Storm学习之使用官方Docker镜像快速搭建Storm运行环境
文章目录
- 0.前言
- 搭建完的效果
- 1.教程
- 1.1.docker 安装 zookeeper
- 1.2. 安装 storm nimbus
- 1.3.docker 安装 supervisor
- 1.4.docker 安装 storm-ui
- 1.5.查看已经启动的容器
- 1.6.提交topology到 storm集群
- 2.总结
- 3.参考文档
0.前言
Apache Storm 官方也出了Docker 镜像 https://hub.docker.com/_/storm/
本文我们就基于官方镜像搭建一个 Apache Storm 2.4 版本的运行环境,供大家后续学习。
有问题可以参考issue 解决,我的安装过程一路都很顺畅。所以基本上没有看下面是我的详细操作和截图。
可以说网上的乱七八糟的教程不如官方文档来的实在。
如果想用虚拟机搭建,请参考我的上一篇文章《Centos7搭建Apache Storm 集群运行环境》
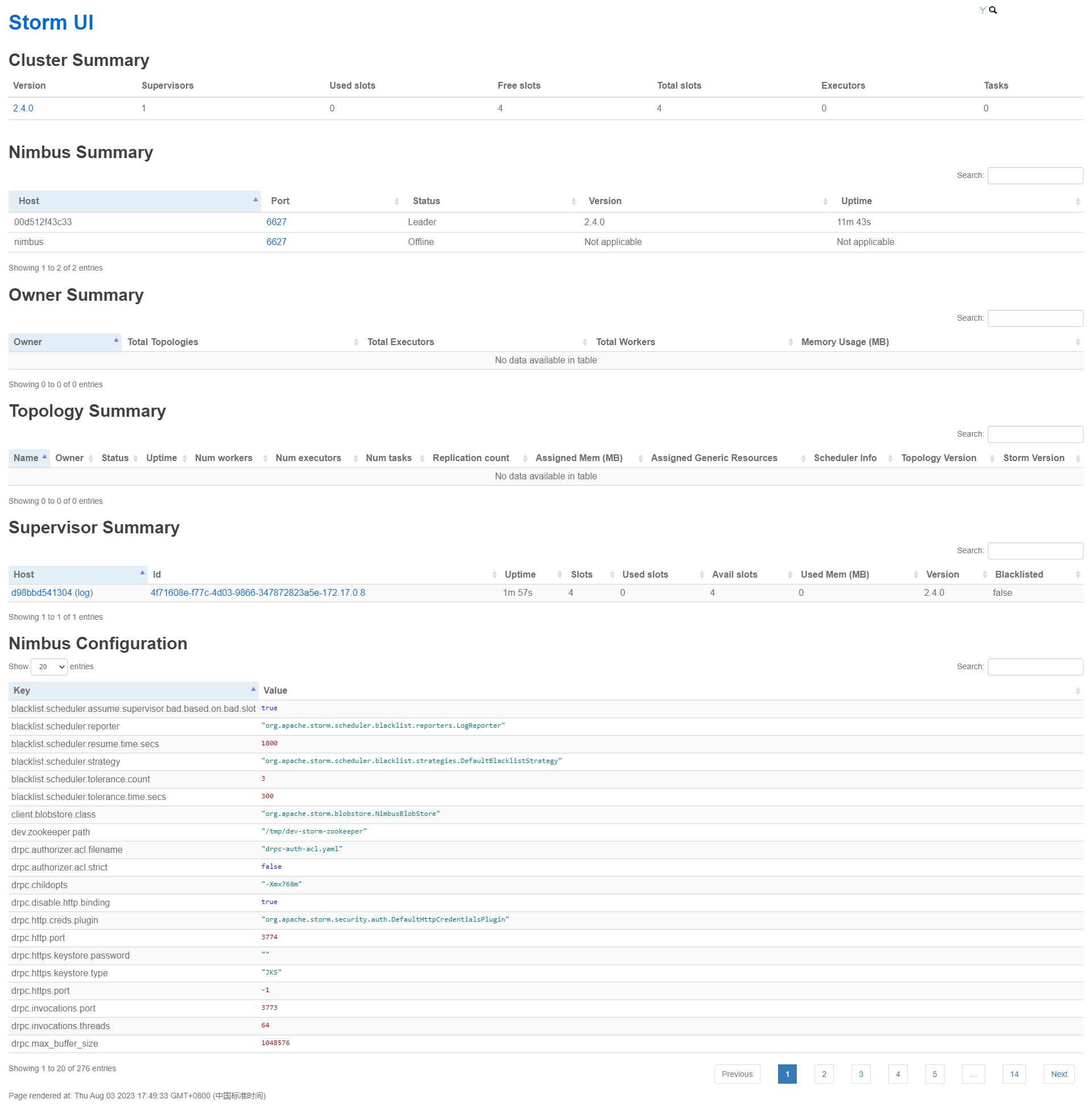
搭建完的效果
Storm UI虽然是Storm 的非必须组件,但是是非常有用,基本上离不开的组件,它可以展示很多信息,对我们平时排查问题很有帮助,
-
拓扑列表:显示当前在Storm集群中运行的所有拓扑的列表。每个拓扑通常会显示其名称、ID、状态和所属的用户。
-
拓扑摘要:提供了关于选定拓扑的详细信息,包括拓扑的名称、ID、状态、拓扑图和组件列表。还可能包括拓扑的启动时间、运行时长和错误信息。
-
组件视图:显示了拓扑中的各个组件及其实例的信息。对于每个组件,它通常会显示组件的ID、类型、输入输出流以及处理该组件的工作进程和任务数量。
-
工作进程视图:提供有关工作进程的详细信息,包括工作进程的ID、主机名、端口号、启动时间、堆内存使用情况、线程数等。
-
任务视图:显示有关任务的信息,包括任务的ID、工作进程、组件、执行状态、错误信息等。可以查看每个任务的日志和统计数据。
-
错误视图:列出了拓扑中发生的任何错误或异常。这包括组件的失败、任务的错误、工作进程的故障等。通常会显示错误的时间戳、类型和详细描述。
-
日志视图:显示了拓扑中各个组件和任务的日志输出。可以查看实时日志或按时间范围过滤日志。
-
统计视图:提供了关于拓扑的性能统计数据。这可能包括拓扑的吞吐量、处理延迟、执行时间、错误计数等指标的图表或表格。
-
配置视图:显示了拓扑的配置参数和属性。可以查看拓扑使用的配置文件以及运行时配置的值。
-
集群概述:提供了有关整个Storm集群的概览信息,包括集群状态、拓扑数量、工作进程数量、任务数量等。
请注意,具体的Storm UI页面内容可能会根据不同的版本和配置有所变化,上述内容仅为一般情况下的解释。
1.教程
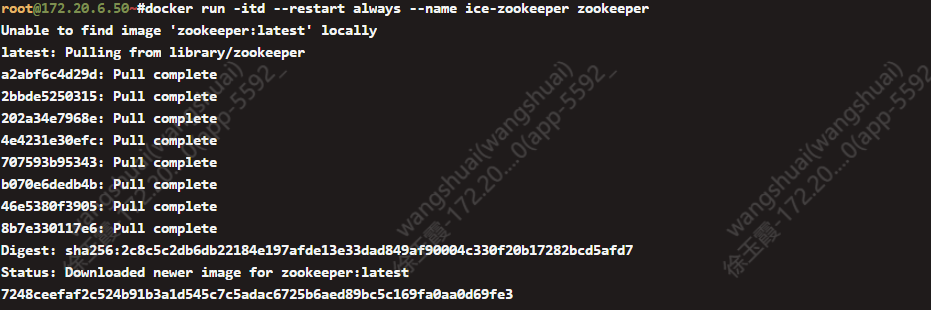
1.1.docker 安装 zookeeper
我们选择最新版本的zookeeper
$ docker run -itd --restart always --name ice-zookeeper zookeeper
