ONNXRUNTUIME实例分割网络说明
-
ONNXRUNTUIME c++使用(分割网络)与相关资料(暂记)
-
initiate a env with an id name(使用id名称启动env)
-
create session (创建会话 )
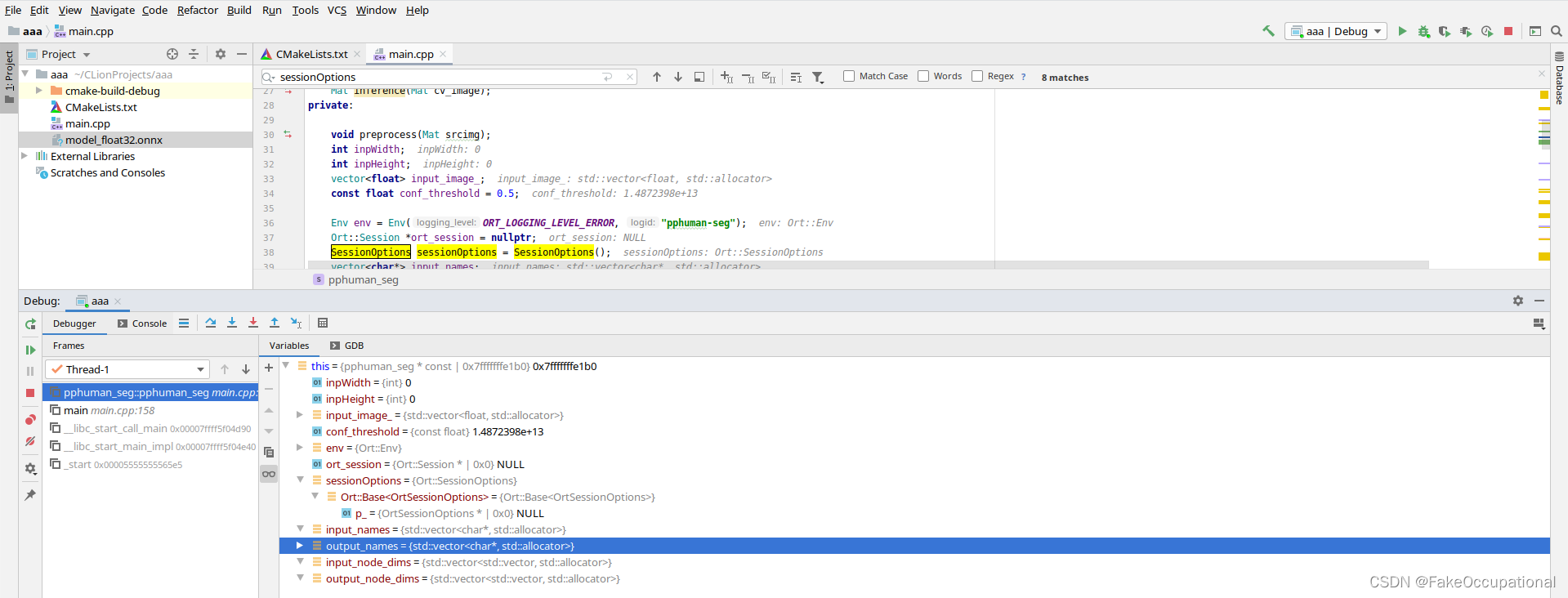
- onnx+env -> session
- inputname = [“x”] ,outputname = [“t”]
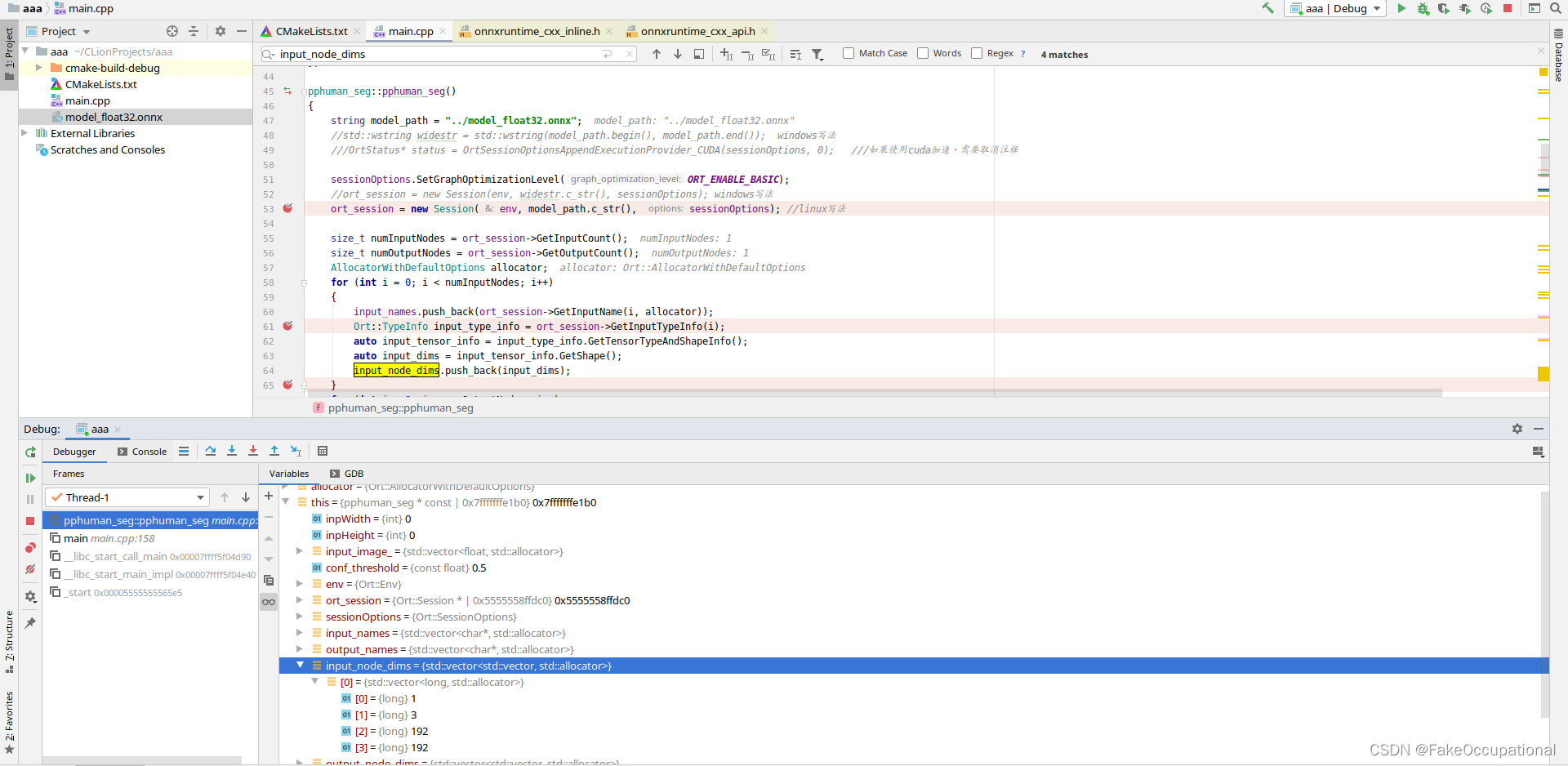
- inputnodedim = [[1,1,192,192]] , outputnodedim = [[1,192,192,2]]
推理 Mat dstimg = mynet.inference(frame);
预处理 (srcimg序列化到this->input_image_)
void pphuman_seg::preprocess(Mat srcimg)// srcimg cv::Mat 3,800,1920
{Mat dstimg;resize(srcimg, dstimg, Size(this->inpWidth, this->inpHeight), INTER_LINEAR);// resizeint row = dstimg.rows;int col = dstimg.cols;this->input_image_.resize(row * col * dstimg.channels());// vector<float> 变成row * col * 3大小for (int c = 0; c < 3; c++)// 序列化{for (int i = 0; i < row; i++){for (int j = 0; j < col; j++){float pix = dstimg.ptr<uchar>(i)[j * 3 + c];// uchar* data = image.ptr<uchar>(i);this->input_image_[c * row * col + i * col + j] = (pix / 255.0 - 0.5) / 0.5;}}}
}
前向传播
-
Value input_tensor_ = Value::CreateTensor<float>(allocator_info, input_image_.data(), input_image_.size(), input_shape_.data(), input_shape_.size()); -
vector<Value> ort_outputs = ort_session->Run(RunOptions{ nullptr }, input_names.data(), &input_tensor_, 1, output_names.data(), output_names.size());
后处理
Value对象 Value &mask_pred = ort_outputs.at(0);
struct Value : Base<OrtValue> {// This structure is used to feed sparse tensor values// information for use with FillSparseTensor<Format>() API// if the data type for the sparse tensor values is numeric// use data.p_data, otherwise, use data.str pointer to feed// values. data.str is an array of const char* that are zero terminated.