pytorch零基础实现语义分割项目(一)——数据概况及预处理
语义分割之数据加载
- 项目列表
- 前言
- 数据集
- 概况
- 数据组织形式
- 数据集划分
- 数据预处理
- 均值与方差
- 结尾
项目列表
语义分割项目(一)——数据概况及预处理
语义分割项目(二)——标签转换与数据加载
语义分割项目(三)——语义分割模型(U-net和deeplavb3+)
前言
在本专栏的上一个项目中我们介绍了使用CNN进行图像分类,在本项目中我们将介绍另外一种对于图像进行处理的算法——语义分割
数据集
概况
我们这次使用的是来自kaggle的数据集
数据集地址:Semantic segmentation of aerial imagery
如果kaggle无法下载可以选择通过CSDN下载,已经设置了0积分可以下载
下载地址:用于语义分割的航拍数据集
他的类别信息如下:

数据的组织形式如下

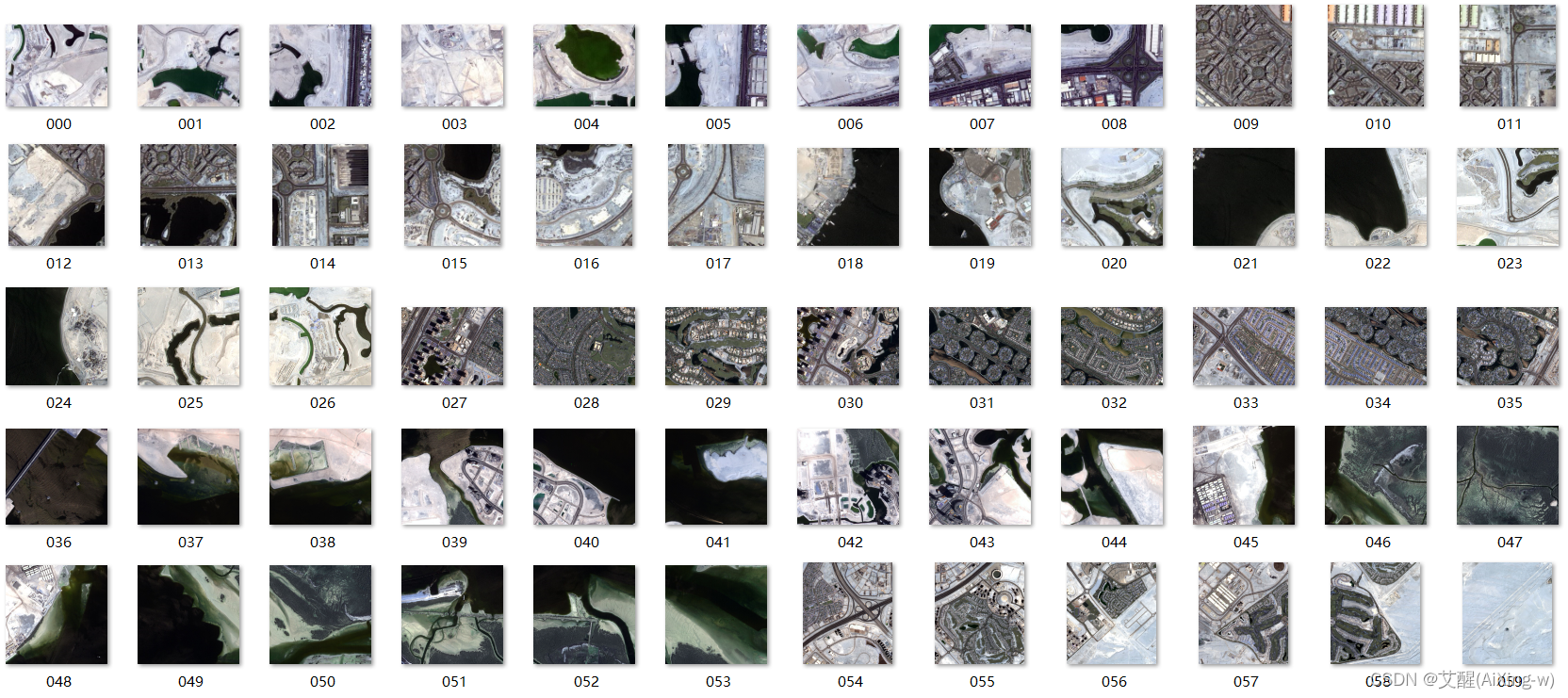
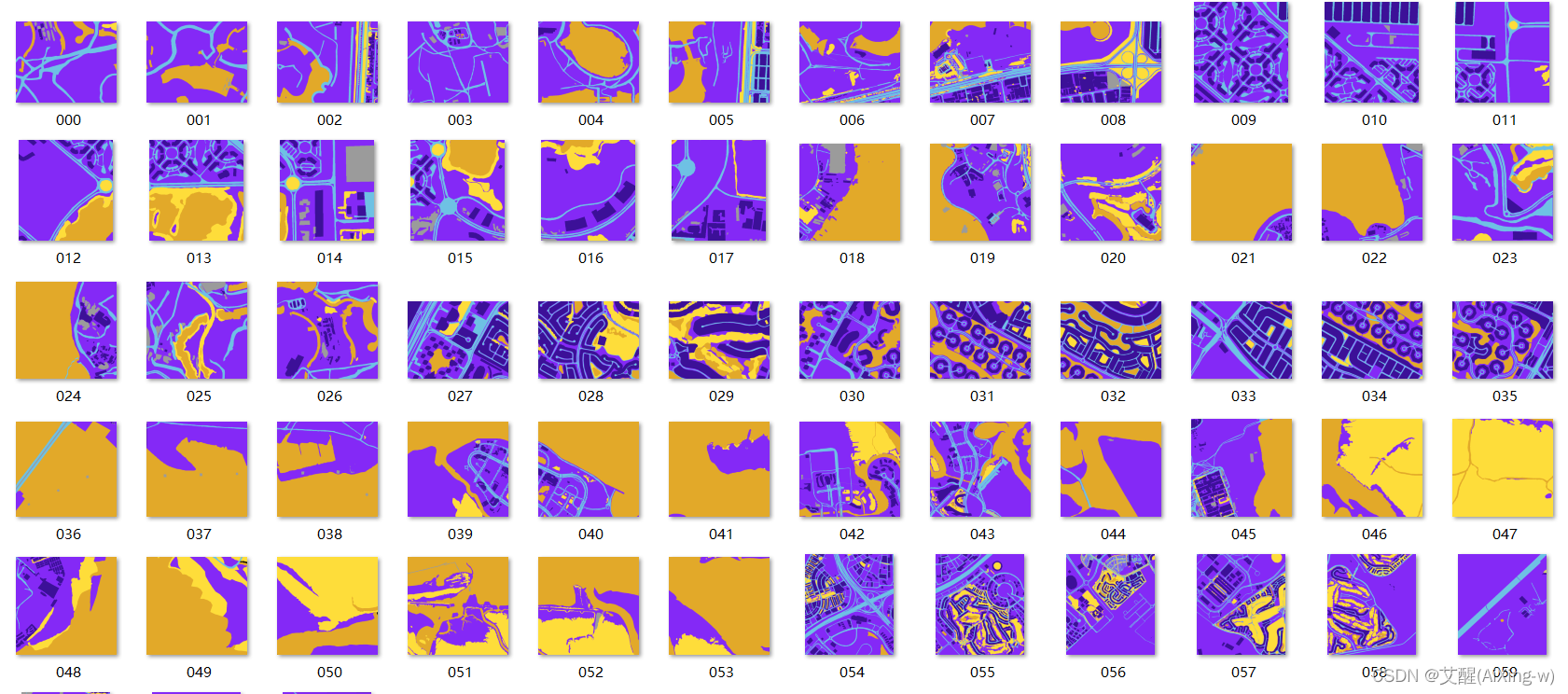
这里我们随便拿一张图片和分割后的结果做对比,可以看到,语义分割的目的就是将不同类别的区域分割出来