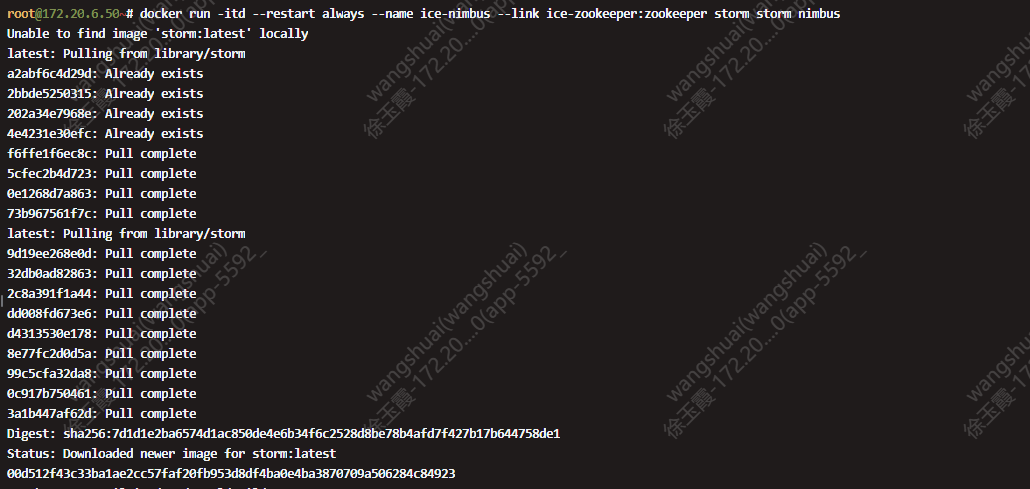
1.2. 安装 storm nimbus
创建一个名为ice-nimbus的容器,并在其中运行Storm的Nimbus组件。该容器将与一个名为ice-zookeeper的Zookeeper容器相链接,以便Storm Nimbus可以与Zookeeper进行通信。
这一步耗时稍微较长,需要下载镜像。
$ docker run -itd --restart always --name ice-nimbus --link ice-zookeeper:zookeeper storm storm nimbus
1.3.docker 安装 supervisor
创建一个名为ice-supervisor的容器,并在其中运行Storm的Supervisor组件。该容器将与一个名为ice-zookeeper的Zookeeper容器和一个名为ice-nimbus的Nimbus容器相链接,以便Storm Supervisor可以与Zookeeper和Nimbus进行通信。通过--restart always选项,当容器退出时,Docker将自动重新启动该容器,确保Supervisor组件一直处于运行状态。
$ docker run -d --restart always --name ice-supervisor --link ice-zookeeper:zookeeper --link ice-nimbus:nimbus storm storm supervisor

1.4.docker 安装 storm-ui
$ docker run -d -p 8980:8080 --restart always --name ui --link ice-nimbus:nimbus storm storm ui

1.5.查看已经启动的容器
docker ps -a

1.6.提交topology到 storm集群
$ docker run --link ice-nimbus:nimbus -it --rm -v $(pwd)/topology.jar:/topology.jar storm storm jar /topology.jar org.apache.storm.starter.WordCountTopology topology

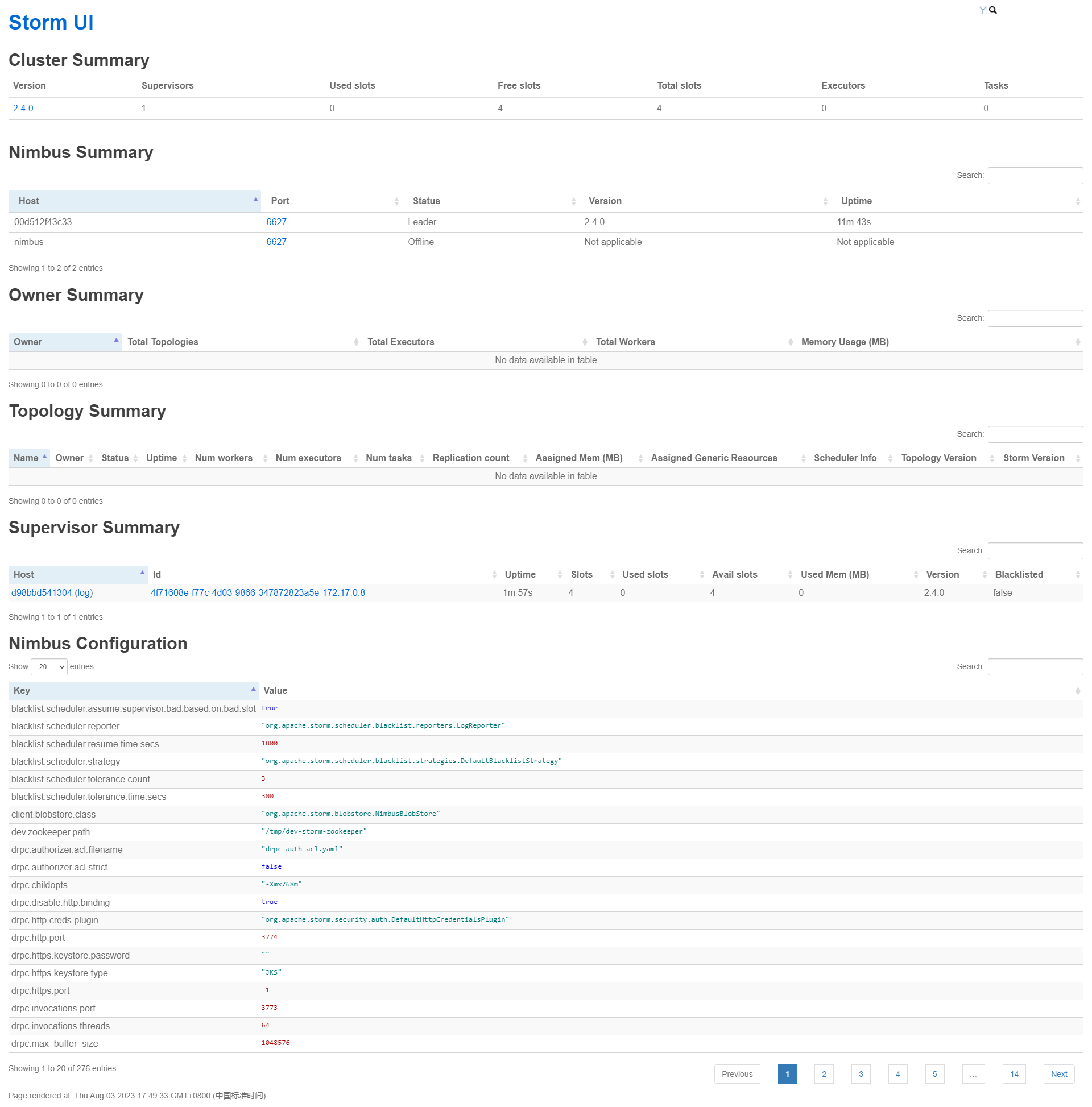
我们可以在StormUI的最后面看到 Nimbus配置参数:
-
worker.profiler.enabled: 是否启用工作进程的性能分析器。在给定的配置中,该值为false,表示禁用性能分析器。 -
worker.profiler.command: 用于启动性能分析器的命令。在给定的配置中,命令为"flight.bash"。 -
worker.profiler.childopts: 传递给性能分析器的JVM参数。在给定的配置中,参数为"-XX:+UnlockCommercialFeatures -XX:+FlightRecorder",用于解锁商业特性并启用Flight Recorder。 -
