动态规划(用空间换时间的算法)原理逻辑代码超详细!参考自《算法导论》
动态规划(用空间换时间的算法)-实例说明和用法详解
- 动态规划(DP)思想
- 实例说明
- 钢条切割问题
- 矩阵链乘法问题
- 应用满足的条件和场景
本篇博客以《算法导论》第15章动态规划算法为本背景,大量引用书中内容和实例,并根据书中伪代码给出python代码复现,详解算法的核心逻辑和实现过程。
动态规划(DP)思想
动态规划(Dynamic Programming)算法的核心思想是:将大问题划分为重叠的子问题进行解决,从而一步步获取最优解的处理算法。
动态规划与分治方法相似,都是通过组合子问题的解来求解原问题(在这里“programming”指的是一种表格法,并非编写计算机序)。但是分治方法将问题划分为互不相交的子问题,递归地求解子问题,再将它们的解组合起来,求出原问题的解。与之相反,动态规划应用于子问题重叠的情况,即不同的子问题具有公共的子问题(子问题的求解是递归进行的,将其划分为更小的子子问题)。
在这种情况下,分治算法会做许多不必要的工作,它会反复地求解那些公共子子问题。而动态规划算法对每个子子问题只求解一次,将其解保存在一个表格中,从而无需每次求解一个子子问题时都重新计算,避免了这种不必要的计算工作。
实例说明
动态规划方法常用来求解最优化问题,下面分别给出二个例子来说明:第一个是将钢条割成短钢条,使得总价值最高;第二个是解决如何用最少的标量乘法操作完成一个矩阵链相乘的运算
钢条切割问题
下面是钢条切割问题的背景:

比如,下图给出长度为4英寸钢条所有可能的切割方案:
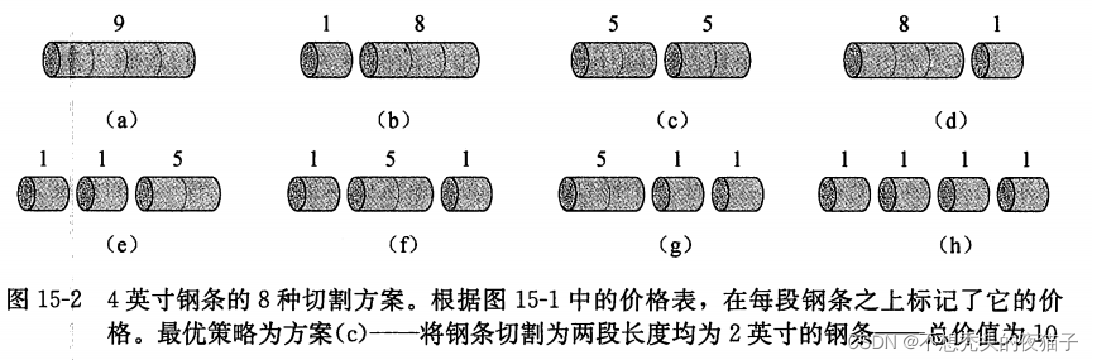
其中,钢条上方的数字为每段钢条对应的价格。不同的切割方案对应不同的价格,我们发现,将一段长度为4英寸的钢条切为两段各长2英寸的钢条,将产生 P 2 P_2 P2+ P 2 P_2 P2=5+5=10的收益,为最优解,即对应上图中的方案C。
下面我们逐步分析出钢条切割问题的最优收益的递推公式:

更为一般的收益公式,长度为n的钢条切割后的最大收益 r n r_n rn表示如下:

一种更简单的递归方法:

其中,(15.2)式中的 p i p_i pi指长度为i的钢条对应的价格,直接查表得到,不用再进行切割。
如果用传统的递归方法求解,一旦n的规模稍微变大,程序运行的时间会变得相当长,因为这种方法反复用相同的参数值对自身进行递归调用,即它反复求解相同的子问题。时间呈指数级增长。下图给出n=4时,递归树的调用过程:
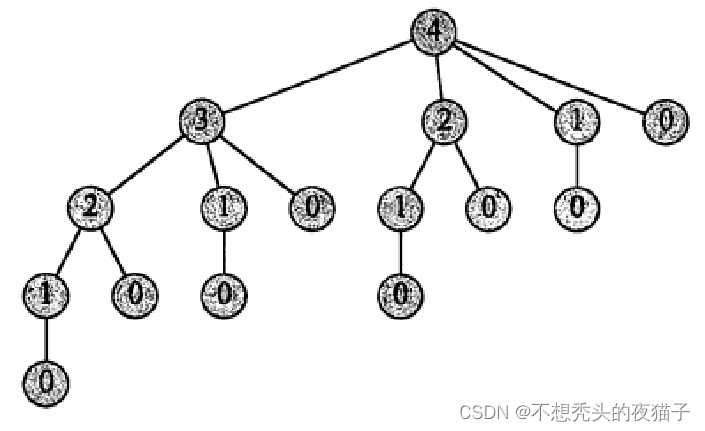
动态规划方法的运行时间是多项式阶的。

