隔符。
四、实际数据实践
1. 前期准备
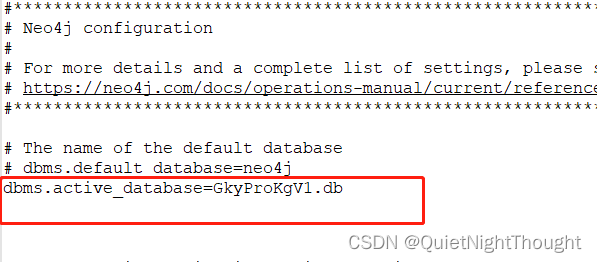
(1) 创建一个用于测试的neo4j数据库
在这里进行处理,打开conf文件中的 配置文件
类似这样进行创建,即可
(2)启动neo4j 查看数据库
启动命令
neo4j.bat console
打开data 文件夹(该文件在安装目录)
可以看到创建成功了。数据库在 database 文件下
2. 实践
(1) OK 上面完成后,准备数据
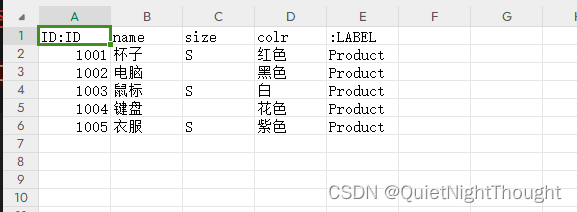
1. 示例实体数据
数据解释:
实体文件格式:<nodeId:ID>, <propertyName1>, <propertyName2>, ..., <:LABEL>
开始为编号:ID,是唯一的,用于创建关系等后续import操作时索引到指定节点
中间为节点属性:最好用英文
结束为标签:LABEL 不是必须的 一个节点有多个标签
注意:大小写以及 :不要遗漏,这里的 ID指定,比较灵活,可以根据需要来。
: 前面的是,该字段的原来属性名字,后面用于创建关系等后续import操作时索引到指定节点

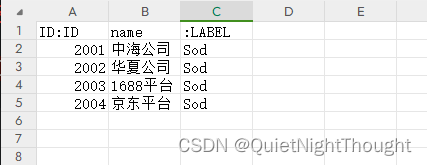
2. 示例 关系数据
.关系文件格式:<:START_ID>, <:END_ID>, <:TYPE>,<RelationshipPropertiesName1>,...<RelationshipPropertiesName2>
:START_ID :关系起点节点的ID编号 必须有
:END_ID:关系结束点节点的ID编号 必须有
:TYPE:关系的类别 必须有
RelationshipPropertiesName:关系属性 非必须
我这里给关系添加了一个 name属性