worker.metrics: 工作进程的度量指标配置。提供了一组度量指标的名称和相应的类。在给定的配置中,包括CGroup内存使用、CGroup内存限制、CGroup CPU使用、CGroup CPU保证等度量指标。 -
worker.max.timeout.secs: 工作进程的最大超时时间,以秒为单位。在给定的配置中,超时时间为600秒。 -
worker.log.level.reset.poll.secs: 重新设置工作进程日志级别的轮询间隔,以秒为单位。在给定的配置中,轮询间隔为30秒。 -
worker.heartbeat.frequency.secs: 工作进程发送心跳的频率,以秒为单位。在给定的配置中,心跳频率为1秒。 -
worker.heap.memory.mb: 工作进程的堆内存大小,以MB为单位。在给定的配置中,堆内存大小为768MB。 -
worker.gc.childopts: 传递给垃圾收集器的JVM参数。在给定的配置中,参数为空字符串,表示没有额外的垃圾收集器参数。 -
worker.childopts: 工作进程的启动选项,包括JVM参数。在给定的配置中,包括一些JVM参数,例如堆内存大小、GC日志的输出路径和格式、堆外内存溢出时的堆转储等。 -
ui.port: Storm UI的端口号。在给定的配置中,端口号为8080。 -
ui.childopts: Storm UI的启动选项,包括JVM参数。在给定的配置中,只指定了最大堆内存大小为768MB。 -
topology.workers: 拓扑的工作进程数。在给定的配置中,工作进程数为1,表示拓扑将在一个工作进程中执行。 -
topology.worker.shared.thread.pool.size: 拓扑工作进程共享线程池的大小。在给定的配置中,线程池大小为4。 -
topology.worker.receiver.thread.count: 拓扑工作进程接收器线程的数量。在给定的配置中,接收器线程数为1。 -
topology.worker.max.heap.size.mb: 拓扑工作进程的最大堆内存大小,以MB为单位。在给定的配置中,最大堆内存大小为768MB。 -
topology.worker.logwriter.childopts: 拓扑工作进程日志写入器的启动选项,包括JVM参数。在给定的配置中,只指定了最大堆内存大小为64MB。 -
topology.tuple.serializer: 拓扑元组的序列化器。在给定的配置中,序列化器为"org.apache.storm.serialization.types.ListDelegateSerializer"。 -
topology.trident.batch.emit.interval.millis: Trident拓扑批量发射间隔的时间间隔,以毫秒为单位。在给定的配置中,间隔为500毫秒。 -
topology.transfer.buffer.size: 拓扑传输缓冲区的大小。在给定的配置中,缓冲区大小为1000。 -
topology.transfer.batch.size: 拓扑传输批量大小。在给定的配置中,批量大小为1。 -
