基于Flask的模型部署
基于Flask的模型部署
一、背景
Flask:一个使用Python编写的轻量级Web应用程序框架;
首先需要明确模型部署的两种方式:在线和离线;
在线:就是将模型部署到类似于服务器上,调用需要通过网络传输数据,再将结果返回;
离线:就是将模型直接部署在终端设备上,不需要联网,数据传输上比较快;
二、Flask简单部署分类模型
通过一个实际的分类案例,来说明整个实现的流程;
首先Flask分为服务端和设备端,服务端就是接受数据并处理,应用端只负责发送数据和展示结果;
实现步骤:
------服务端-------
1、初始化Flask app
可以理解为初始化一个服务器对象;
app = flask.Flask(__name__)
2、加载模型
def load_model():global modelmodel = resnet50(pretrained=True) # 这里模型可以替换成自己的模型model.eval()if use_gpu:model.cuda()
这里是所有模型通用的,如果是一些模型需要将模型结构的代码和模型文件都准备好;
3、数据预处理
推理部分的数据处理应该与模型训练前的处理保持一致,否则可能导致结果出现较大偏差;
def prepare_image(image, target_size):if image.mode != 'RGB':image = image.convert("RGB") # 转换图像为RGB类型# 缩放图像image = T.Resize(target_size)(image)image = T.ToTensor()(image)# 归一化image = T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])(image)# 这里表示可以配置多个图像作为一个batchimage = image[None]if use_gpu:image = image.cuda() # 使用GPUreturn Variable(image, volatile=True) #不需要求导
上述的数据处理是最基本并且简单的数据处理,在很多任务中的数据预处理会复杂很多;
4、开启服务
# 注意这里的predict可以自行修改,但需要和后面的端口后缀保持一致
@app.route("/predict", methods=["POST"]) # 这里是python的装饰器
def predict():# 初始化一个返回列表,并且用一个变量表示是否调用成功data = {"success": False}# 确保传入数据为图像,并且将图像数据经过数据处理if flask.request.method == 'POST':if flask.request.files.get("image"): # 这里用于判断接受的对象# 读取图像数据image = flask.request.files["image"].read() # 读取实际路径image = Image.open(io.BytesIO(image)) #二进制数据# 数据预处理image = prepare_image(image, target_size=(224, 224))# 得到模型输出的结果,取出前K个结果preds = F.softmax(model(image), dim=1)results = torch.topk(preds.cpu().data, k=3, dim=1)results = (results[0].cpu().numpy(), results[1].cpu().numpy())# 结果保存到要传回的列表中data['predictions'] = list()# 根据标签值找到对应对象的实际类别for prob, label in zip(results[0][0], results[1][0]):label_name = idx2label[label]r = {"label": label_name, "probability": float(prob)}data['predictions'].append(r)# 设置返回列表调用成功data["success"] = True# 将数据转为json并返回return flask.jsonify(data)
这里是服务的具体执行程序,也就是接收数据和处理数据,并将结果返回;
这里可以做UI的可视化界面,本次只是演示效果就不进行设计;
执行该程序后,出现一个访问地址和端口号,如下图所示:

这里是部署到本地的服务器上,在实际工程中,一般是部署到一台公共服务器上,将服务开放为接口供但部分应用使用;
------应用端-------
1、初始化服务接口
PyTorch_REST_API_URL = 'http://127.0.0.1:5000/predict'
2、请求服务并展示结果
def predict_result(image_path):# 读取图像数据,保存到数组中image = open(image_path, 'rb').read()payload = {'image': image}# 请求服务r = requests.post(PyTorch_REST_API_URL, files=payload).json()# 确保服务返回成功if r['success']:# 遍历结果,并打印出来for (i, result) in enumerate(r['predictions']):print('{}. {}: {:.4f}'.format(i + 1, result['label'],result['probability']))# 如果服务请求失败,返回失败else:print('Request failed')
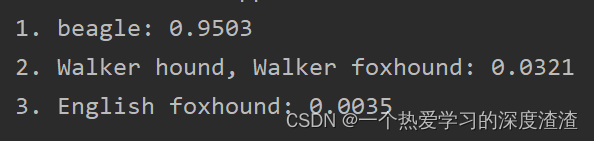
上面就是传入一张狗狗图像后打印的结果,可以看出服务能够正常运行;
总结:
虽然是一个简单的分类项目,但整体部署的流程以及一些代码的模板是不变的,换成别的任务可能会复杂一些,主要还是前后处理相对复杂一些,并且做UI界面的话也会相对复杂一些;