3. 示例 存放位置


(2) 数据准备好开始存储
1. 注意事项
-
注意csv文件的编码格式,若内容含有中文,要将编码转为“UTF-8”
-
输入neo4j-admin import语句
先
关闭neo4j:neo4j stop
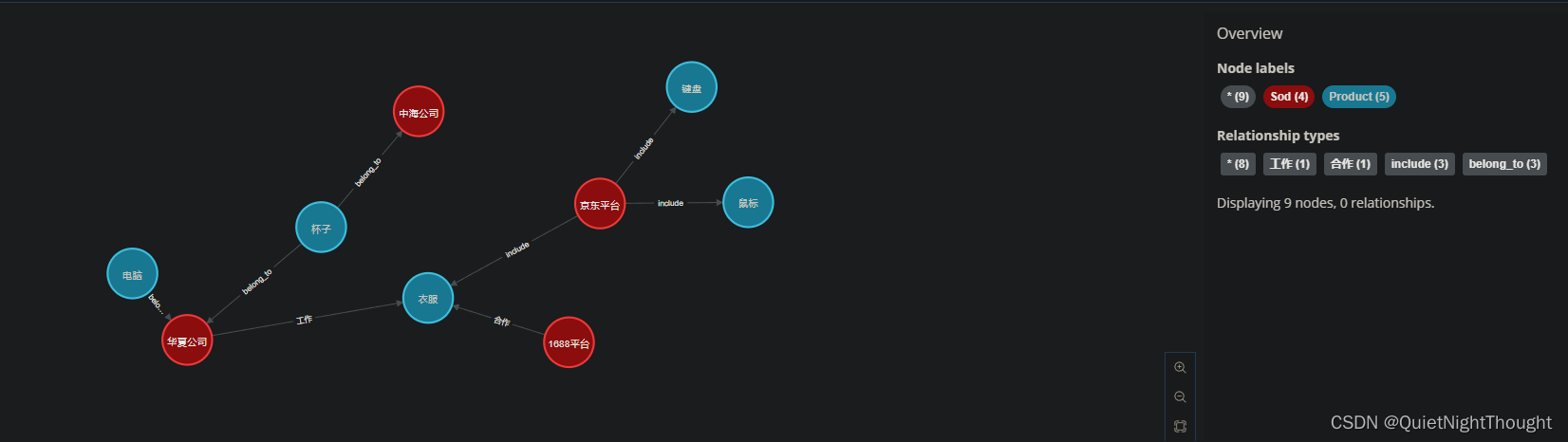
其中Product和Sod为标签
2. 存储代码 编写
neo4j-admin import
--database=GkyProKgV1.db
--nodes=Product="D:\AI_Tool\neo4j\neo4j-community-4.4.23\import\entity\product.csv"
--nodes=Sod="D:\AI_Tool\neo4j\neo4j-community-4.4.23\import\entity\sod.csv"
--relationships="D:\AI_Tool\neo4j\neo4j-community-4.4.23\import\relation\relation.csv"
--force
3. 打开终端 在终端 键入上面命令 注意路径
我的 neo4j 安装路径
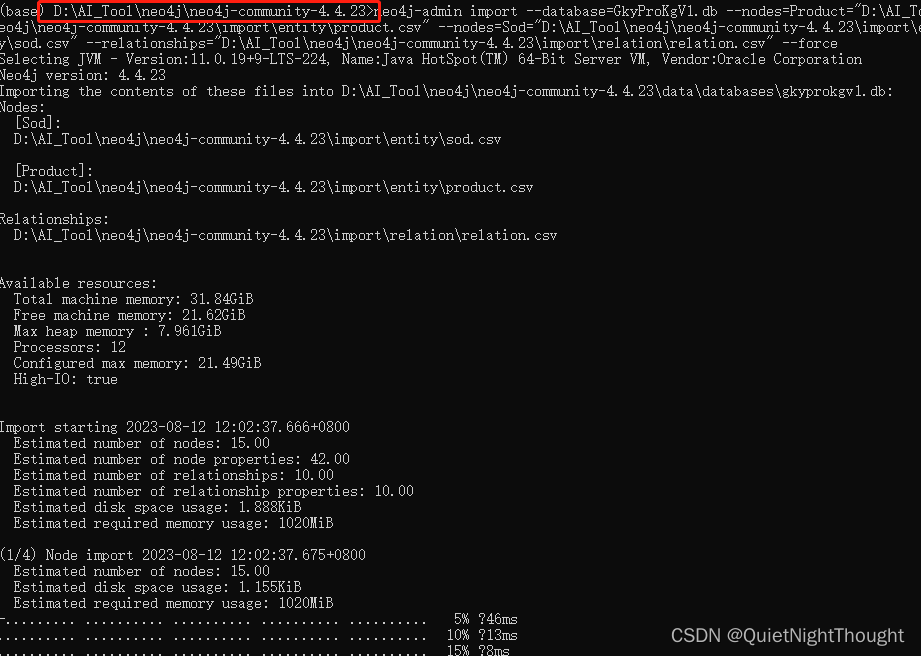
4. 查看效果