动态规划有两种等价的实现方法:

下面给出自底向上法的代码实现过程:

在上面的伪代码中,输入为两个变量,价格表数组和长度n;输出长度为n的钢条得到的最优收益。
下面计算长度为9时,钢条切割的最大收益:
import numpy as npdef Bottom_Up_Cut_Rod(p, n):r = []r.insert(0, 0)for j in range(1, n + 1):q = float('-inf')for i in range(1, j + 1):q = max(q, p[i - 1] + r[j - i])r.insert(j, q)return r[n]if __name__ == '__main__':# 出售长度为i(i=1,2,3,,,10)的钢条所对应的价格样表p = [1, 5, 8, 9, 10, 17, 17, 20, 24, 30]n = 9result = Bottom_Up_Cut_Rod(p, n)print("长度为{}时,".format(n))print("对应的最优收益值为{}。".format(result))
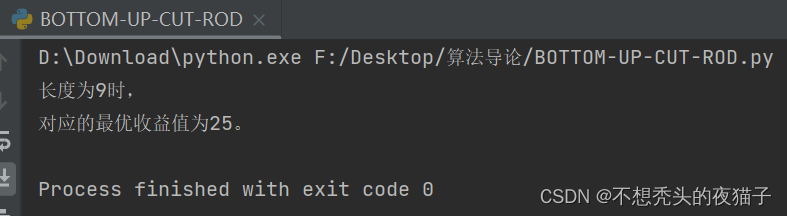
下图是长度为1、2、3…,对应的最优切割方案和收益。

思想:为了求解规模为 n 的原问题,我们先求解形式完全一样,但规模更小的子问题。即当完成首次切割后,我们将两段钢条看成两个独立的钢条切割问题实例。我们通过组合两个相关子问题的最优解,并在所有可能的两段切割方案中选取组合收益最大者,构成原问题的最优解。
我们称钢条切割问题满足最优子结构性质:问题的最优解由相关子问题的最优解组合而成,而这些子问题可以独立求解。
矩阵链乘法问题
矩阵链乘法问题即是多个矩阵相乘,找出最快计算次序的问题。

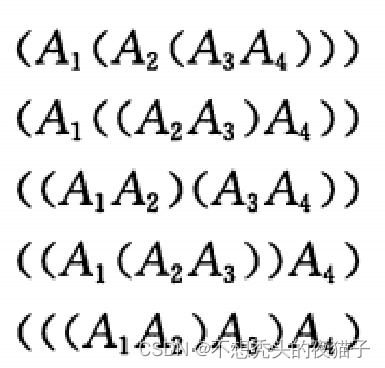
对矩阵链加括号的方式会对乘积运算的代价产生巨大影响,下面举例来说明:

因此,如果A是pXq的矩阵,B是qXr的矩阵,那么乘积 C是pXr的矩阵。计算 C所需时间由标量乘法的次数决定,即 pqr。下面我们将用标量乘法的次数来表示计算代价。

传统方法:穷举所有可能的括号化方案不会是一个高效的算法,因为它的运行时间仍然是指数级增长的。
下面定义矩阵链问题的计算代价公式,令m[i,j]表示计算矩阵 A i , . . . , j A_{i,...,j} Ai,...,j所需标量乘法次数的最小值。


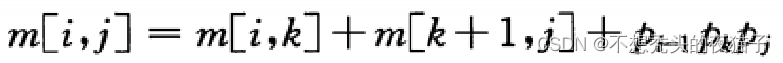
假设最优分割点k是未知的,则递归求解公式变为:
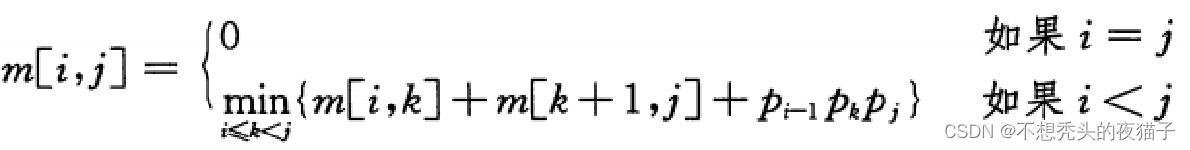
下面用一个例子来说明:

上图是我手写的一个例子,为了帮助理解。其中, A 1 A_1 A1:2 × \times × 3 ,表示 A 1 A_1 A1的维度为2行3列,P列表存放的是四个矩阵的维度,其中前一个矩阵的列数等于后一个矩阵的行数。要求出 A 1 A_1 A1 A 2 A_2 A2 A 3 A_3 A3 A 4 A_4 A4的计算代价,假设分割点k=2,则计算顺序为 ( ( A 1 A 2 ) ( A 3 A 4 ) ) ((A_1A_2)(A_3A_4)) ((A1A2)(A3A4))。其中, ( A 1 A 2 ) (A_1A_2) (A1A2)的计算代价对应上图中的矩阵C, ( A 3 A 4 ) (A_3A_4) (A3A4)的计算代价对应上图中的矩阵D,最后再令C与D相乘,算的最后的计算代价(总次数)为48。
下面给出的过程 MATRIX-CHAIN-ORDER实现了自底向上表格法:
各输入变量的含义如下:


输出变量为最优代价矩阵m和最优分割点矩阵k。
下面给出代码的计算过程帮助理解。假设n=4, p = [ p 0 , p 1 , p 2 , p 3 , p 4 ] p = [p_0,p_1,p_2,p_3,p_4] p=[p0,p1,p2,p3,p4],求 A 1 A 2 A 3 A 4 A_1A_2A_3A_4 A1A2A3A4的最优代价,即求m[1,4]。计算过程如下:


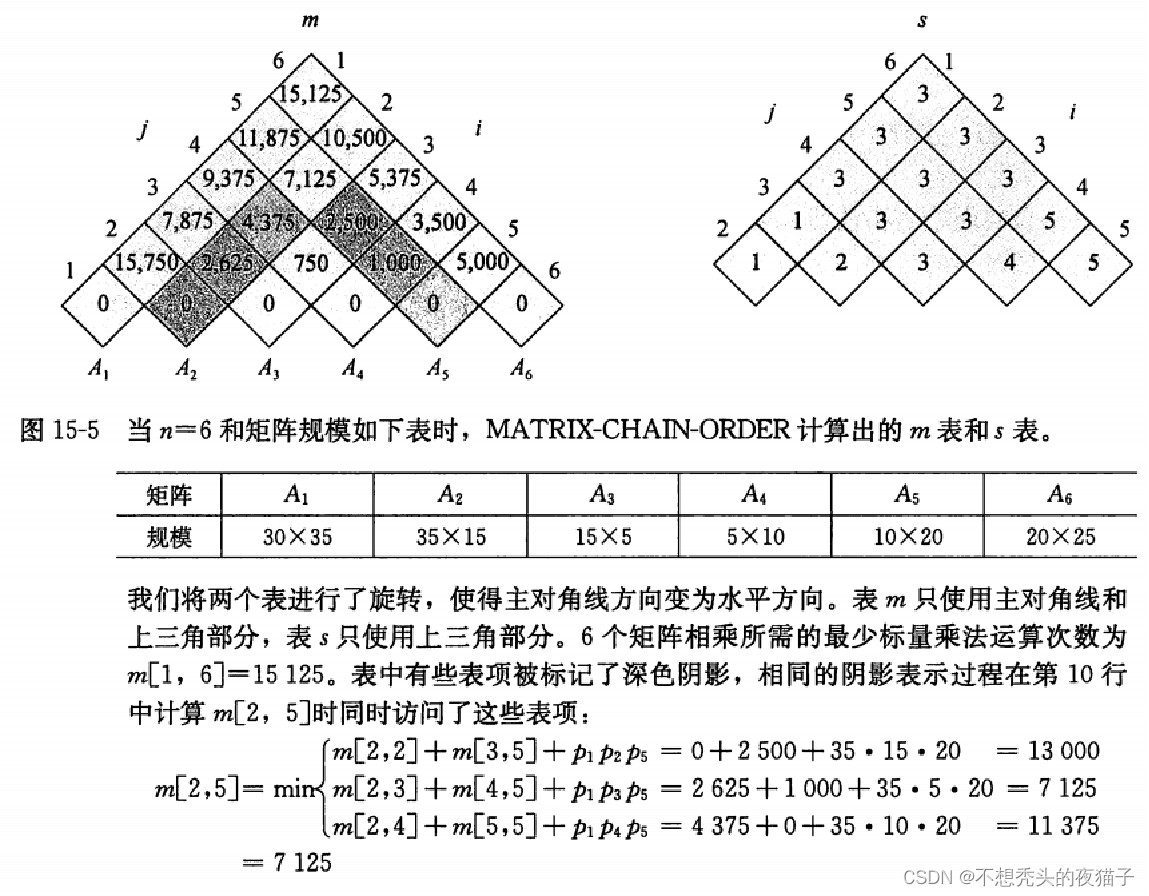
左边是最优代价矩阵,右边是最优分割点矩阵。
以图15-5的数据为例,python代码如下:
import numpy as npdef MATRIX_CHAIN_ORDER(p):n = len(p) - 1# 定义计算代价矩阵mm = np.zeros((n, n))# 定义最优分割点矩阵ss = np.zeros((n, n))for l in range(2, n + 1):for i in range(1, n - l + 2):j = i + l - 1m[i - 1, j - 1] = float('inf')for k in range(i, j):q = m[i - 1, k - 1] + m[k, j - 1] + p[i - 1] * p[k] * p[j]if q < m[i - 1, j - 1]:m[i - 1, j - 1] = qs[i - 1, j - 1] = kprint(m) # 每个元素对应长度为j-i+1的矩阵所需要最小计算代价print(s) # 对应长度为j-i+1的矩阵最优分割点return m, sif __name__ == '__main__':p = [30, 35, 15, 5, 10, 20, 25]MATRIX_CHAIN_ORDER(p)运行结果如下:
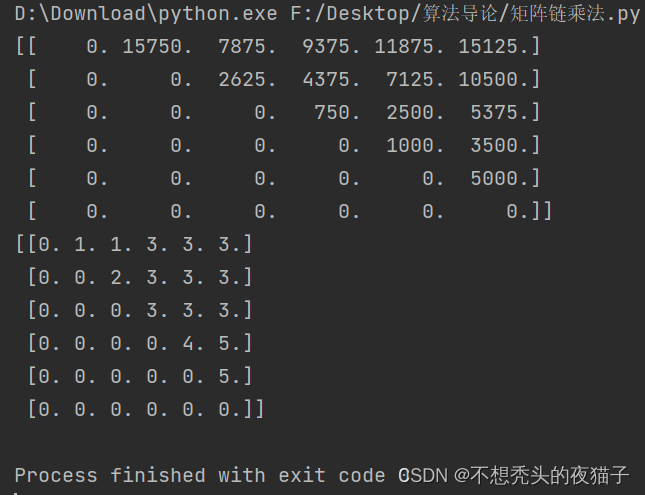
能够看出,跑出的结果与书上的两个矩阵完全相同。(只不过书中对矩阵沿主对角线方向进行了旋转)
思路:一个非平凡的矩阵链乘法问题实例的任何解都需要划分链,而任何最优解都是由子问题实例的最优解构成的。因此,为了构造一个矩阵链乘法问题实例的最优解,我们可以将问题划分为两个子问题( A i A i + 1 ⋅ ⋅ ⋅ A k A_iA_{i+1}···A_k AiAi+1⋅⋅⋅Ak和 A k + 1 ⋅ ⋅ ⋅ A j A_{k+1}···A_j Ak+1⋅⋅⋅Aj)子题实例的最优解,然后将子问题的最优解组合起来。我们必须保证在确定分割点时,已经考察了所有可能的划分点,这样就可以保证不会遗漏最优解。
应用满足的条件和场景
应用动态规划方法求解的最优化问题应该具备的两个要素:最优子结构和子问题重叠。


动态规划算法可以用来求解最优化问题,除了本文给出的两个例子外,常用的场景包括求解斐波那契数列,求解最长公共子序列、01背包问题和最优二叉搜索树等。想要深入了解该算法的原理和应用场景,具体可以阅读《算法导论》,我有电子版的,需要的兄弟姐妹可以私信我取。
综上所述,满足最优子结构和子问题重叠性质的问题可以利用动态规划思想建模,这种方法会开辟内存,存储以往的运算结果,再下次遇到时直接调用而不再重复计算,因此大大节省了时间,是一种经典的用空间换时间的算法,而大多数情况下,项目对时间的要求往往更严格,相比对内存的占用情况就宽松很多了。