// number of strings in the array must match shape size.// For fully sparse tensors use shape {0} and set p_data/str// to nullptr.struct OrtSparseValuesParam {const int64_t* values_shape;size_t values_shape_len;union {const void* p_data;const char** str;} data;};// Provides a way to pass shape in a single// argumentstruct Shape {const int64_t* shape;size_t shape_len;};
转为 Mat mask_out(out_h, out_w, CV_32FC2, mask_ptr);
CV_32FC2 应该是32Float 2 通道
/** @overload@param rows Number of rows in a 2D array.@param cols Number of columns in a 2D array.@param type Array type. Use CV_8UC1, ..., CV_64FC4 to create 1-4 channel matrices, orCV_8UC(n), ..., CV_64FC(n) to create multi-channel (up to CV_CN_MAX channels) matrices.@param s An optional value to initialize each matrix element with. To set all the matrix elements tothe particular value after the construction, use the assignment operatorMat::operator=(const Scalar& value) .*/Mat(int rows, int cols, int type, const Scalar& s);
结果展示
for (int h = 0; h < srcimg.rows; h++){for (int w = 0; w < srcimg.cols; w++){float pix = segmentation_map.ptr<float>(h)[w * 2];if (pix > this->conf_threshold){float b = (float)srcimg.at<Vec3b>(h, w)[0];dstimg.at<Vec3b>(h, w)[0] = uchar(b * 0.5 + 1);float g = (float)srcimg.at<Vec3b>(h, w)[1];dstimg.at<Vec3b>(h, w)[1] = uchar(g * 0.5 + 1);float r = (float)srcimg.at<Vec3b>(h, w)[2];dstimg.at<Vec3b>(h, w)[2] = uchar(r * 0.5 + 1);}}}for (int h = 0; h < srcimg.rows; h++){for (int w = 0; w < srcimg.cols; w++){float pix = segmentation_map.ptr<float>(h)[w * 2 + 1];if (pix > this->conf_threshold){float b = (float)dstimg.at<Vec3b>(h, w)[0];dstimg.at<Vec3b>(h, w)[0] = uchar(b * 0.5 + 1);float g = (float)dstimg.at<Vec3b>(h, w)[1] + 255.0;dstimg.at<Vec3b>(h, w)[1] = uchar(g * 0.5 + 1);float r = (float)dstimg.at<Vec3b>(h, w)[2];dstimg.at<Vec3b>(h, w)[2] = uchar(r * 0.5 + 1);}}}
OrtSessionOptionsAppendExecutionProvider_CUDA
/** This is the old way to add the CUDA provider to the session, please use SessionOptionsAppendExecutionProvider_CUDA above to access the latest functionality* This function always exists, but will only succeed if Onnxruntime was built with CUDA support and the CUDA provider shared library exists** \param device_id CUDA device id, starts from zero.
*/
ORT_API_STATUS(OrtSessionOptionsAppendExecutionProvider_CUDA, _In_ OrtSessionOptions* options, int device_id);
SessionOptionsAppendExecutionProvider_CUDA
-
https://github.com/microsoft/onnxruntime/blob/0fceb33288ce35472d1cbab24fd7d95d5d3c9b07/csharp/test/Microsoft.ML.OnnxRuntime.EndToEndTests.Capi/CXX_Api_Sample.cpp#L22
-
https://github.com/microsoft/onnxruntime/issues/3218
CG
ONNXRUNTUIME c++ on web
- 官方教程
-
镜像服务器设置:npm config set registry= https://registry.npm.taobao.org/
-
https://github.com/microsoft/onnxruntime-inference-examples
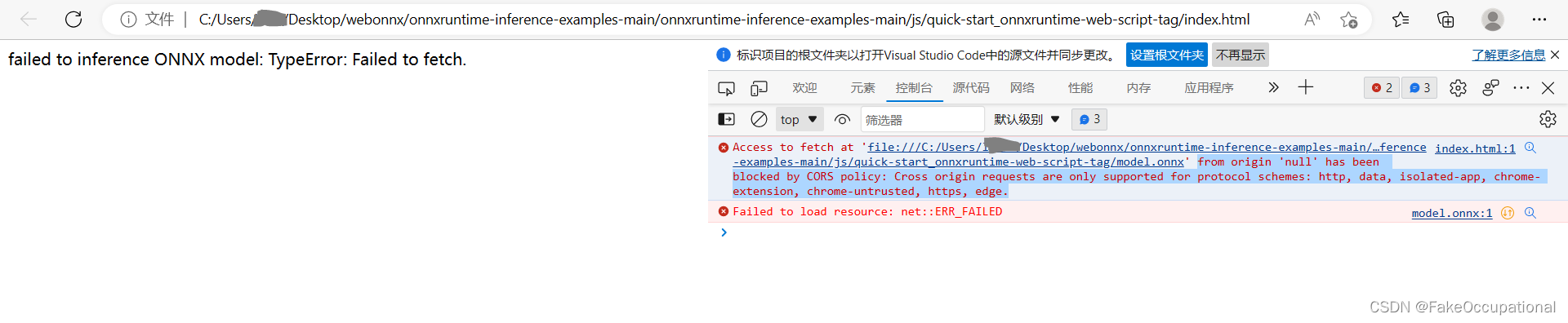
C:\Users\libai\Desktop\webonnx\onnxruntime-inference-examples-main\onnxruntime-inference-examples-main\js\quick-start_onnxruntime-web-script-tag
from origin ‘null’ has been blocked by CORS policy: Cross origin requests are only supported for protocol schemes: http, data, isolated-app, chrome-extension, chrome-untrusted, https, edge.