新版百度、百家号旋转验证码识别
昨天突然发现,百度旋转验证码发生了变化,导致使用老版本验证码训练出来的识别模型效果不佳。所有昨天花了一天时间完成了新版模型的训练。
老版本验证码

新版本验证码

新版的验证码感觉像是AI绘画随机生成的,还有随机阴影出现。
验证码识别过程
1、利用爬虫采集图像
首先我们开发爬虫去采集新版本的图片素材。爬取过程中发现cookie有一定的时效性,没有花过多时间在图片的反爬上做研究。

2、人工标记
为了保障识别的精度,这里需要进行大量的人工标记,旋转角度可能有误差,最好控制在1-2度以内,数据质量决定了模型预测效果
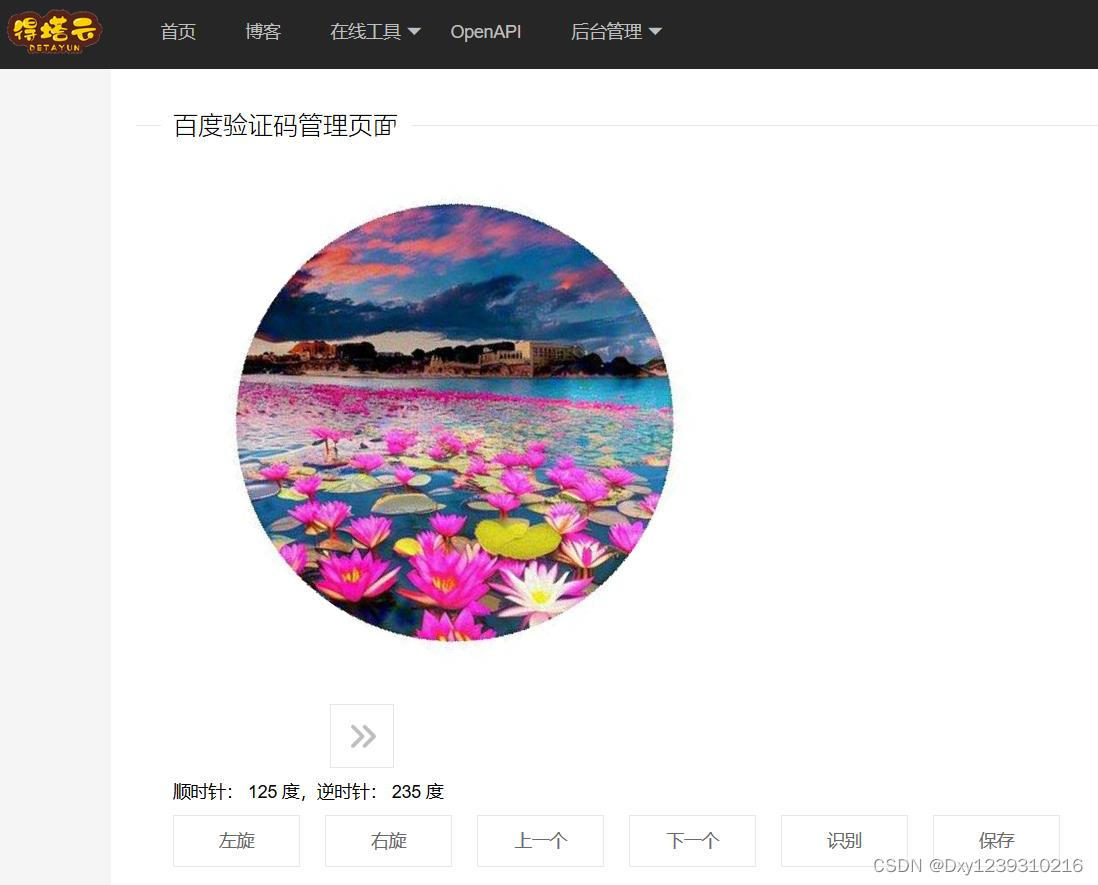
3、训练模型
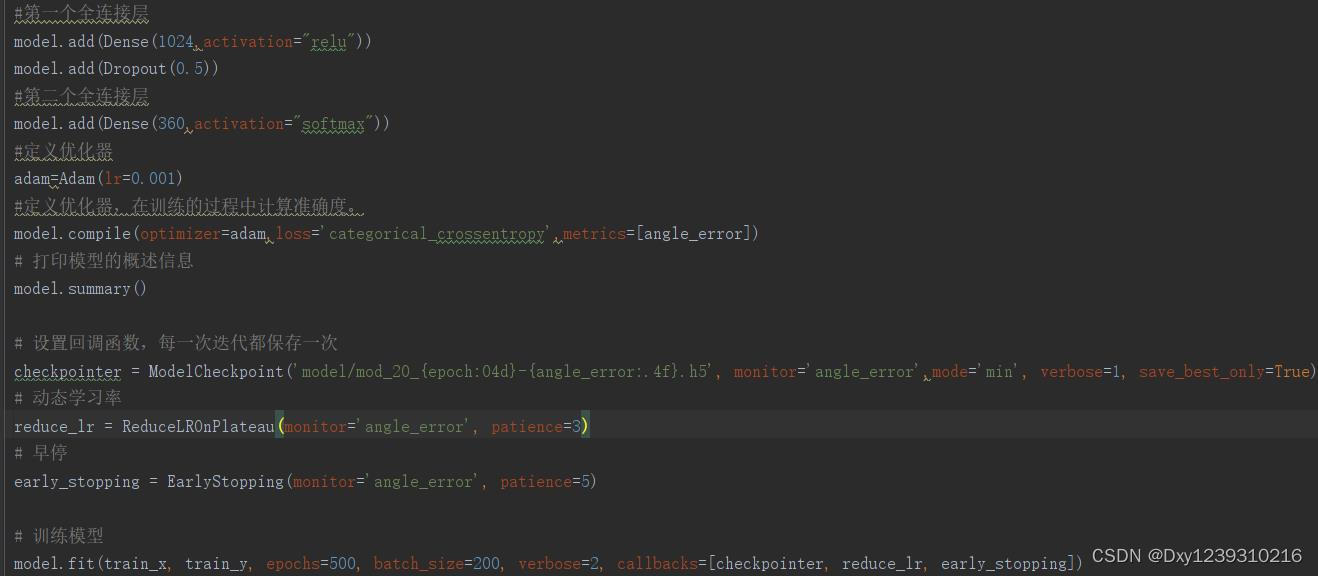
4、测试验证
我们将训练好的模型用100张图片来进行测试,虽然识别出来角度有所偏差,但是这个误差范围都能够使验证通过,所以正确率接近100%。因为100张测试图片比较少,所以保守估计正确率应该在99%左右。
如果再想提升正确率,可以再增加训练的数据量,就需要再投入大量人力,这个投入与提升产出比需要自己权衡。
5、免费使用地址
我将训练好的模型放在了网上,可以供大家免费学习使用:得塔云
6、总结分析
(1)目前见到的验证码图片可能是AI生成的,所以出现新图片的概率会很大,所以对标注、识别难度会大大增加。
(2)和老版本相比,新版本图像采集加入了一些反爬措施,也增加了一些难度。
(3)目前我没有使用 selenium 进行实战测试,可能会遇到更多反爬措施。
各位大神也请指出我的不足,或者有其他建议都可以给我留言,或私信我,谢谢指点。