topology.stats.sample.rate: 拓扑配置项解释: -
worker.profiler.enabled: 是否启用工作进程的性能分析器。在给定的配置中,该值为false,表示禁用性能分析器。 -
worker.profiler.command: 用于启动性能分析器的命令。在给定的配置中,命令为"flight.bash"。 -
worker.profiler.childopts: 传递给性能分析器的JVM参数。在给定的配置中,参数为"-XX:+UnlockCommercialFeatures -XX:+FlightRecorder",用于解锁商业特性并启用Flight Recorder。 -
worker.metrics: 工作进程的度量指标配置。提供了一组度量指标的名称和相应的类。在给定的配置中,包括CGroup内存使用、CGroup内存限制、CGroup CPU使用、CGroup CPU保证等度量指标。 -
worker.max.timeout.secs: 工作进程的最大超时时间,以秒为单位。在给定的配置中,超时时间为600秒。 -
worker.log.level.reset.poll.secs: 重新设置工作进程日志级别的轮询间隔,以秒为单位。在给定的配置中,轮询间隔为30秒。 -
worker.heartbeat.frequency.secs: 工作进程发送心跳的频率,以秒为单位。在给定的配置中,心跳频率为1秒。 -
worker.heap.memory.mb: 工作进程的堆内存大小,以MB为单位。在给定的配置中,堆内存大小为768MB。 -
worker.gc.childopts: 传递给垃圾收集器的JVM参数。在给定的配置中,参数为空字符串,表示没有额外的垃圾收集器参数。 -
worker.childopts: 工作进程的启动选项,包括JVM参数。在给定的配置中,包括一些JVM参数,例如堆内存大小、GC日志的输出路径和格式、堆外内存溢出时的堆转储等。 -
ui.port: Storm UI的端口号。在给定的配置中,端口号为8080。 -
ui.childopts: Storm UI的启动选项,包括JVM参数。在给定的配置中,只指定了最大堆内存大小为768MB。 -
topology.workers: 拓扑的工作进程数。在给定的配置中,工作进程数为1,表示拓扑将在一个工作进程中执行。 -
topology.worker.shared.thread.pool.size: 拓扑工作进程共享线程池的大小。在给定的配置中,线程池大小为4。 -
topology.worker.receiver.thread.count: 拓扑工作进程接收器线程的数量。在给定的配置中,接收器线程数为1。 -
topology.worker.max.heap.size.mb: 拓扑工作进程的最大堆内存大小,以MB为单位。在给定的配置中,最大堆内存大小为768MB。 -
topology.worker.logwriter.childopts: 拓扑工作进程日志写入器的启动选项,包括JVM参数。在给定的配置中,只指定了最大堆内存大小为64MB。 -
