DataGrip 配置 HiveServer2 远程连接访问
文章目录
- 集群配置 HiveServer2 服务
- DataGrip 配置 HiveServer2 访问 Hive
集群配置 HiveServer2 服务
1.在 Hive 的配置文件 hive-site.xml 中添加如下参数:
<!-- 指定 HiveServer2 运行端口,默认为:10000 --><property><name>hive.server2.thrift.port</name><value>10000</value></property><!-- 设置连接主机 --><property><name>hive.server2.thrift.bind.host</name><value>master</value></property><!-- 设置权限用户 --><property><name>hive.users.in.admin.role</name><value>root</value></property> <!--自定义远程连接用户名和密码 默认为none,修改成CUSTOM--><property><name>hive.server2.authentication</name><value>CUSTOM</value></property><!--指定解析jar包--><property><name>hive.server2.custom.authentication.class</name><value>org.apache.hadoop.hive.contrib.auth.CustomPasswdAuthenticator</value></property> <!--设置用户名和密码--><property><name>hive.jdbc_passwd.auth.root</name><!--用户名为最后一个:root--><value>000000</value><!--密码--></property>
注意更换成你自己连接的主机地址。
2.在 Hadoop 的核心配置文件 core-site.xml 中添加如下两项参数:
指定集群可以连接的用户,我这里设置为 root 用户。
假如我想指定用户名为 master,则配置项中的 root 必须改为 master,如:hadoop.proxyuser.master.hosts。
<!-- 设置集群的连接用户 --><property><name>hadoop.proxyuser.root.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.root.groups</name><value>*</value></property>
添加完成后注意分发该文件到其它机器,然后重启 Hadoop。
Hadoop 重启完成后,启动 hive 元数据服务与 hiveserver2 服务:
nohup hive --service metastore &nohup hive --service hiveserver2 &