数据组织形式
由于数据的标签使用的16进制,为了方便,我们提前将16进制转换为rgb格式的标签形式,我们在下面直接列出像素点的颜色信息以及其对应的标签信息以备后续使用
VOC_COLORMAP = [[226, 169, 41], [132, 41, 246], [110, 193, 228], [60, 16, 152], [254, 221, 58], [155, 155, 155]]
VOC_CLASSES = ['Water', 'Land (unpaved area)', 'Road', 'Building', 'Vegetation', 'Unlabeled']
除此之外我们还可以看到数据集的组织形式似乎对于模型的训练有些不友好,因为我们想得到一个通用的数据加载和训练的代码,所以综合考虑来看我们选择提前处理数据而不是更改数据的加载部分的代码
def semantic2dataset():mark = 0path = 'Semantic segmentation dataset'if not os.path.exists('dataset'):os.mkdir('dataset')if not os.path.exists(os.path.join('dataset', 'images')):os.mkdir(os.path.join('dataset', 'images'))if not os.path.exists(os.path.join('dataset', 'labels')):os.mkdir(os.path.join('dataset', 'labels'))for i in range(1, 9):file = os.path.join(path, 'Tile {}'.format(i))images = os.path.join(file, 'images')masks = os.path.join(file, 'masks')for image, label in zip(os.listdir(images), os.listdir(masks)):shutil.copyfile(os.path.join(images, image), os.path.join('dataset', 'images', '{:03d}.jpg'.format(mark)))shutil.copyfile(os.path.join(masks, label), os.path.join('dataset', 'labels', '{:03d}.png'.format(mark)))mark += 1semantic2dataset()
我们通过os包新建文件夹,并且遍历原数据集的图片和标签,并将它们复制到我们新建的目录下,移动后的组织形式如下:
在dataset文件夹下只有images和labels两个文件夹

打开这两个文件夹我们可以看到图像和标签
数据集划分
我们首先要先划分训练集和测试集,代码很简单,依次读出数据的路径,并将路径写入到txt文件即可
def trainValSplit(path):length = len(os.listdir(os.path.join(path, 'images')))idx = [i for i in range(length)]shuffle(idx)with open(os.path.join(path, 'train.txt'), 'w') as f:for d in idx[:int(length * 0.8)]:f.write(str(d))f.write("\n")with open(os.path.join(path, 'test.txt'), 'w') as f:for d in idx[int(length * 0.8):]:f.write(str(d))f.write("\n")trainValSplit('./dataset')
txt文件中的内容如下
数据预处理
均值与方差
我们通过下面的函数可以获得数据集图像每个通道的均值和方差,我们只需要执行一次即可,得出的均值和方差将会作为先验数据为后续数据集加载过程中对于数据进行transforms处理的参数
def getMeanStd(path):length = len(os.listdir(path))means = torch.zeros(3)stds = torch.zeros(3)for name in os.listdir(path):img = io.read_image(os.path.join(path, name)).type(torch.float32) / 255for i in range(3):means[i] += img[i, :, :].mean()stds[i] += img[i, :, :].std()print(means.div_(length), stds.div_(length), length)getMeanStd('./dataset/images')

结尾
在本篇文章中,我们介绍了我们这个项目中用于进行语义分割的数据集的概况,以及针对其组织形式和数据上的预处理,下一篇我们将着重讲解数据集的加载