topology.tuple.serializer: 拓扑元组的序列化器。在给定的配置中,序列化器为"org.apache.storm.serialization.types.ListDelegateSerializer"。 -
topology.trident.batch.emit.interval.millis: Trident拓扑批量发射间隔的时间间隔,以毫秒为单位。在给定的配置中,间隔为500毫秒。 -
topology.transfer.buffer.size: 拓扑传输缓冲区的大小。在给定的配置中,缓冲区大小为1000。 -
topology.transfer.batch.size: 拓扑传输批量大小。在给定的配置中,批量大小为1。 -
topology.stats.sample.rate: 拓扑统计信息的
2.总结
本次我们将storm 使用docker 搭建了运行环境,下个章节,我们使用这个运行环境来运行我们拓扑。写一个最简单的 world count。本次我们就先到这里,大家如果需要继续可以开始写拓扑,尝试自己提交运行。
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;public class WordCountTopology {public static void main(String[] args) {// 创建TopologyBuilder实例TopologyBuilder builder = new TopologyBuilder();// 定义spout(数据源)和bolt(数据处理器)的名称和任务并行度builder.setSpout("word-reader", new WordReaderSpout(), 1);builder.setBolt("word-normalizer", new WordNormalizerBolt(), 2).shuffleGrouping("word-reader");builder.setBolt("word-counter", new WordCounterBolt(), 2).fieldsGrouping("word-normalizer", new Fields("word"));// 创建配置对象并设置一些参数Config config = new Config();config.put("inputFile", "input.txt");config.setDebug(true);// 在本地模式下运行拓扑LocalCluster cluster = new LocalCluster();cluster.submitTopology("word-count-topology", config, builder.createTopology());// 等待一段时间后停止拓扑Utils.sleep(5000);cluster.killTopology("word-count-topology");cluster.shutdown();}
}
3.参考文档
- docker hub storm https://hub.docker.com/_/storm
- Storm 社区 https://github.com/31z4/storm-docker