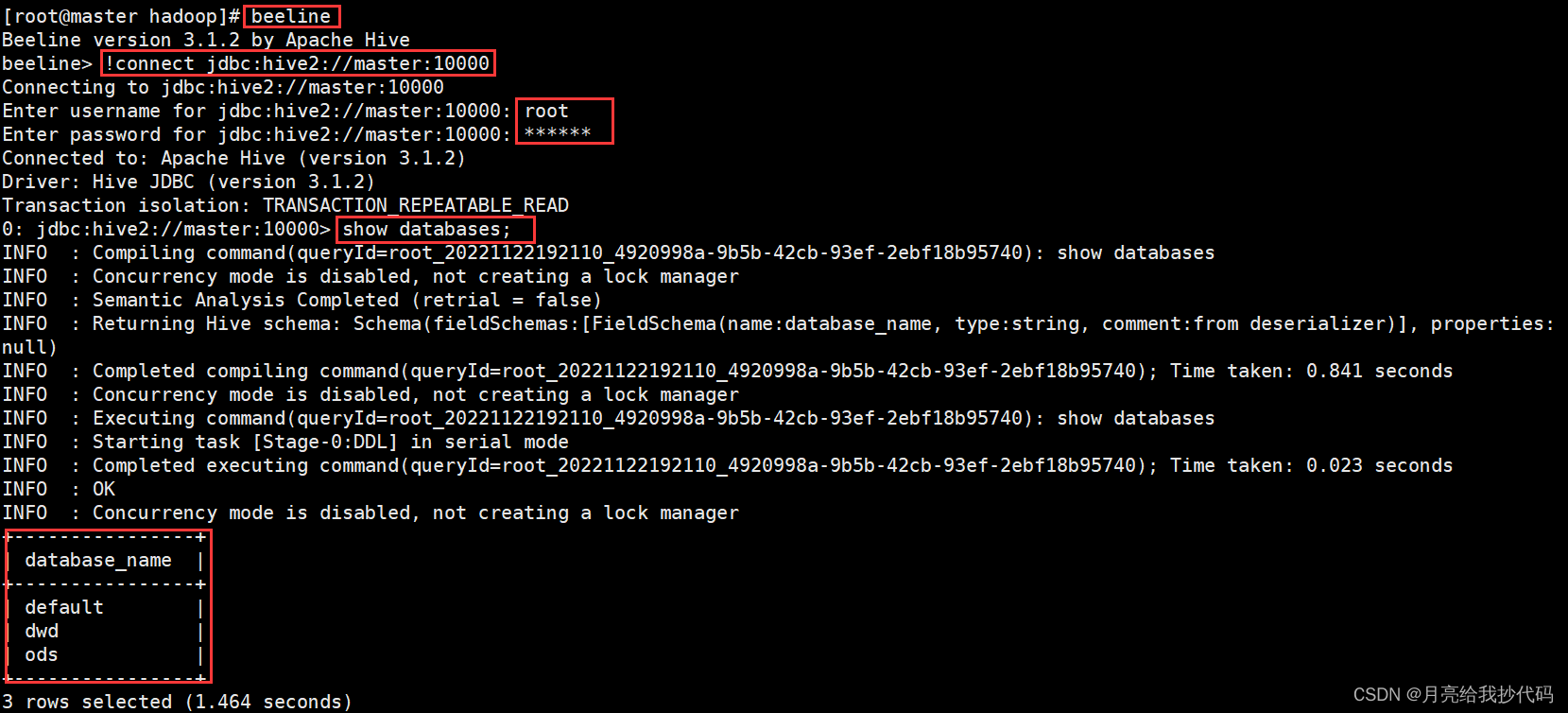
连接测试:
连接你绑定的地址并根据提示输入 Hive 的配置文件 hive-site.xml 中指定的用户与其密码。
beeline!connect jdbc:hive2://master:10000根据提示输入账号密码(默认都为空,直接按回车跳过即可)
下列是本人遇到的相关问题以及解决方法。
问题一
连接时出现错误:User: xxx is not allowed to impersonate anonymous (state=08S01,code=0),显示该用户不被允许连接,这是因为在 Hadoop 的核心配置文件 core-site.xml 中没有指定该用户(上方有添加用户模板)或者指定后 Hadoop 集群没有重启,导致配置没有生效。
问题二
如果你在通过 hiveserver2 服务远程插入数据时出现如下错误:FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.StatsTask
解决方法:
在插入的目标库中设置属性 set hive.stats.autogather=false;,关闭配置自动统计列的统计信息。
问题三
使用 HiveServer2 服务时异常停止,JVM 内存溢出:
FAILED: Execution Error, return code -101 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask. Java heap space Exception in thread "HiveServer2-Handler-Pool: Thread-652" java.lang.OutOfMemoryError: GC overhead limit exceeded
解决方法:
修改 Hive 中 conf 目录下的 hive-env.sh 文件,将 export HADOOP_HEAPSIZE=1024 进行调整,可以修改为 4096,视情况而定;

保存退出,重新启动服务就可以啦。
DataGrip 配置 HiveServer2 访问 Hive
1. 调出控制面板,创建连接:
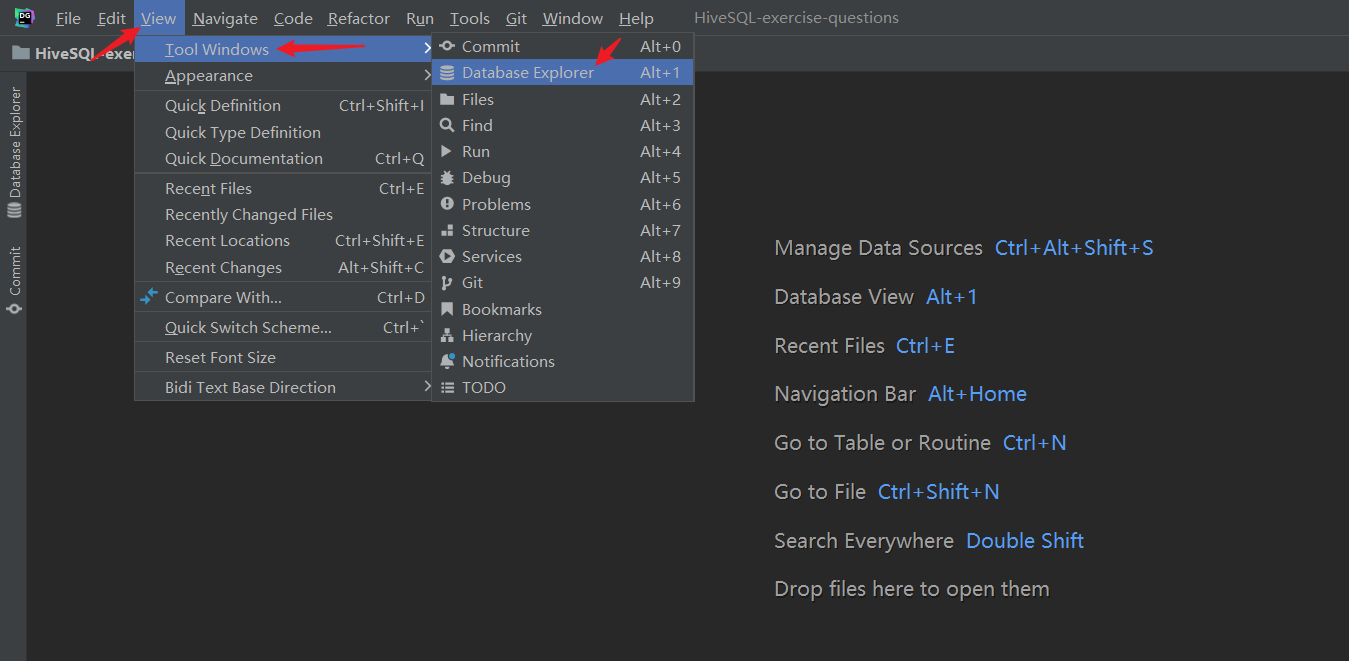
选择 Hive 数据源。
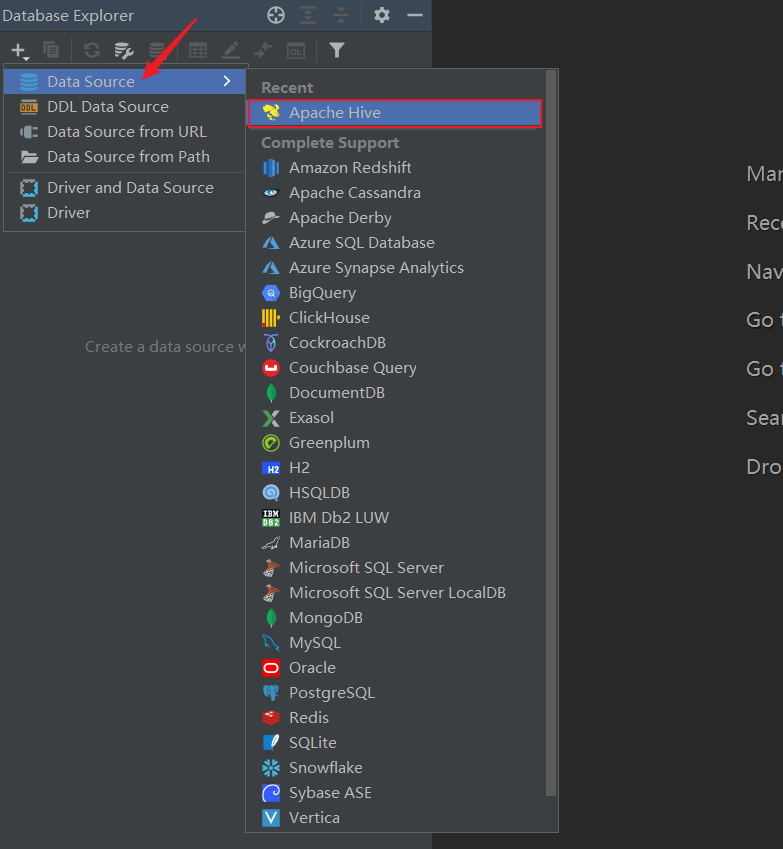
2.配置相关连接信息
账号密码如果没有设置则都为空,密码输入框为隐式显示。

点击 Test Connection 测试连接是否成功,然后下载集群 HiveServer2 远程连接 JDBC 对应驱动版本。
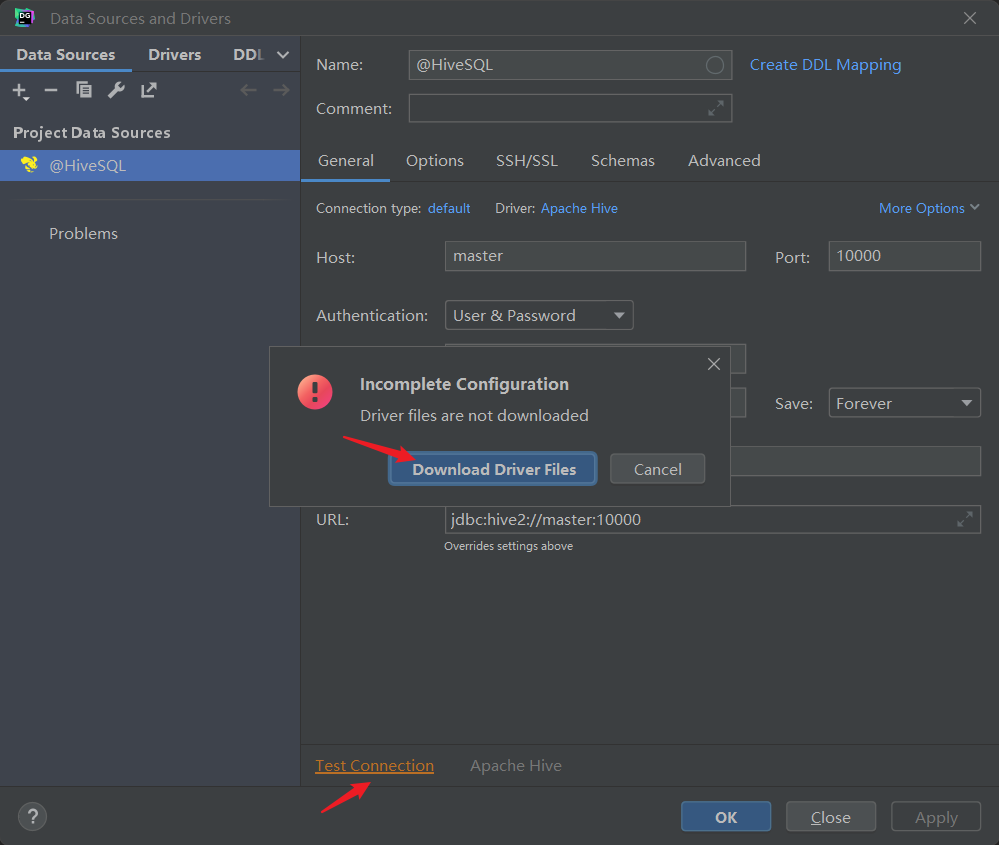
驱动下载完成后,弹出对应提示:
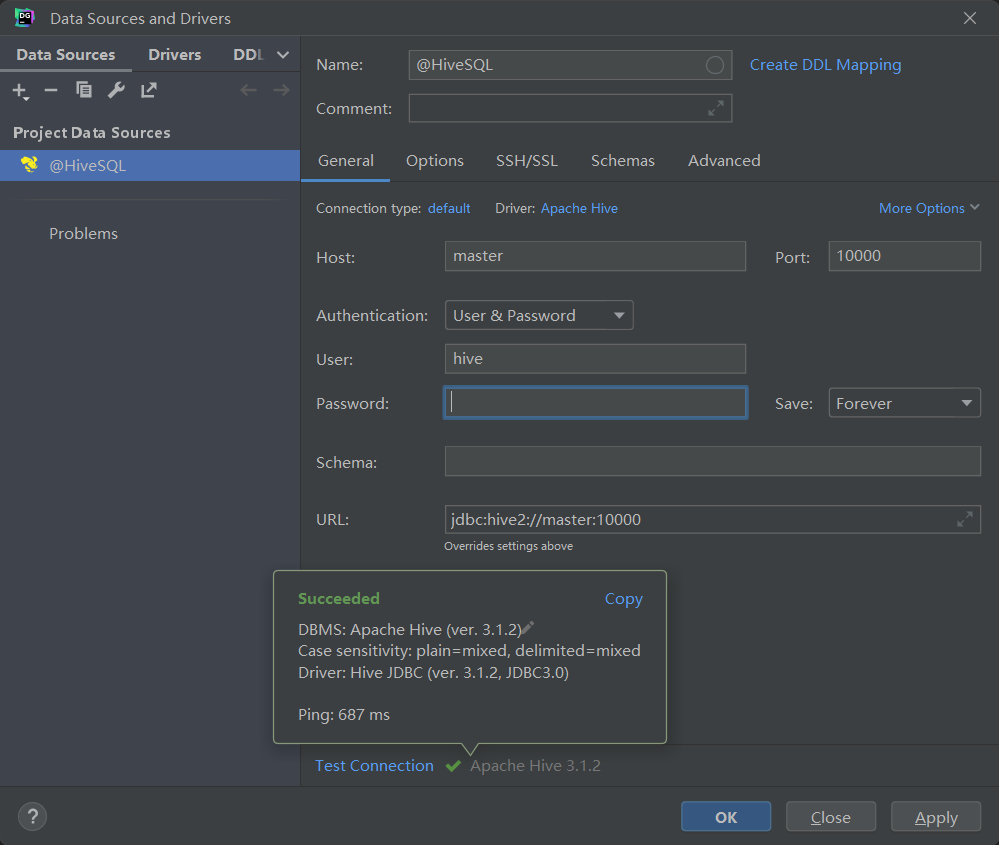
此时点击 OK 配置完成,可以发现驱动版本与集群是一致的。

3.使用
不做过多的赘述了,使用起来还是特别简单便捷的,没有啥难度可言。